!pip install git+https://github.com/ECLIPSE-Lab/Ai4MatLectures.git "mdsdata>=0.1.5"MFML Week 3: Regression from Scratch
Loss minimization with TensileTestDataset
![]()
Learning Objectives
- Instantiate a
torch.utils.data.DatasetandDataLoader - Define a linear model as
nn.Module - Implement a manual training loop (MSE loss, SGD optimizer)
Setup
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, random_split
from ai4mat.datasets import TensileTestDataset
import matplotlib.pyplot as plt1. Load the Data
dataset = TensileTestDataset(temperature=600)
print(f"Dataset size: {len(dataset)}")
x0, y0 = dataset[0]
print(f"Sample x (strain): {x0}, shape: {x0.shape}")
print(f"Sample y (stress): {y0:.2f} MPa")Dataset size: 350
Sample x (strain): tensor([0.0001]), shape: torch.Size([1])
Sample y (stress): -0.13 MPaX_all = torch.stack([dataset[i][0] for i in range(len(dataset))]).squeeze()
y_all = torch.stack([dataset[i][1] for i in range(len(dataset))])
plt.scatter(X_all.numpy(), y_all.numpy(), s=8, alpha=0.5)
plt.xlabel("Strain")
plt.ylabel("Stress (MPa)")
plt.title("Tensile Test Data (600°C)")
plt.tight_layout()
plt.show()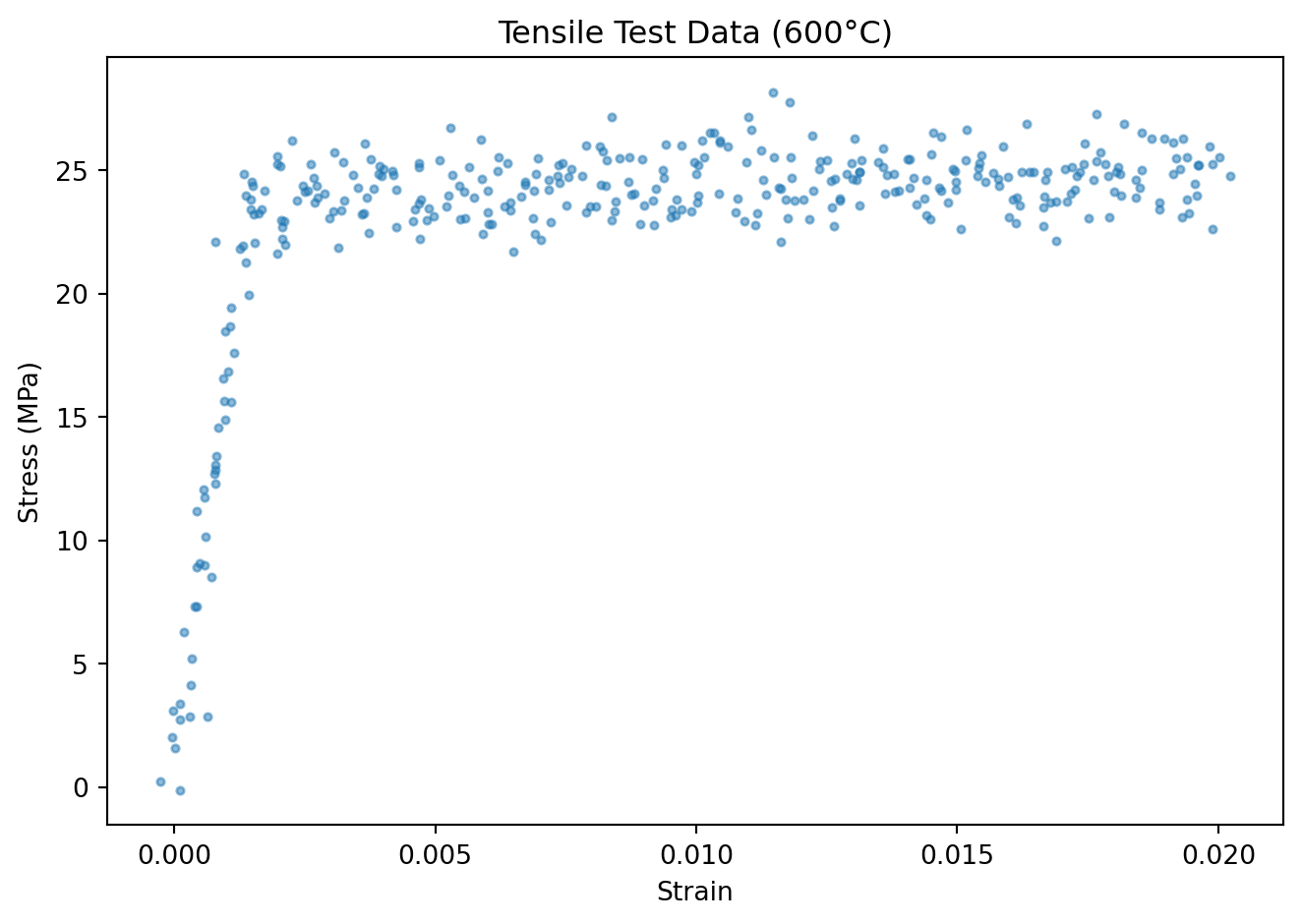
2. Train/Val Split
n_train = int(0.8 * len(dataset))
n_val = len(dataset) - n_train
train_ds, val_ds = random_split(dataset, [n_train, n_val])
train_loader = DataLoader(train_ds, batch_size=32, shuffle=True)
val_loader = DataLoader(val_ds, batch_size=32, shuffle=False)
print(f"Train: {n_train} | Val: {n_val}")Train: 280 | Val: 703. Define the Model
class LinearModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
return self.linear(x).squeeze(-1)
model = LinearModel()
print(model)
print(f"Parameters: {sum(p.numel() for p in model.parameters())}")LinearModel(
(linear): Linear(in_features=1, out_features=1, bias=True)
)
Parameters: 24. Training Loop
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4)
train_losses, val_losses = [], []
for epoch in range(100):
model.train()
epoch_loss = 0.0
for x_batch, y_batch in train_loader:
optimizer.zero_grad()
y_pred = model(x_batch)
loss = criterion(y_pred, y_batch)
loss.backward()
optimizer.step()
epoch_loss += loss.item() * len(x_batch)
train_losses.append(epoch_loss / n_train)
model.eval()
val_loss = 0.0
with torch.no_grad():
for x_batch, y_batch in val_loader:
y_pred = model(x_batch)
val_loss += criterion(y_pred, y_batch).item() * len(x_batch)
val_losses.append(val_loss / n_val)
plt.plot(train_losses, label='Train MSE')
plt.plot(val_losses, label='Val MSE')
plt.xlabel("Epoch")
plt.ylabel("MSE Loss")
plt.legend()
plt.title("Training Curve")
plt.tight_layout()
plt.show()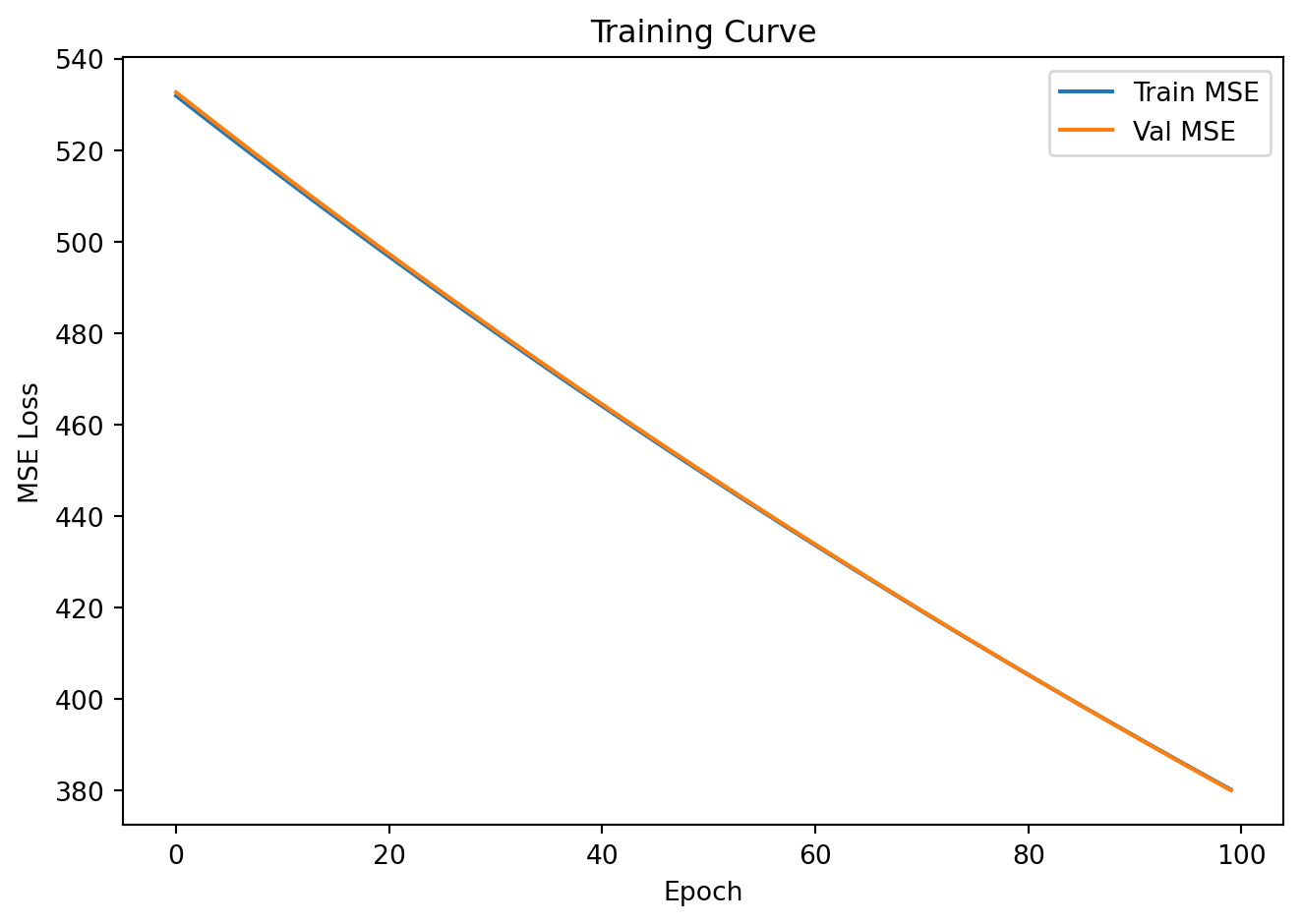
5. Evaluation
model.eval()
with torch.no_grad():
X_tensor = torch.stack([dataset[i][0] for i in range(len(dataset))])
y_pred_all = model(X_tensor).numpy()
order = X_all.numpy().argsort()
plt.scatter(X_all.numpy(), y_all.numpy(), s=8, alpha=0.3, label='Data')
plt.plot(X_all.numpy()[order], y_pred_all[order], color='red', label='Linear fit')
plt.xlabel("Strain")
plt.ylabel("Stress (MPa)")
plt.legend()
plt.title("Linear Model Fit")
plt.tight_layout()
plt.show()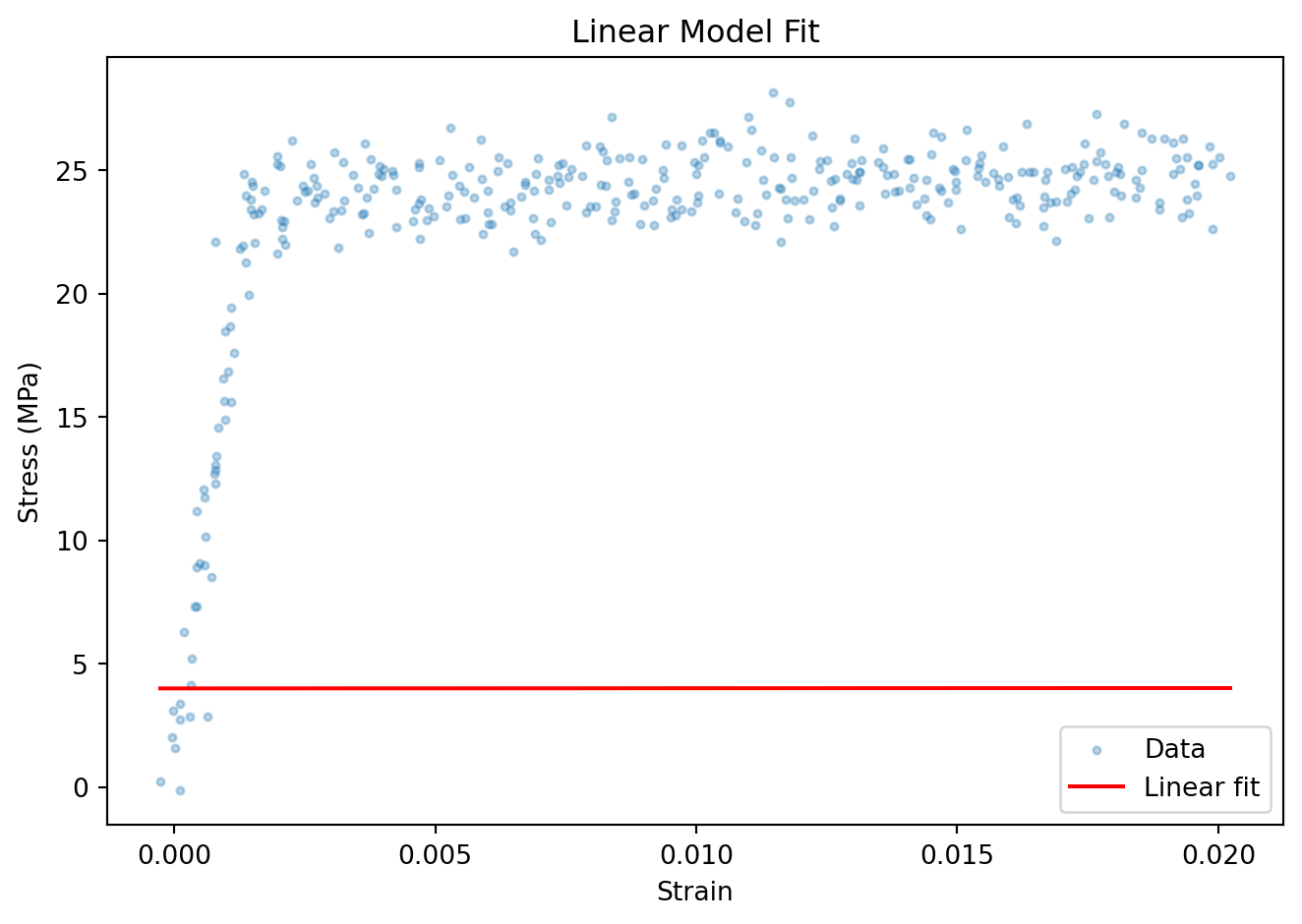
Exercises
- Change
temperatureto0or400inTensileTestDataset. How does the curve shape change? Does linear regression still work well? - Replace
LinearModelwith a 2-layer MLP:nn.Sequential(nn.Linear(1,16), nn.ReLU(), nn.Linear(16,1)). Does the fit improve? - Increase the learning rate to
1e-3. What happens to training? What does this tell you about loss landscape conditioning?