!pip install git+https://github.com/ECLIPSE-Lab/Ai4MatLectures.git "mdsdata>=0.1.5"MLPC Week 7: MLP Surrogate for Process Monitoring
Predicting stress from strain with TensileTestDataset
![]()
Learning Objectives
- Frame regression as surrogate modeling for process monitoring
- Train and compare MLP models across different process conditions
- Understand why models trained on one condition fail on another
Setup
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, random_split
from ai4mat.datasets import TensileTestDataset
import matplotlib.pyplot as plt
import numpy as np1. Load the Data
The TensileTestDataset simulates a process monitoring scenario: given a measured strain value, predict the resulting stress. Each temperature is a different process condition.
temperatures = [0, 400, 600]
datasets = {T: TensileTestDataset(temperature=T) for T in temperatures}
for T, ds in datasets.items():
x0, y0 = ds[0]
print(f"T={T:3d}°C | size: {len(ds):4d} | x: {x0.shape} | y range: [{min(ds[i][1].item() for i in range(len(ds))):.1f}, {max(ds[i][1].item() for i in range(len(ds))):.1f}] MPa")T= 0°C | size: 350 | x: torch.Size([1]) | y range: [-0.0, 68.4] MPa
T=400°C | size: 350 | x: torch.Size([1]) | y range: [-0.1, 54.4] MPa
T=600°C | size: 350 | x: torch.Size([1]) | y range: [-0.1, 28.1] MPafig, ax = plt.subplots(figsize=(8, 5))
colors_T = {0: 'tab:blue', 400: 'tab:orange', 600: 'tab:red'}
for T, ds in datasets.items():
X = torch.stack([ds[i][0] for i in range(len(ds))]).squeeze().numpy()
y = torch.stack([ds[i][1] for i in range(len(ds))]).numpy()
order = X.argsort()
ax.scatter(X, y, s=8, alpha=0.3, color=colors_T[T])
ax.plot(X[order], y[order], color=colors_T[T], label=f"T={T}°C", lw=1.5)
ax.set_xlabel("Strain")
ax.set_ylabel("Stress (MPa)")
ax.set_title("Stress-Strain Curves at Three Temperatures")
ax.legend()
plt.tight_layout()
plt.show()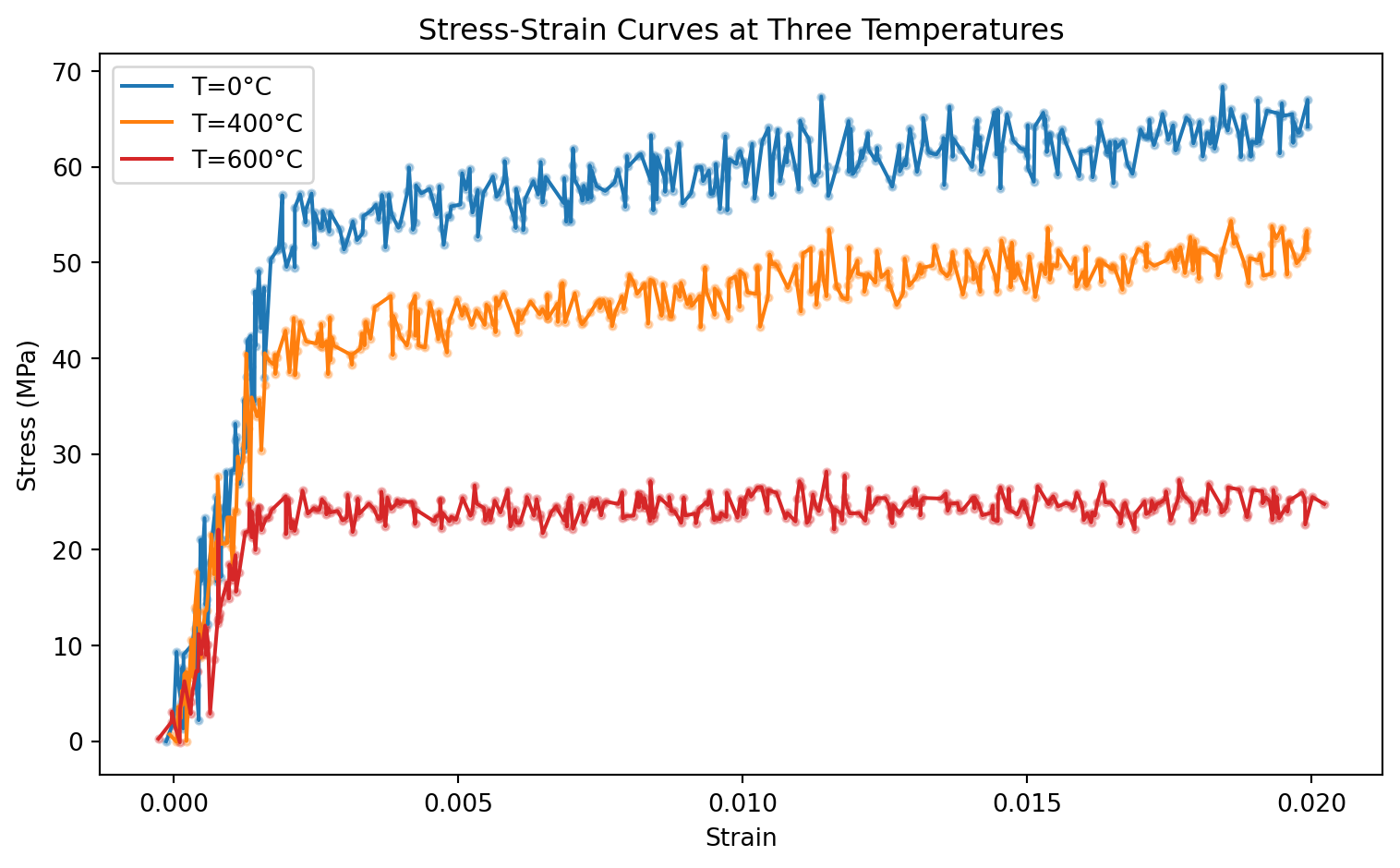
2. Train/Val Split
splits = {}
loaders = {}
for T, ds in datasets.items():
n_train = int(0.8 * len(ds))
n_val = len(ds) - n_train
train_ds, val_ds = random_split(ds, [n_train, n_val])
splits[T] = (n_train, n_val, train_ds, val_ds)
loaders[T] = {
'train': DataLoader(train_ds, batch_size=32, shuffle=True),
'val': DataLoader(val_ds, batch_size=32, shuffle=False)
}
print(f"T={T}°C: train={n_train}, val={n_val}")T=0°C: train=280, val=70
T=400°C: train=280, val=70
T=600°C: train=280, val=703. Define the Model
def make_mlp():
return nn.Sequential(
nn.Linear(1, 32), nn.ReLU(),
nn.Linear(32, 16), nn.ReLU(),
nn.Linear(16, 1)
)
model_test = make_mlp()
print(model_test)
print(f"Parameters: {sum(p.numel() for p in model_test.parameters())}")Sequential(
(0): Linear(in_features=1, out_features=32, bias=True)
(1): ReLU()
(2): Linear(in_features=32, out_features=16, bias=True)
(3): ReLU()
(4): Linear(in_features=16, out_features=1, bias=True)
)
Parameters: 6094. Training Loop
def train_regression(model, train_loader, val_loader, n_train, n_val, epochs=100, lr=1e-3):
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
train_losses, val_losses = [], []
for epoch in range(epochs):
model.train()
ep_loss = 0.0
for x_batch, y_batch in train_loader:
optimizer.zero_grad()
y_pred = model(x_batch).squeeze(-1)
loss = criterion(y_pred, y_batch)
loss.backward()
optimizer.step()
ep_loss += loss.item() * len(x_batch)
train_losses.append(ep_loss / n_train)
model.eval()
v_loss = 0.0
with torch.no_grad():
for x_batch, y_batch in val_loader:
y_pred = model(x_batch).squeeze(-1)
v_loss += criterion(y_pred, y_batch).item() * len(x_batch)
val_losses.append(v_loss / n_val)
return train_losses, val_losses
models = {}
torch.manual_seed(0)
for T in temperatures:
n_train, n_val, train_ds, val_ds = splits[T]
m = make_mlp()
tl, vl = train_regression(m, loaders[T]['train'], loaders[T]['val'], n_train, n_val)
models[T] = m
print(f"T={T}°C | final val MSE: {vl[-1]:.2f}")T=0°C | final val MSE: 180.06
T=400°C | final val MSE: 89.87
T=600°C | final val MSE: 30.545. Evaluation
# Compare predictions for all three temperatures in one figure
fig, ax = plt.subplots(figsize=(9, 6))
for T, ds in datasets.items():
X = torch.stack([ds[i][0] for i in range(len(ds))])
y_true = torch.stack([ds[i][1] for i in range(len(ds))]).numpy()
X_sq = X.squeeze().numpy()
order = X_sq.argsort()
models[T].eval()
with torch.no_grad():
y_pred = models[T](X).squeeze(-1).numpy()
ax.scatter(X_sq, y_true, s=6, alpha=0.2, color=colors_T[T])
ax.plot(X_sq[order], y_pred[order], color=colors_T[T], lw=2, label=f"MLP fit T={T}°C")
ax.set_xlabel("Strain"); ax.set_ylabel("Stress (MPa)")
ax.set_title("MLP Surrogate Model — All Temperatures")
ax.legend(); plt.tight_layout(); plt.show()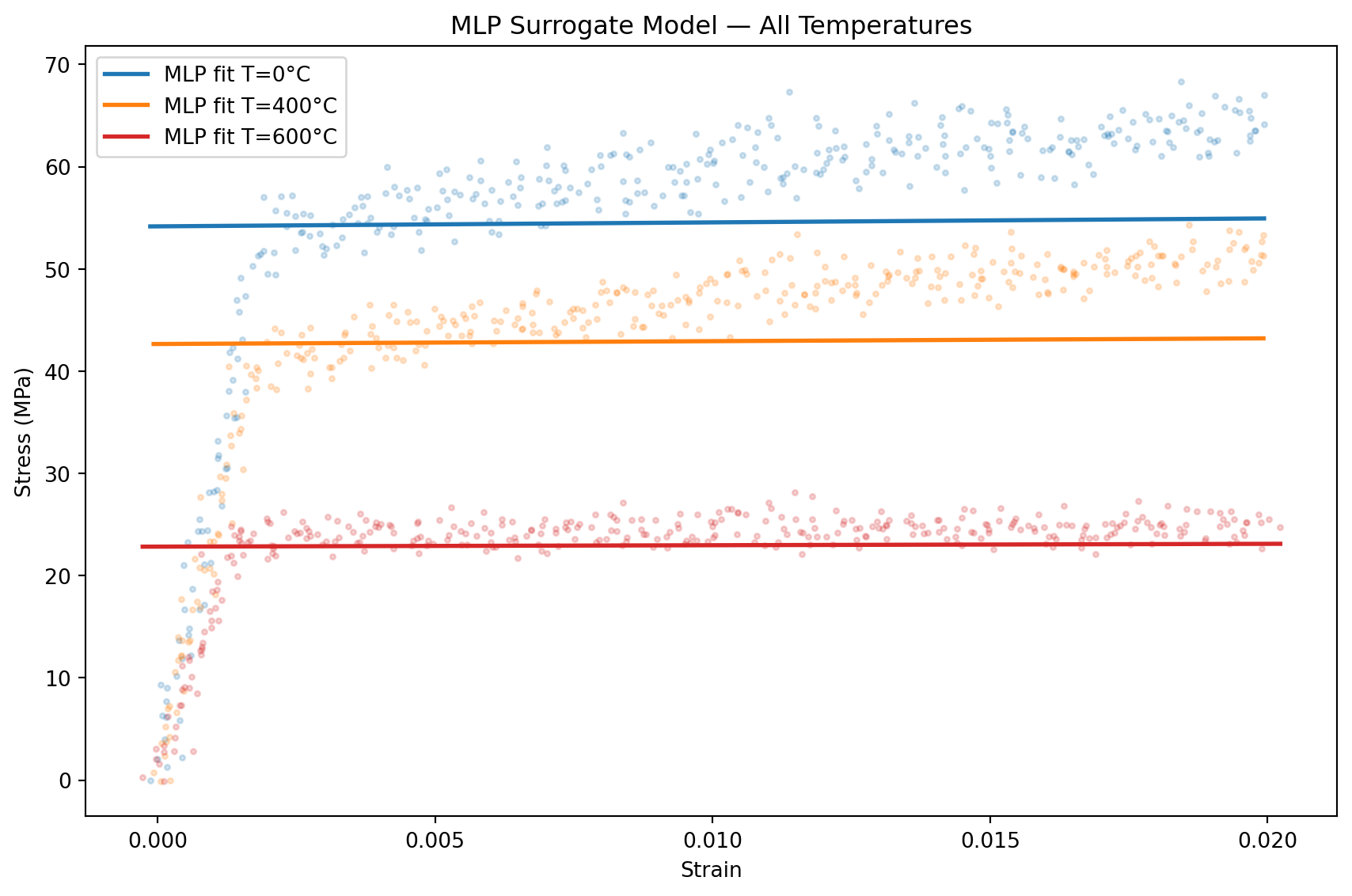
# Cross-temperature generalization: train on T=0, test on T=600
print("Cross-temperature test: train on T=0, evaluate on T=600")
n_train_0, n_val_0, _, _ = splits[0]
ds_600 = datasets[600]
X_600 = torch.stack([ds_600[i][0] for i in range(len(ds_600))])
y_600 = torch.stack([ds_600[i][1] for i in range(len(ds_600))])
models[0].eval()
with torch.no_grad():
y_pred_600 = models[0](X_600).squeeze(-1)
mse_cross = nn.MSELoss()(y_pred_600, y_600).item()
mse_same = nn.MSELoss()(
models[600](X_600).squeeze(-1), y_600
).item()
print(f" MSE (model_T=0 → data_T=600): {mse_cross:.2f}")
print(f" MSE (model_T=600 → data_T=600): {mse_same:.2f}")
print(f" Ratio: {mse_cross / mse_same:.1f}x worse")
print("\nConclusion: a model trained on one temperature does NOT generalize")
print("to another — the stress-strain relationship changes fundamentally.")Cross-temperature test: train on T=0, evaluate on T=600
MSE (model_T=0 → data_T=600): 1027.78
MSE (model_T=600 → data_T=600): 24.52
Ratio: 41.9x worse
Conclusion: a model trained on one temperature does NOT generalize
to another — the stress-strain relationship changes fundamentally.Exercises
- Train a model on
T=0data and evaluate it onT=600. Visualize the prediction error — where does the model fail most? Why? - Can a single model handle all temperatures if temperature is an additional input? Build
nn.Sequential(nn.Linear(2, 32), ...)and train on all three datasets combined (append temperature as a second input feature). - For uncertainty quantification, one approach is to predict both mean and variance. Change the output to 2 neurons and use a Gaussian NLL loss:
nn.GaussianNLLLoss(). What changes in the training loop?