Data Science for Electron Microscopy
Lecture 3: Convolutional Neural Networks




Invariance in Object Detection
Key Concept
- Recognition should not depend on precise object location
- Illustrated by “Where’s Waldo” game
- Waldo’s appearance independent of location
- Sweep image with detector for likelihood scores

An image of the “Where’s Waldo” game.
Channels in CNNs
Key Concepts
- Images: 3 channels (RGB)
- Third-order tensors: height × width × channel
- Convolutional filter adapts: \([\mathsf{V}]_{a,b,c}\)
- Hidden representations: third-order tensors \(\mathsf{H}\)
- Feature maps: spatialized learned features

Detect Waldo.
Convolutions for Images
The Cross-Correlation Operation
Key Points
- Convolutional layers actually perform cross-correlation
- Input tensor and kernel tensor combined
- Window slides across input tensor
- Elementwise multiplication and summation

Two-dimensional cross-correlation operation
Feature Maps and Receptive Fields
Concepts
- Feature map: learned spatial representations
- Receptive field: elements affecting calculation
- Can be larger than input size
- Deeper networks for larger receptive fields

Figure from Field (1987): Coding with six different channels
Padding
Key Concepts
- Add extra pixels around boundary
- Typically zero padding
- Preserve spatial dimensions
- Common with odd kernel sizes

Pixel utilization for different convolution sizes
Stride
Key Points
- Move window more than one element
- Skip intermediate locations
- Useful for large kernels
- Control output resolution

Cross-correlation with strides of 3 and 2
\(1\times 1\) Convolutional Layer
Key Points
- No spatial correlation
- Channel dimension computation
- Linear combination at each position
- Fully connected layer per pixel
\(1\times 1\) convolution with 3 input and 2 output channels
Maximum and Average Pooling
Key Concepts
- Fixed-shape window
- No parameters
- Deterministic operations
- Maximum or average value

Max-pooling with \(2\times 2\) window
Feature Learning in CNNs
Layer Progression
- Lowest layers: edges, colors, textures
- Analogous to animal visual system
- Automatic feature design
- Modern CNNs revolutionized approach

Image filters learned by AlexNet’s first layer
VGG Network Architecture
Two Main Parts
- Convolutional and pooling layers
- Fully connected layers (like AlexNet)
Key Difference
- Convolutional layers grouped in blocks
- Nonlinear transformations
- Resolution reduction steps

NiN Architecture
Key Differences from VGG
- Applies fully connected layer at each pixel
- Uses 1×1 convolutions after initial convolution
- Eliminates need for large fully connected layers

DenseNet Architecture
Key Components
- Dense blocks
- Transition layers
- Concatenation operation
- Feature reuse

DenseNet Implementation
class DenseBlock(nn.Module):
def __init__(self, num_convs, num_channels):
super(DenseBlock, self).__init__()
layer = []
for i in range(num_convs):
layer.append(conv_block(num_channels))
self.net = nn.Sequential(*layer)
def forward(self, X):
for blk in self.net:
Y = blk(X)
X = torch.cat((X, Y), dim=1)
return XU-Net Architecture
Key Features
- Originally for biomedical image segmentation
- Symmetric encoder-decoder structure
- Skip connections
- Works with limited training data
- Preserves spatial information
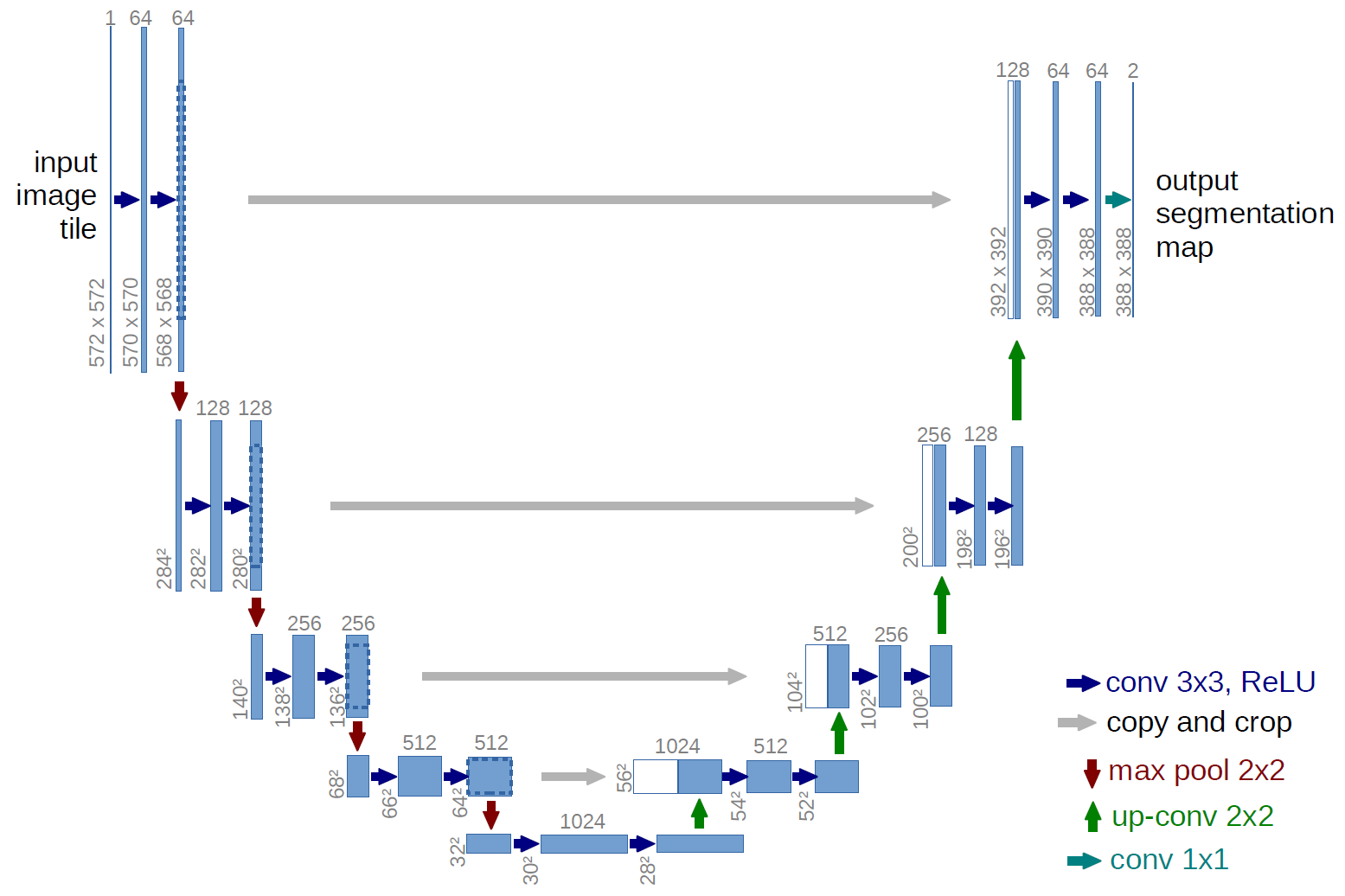
U-Net architecture