Mathematical Foundations of AI & ML
Unit 8: The Probabilistic View of Learning
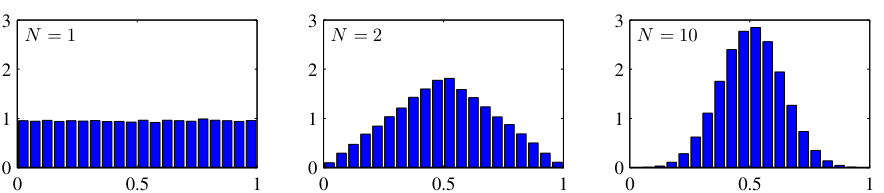
Central Limit Theorem connection
- The sum (or average) of many independent random variables converges to a Gaussian, regardless of their individual distributions.
- This explains why the Gaussian appears everywhere:
- Measurement errors = sum of many small independent perturbations.
- Aggregate quantities in materials science follow approximately Gaussian distributions.
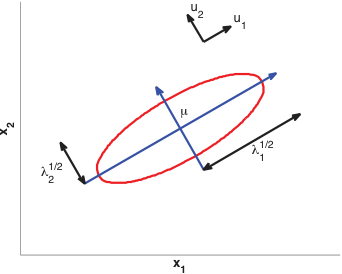
Multivariate Gaussian distribution
\[ p(\mathbf{x} \mid \boldsymbol{\mu}, \boldsymbol{\Sigma}) = (2\pi)^{-d/2} |\boldsymbol{\Sigma}|^{-1/2} \exp\!\left(-\frac{1}{2}(\mathbf{x}-\boldsymbol{\mu})^\top \boldsymbol{\Sigma}^{-1}(\mathbf{x}-\boldsymbol{\mu})\right) \]
- \(\boldsymbol{\mu} \in \mathbb{R}^d\): mean vector. \(\boldsymbol{\Sigma} \in \mathbb{R}^{d \times d}\): covariance matrix (symmetric, positive definite).
- Level sets are ellipsoids whose axes align with eigenvectors of \(\boldsymbol{\Sigma}\).
- Eigenvectors \(\mathbf{u}_i\) give the ellipse orientation; eigenvalues \(\lambda_i\) give the axis lengths \(\lambda_i^{1/2}\).
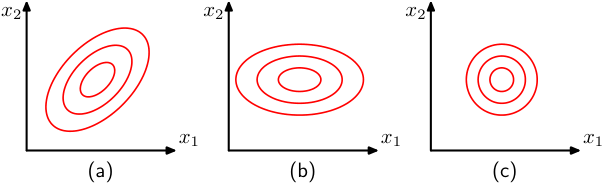
Covariance matrix: diagonal vs full
- Diagonal \(\boldsymbol{\Sigma}\): features are uncorrelated; ellipsoids are axis-aligned.
- Full \(\boldsymbol{\Sigma}\): features are correlated; ellipsoids are rotated.
- Spherical (\(\boldsymbol{\Sigma} = \sigma^2 \mathbf{I}\)): isotropic; level sets are spheres.
- The eigenvalues of \(\boldsymbol{\Sigma}\) determine the extent along each principal axis.
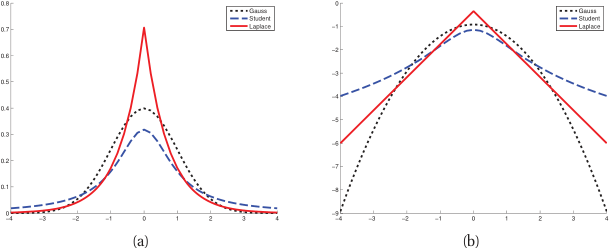
Student’s t-distribution for robust estimation
- The Student’s t-distribution has a parameter \(\nu\) (degrees of freedom) controlling tail heaviness.
- \(\nu \to \infty\): converges to Gaussian. \(\nu = 1\): Cauchy distribution (very heavy tails).
- MLE with Student’s t automatically downweights outliers.
- Practical recommendation: use \(\nu \approx 4{-}10\) for moderate robustness [@murphy2012machine].
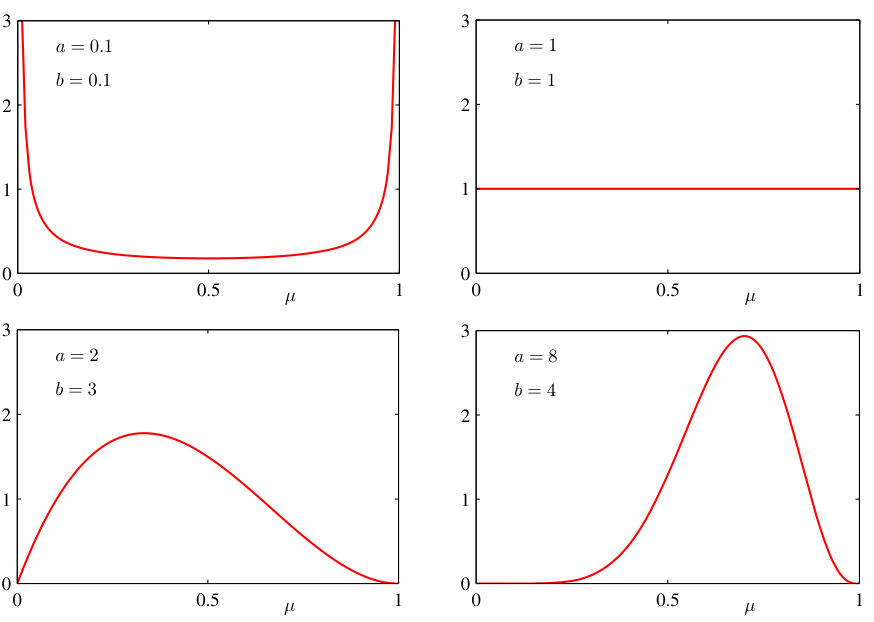
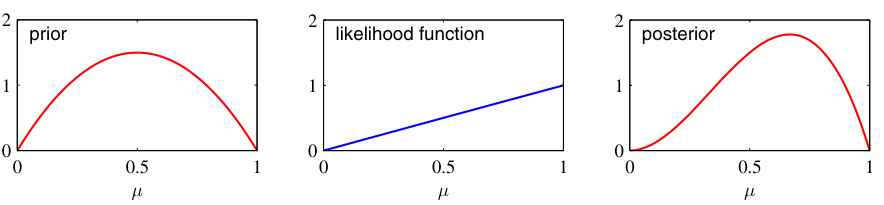
Components of Bayes’ theorem
- The prior encodes domain knowledge or assumptions (e.g., “weights should be small”).
- The likelihood is the same function used in MLE — it connects data to parameters \(\boldsymbol{\theta}\).
- The posterior combines both: it is a compromise between prior knowledge and data evidence.
- More data → posterior dominated by likelihood. Less data → posterior dominated by prior.
Bayesian inference for Gaussian mean (known variance)
- Prior: \(\mu \sim \mathcal{N}(\mu_0, \sigma_0^2)\).
- Likelihood: \(x_i | \mu \sim \mathcal{N}(\mu, \sigma^2)\) (known \(\sigma^2\)).
- Posterior: \(\mu | \mathcal{D} \sim \mathcal{N}(\mu_N, \sigma_N^2)\) where:
\[ \mu_N = \frac{\sigma^2 \mu_0 + N \sigma_0^2 \bar{x}}{\sigma^2 + N \sigma_0^2}, \quad \sigma_N^2 = \frac{\sigma^2 \sigma_0^2}{\sigma^2 + N \sigma_0^2} \]
- This is a conjugate pair: Gaussian prior + Gaussian likelihood = Gaussian posterior [@bishop2006pattern].
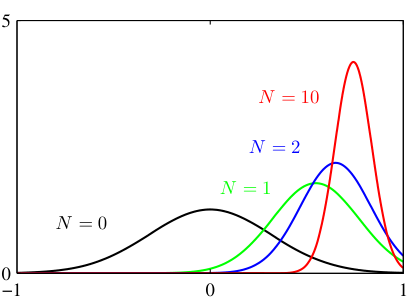
Posterior update: visual intuition
- Before data (\(N=0\)): posterior = prior (wide, uncertain).
- After a few points (\(N=2\)): posterior narrows, shifts toward sample mean.
- More data (\(N=10\)): posterior is very narrow, centered near \(\bar{x}\).
- As \(N \to \infty\): posterior concentrates at \(\hat{\mu}_{\text{MLE}}\) — the prior washes out.
Stochastic enrichment of input data
- Add Gaussian noise to training inputs to simulate measurement uncertainty:
- \(\tilde{x}_i = x_i + \epsilon\), \(\epsilon \sim \mathcal{N}(0, \sigma_{\text{noise}}^2)\).
- This augments the training set and makes the model robust to input perturbations.
- Especially effective when the noise level matches real deployment conditions [@neuer2024machine].
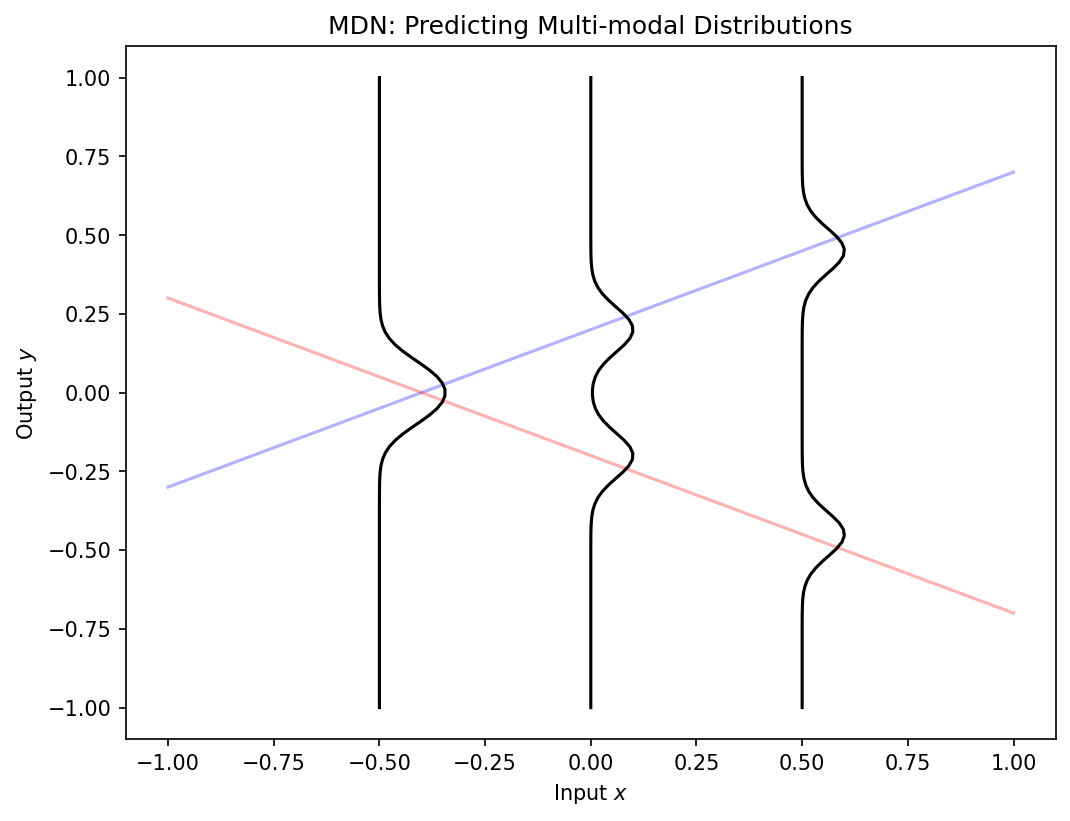
Mixture-density networks
- Standard networks predict a single value \(\hat{y}\) — they cannot express multi-modal uncertainty.
- A mixture-density network predicts the parameters of a Gaussian mixture:
\[ p(y|x) = \sum_{k=1}^{K} \pi_k(x) \, \mathcal{N}(y | \mu_k(x), \sigma_k^2(x)) \]
- Mixing coefficients \(\pi_k\), means \(\mu_k\), and variances \(\sigma_k^2\) are all functions of input \(x\) [@neuer2024machine].
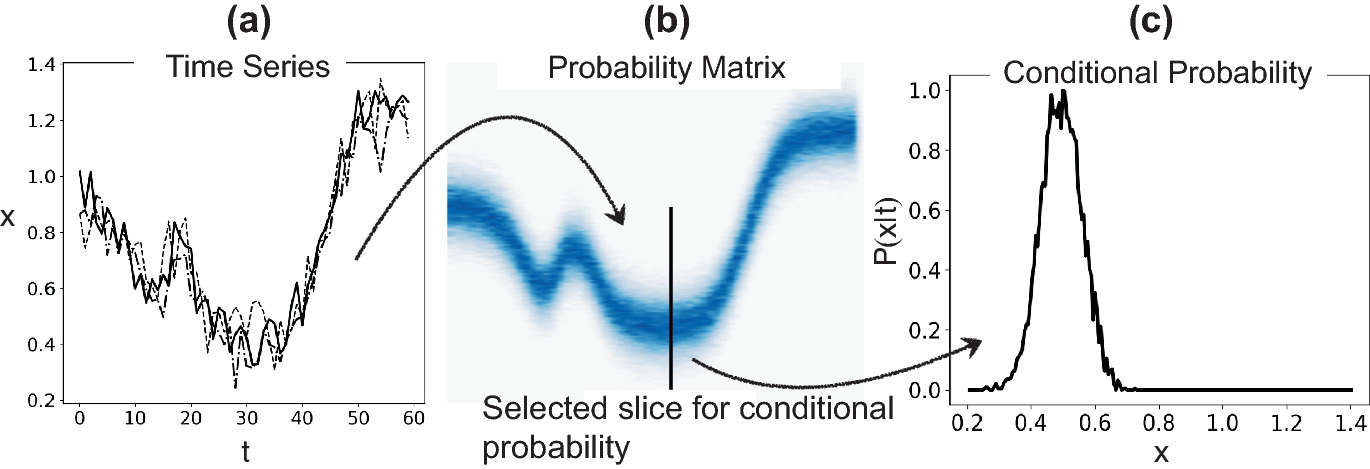
Process corridors via 2D histograms
- In manufacturing, define acceptable parameter ranges as probability contours.
- A 2D histogram of (process parameter, quality metric) shows the process corridor.
- Points outside the corridor flag anomalies or process drift.
- This converts probabilistic thinking into actionable quality control [@neuer2024machine].