Machine Learning in Materials Processing & Characterization
Unit 9: ML for Characterization Signals




06. The Pipeline — Garbage In Dominates Everything

- Every box is a physics-informed choice, not a default. Order matters (slide 04).
- The reduction/decomposition box is the referenced methods (PCA/AE/NMF) — it is one box, not the unit.
Important
The dominant error term in any spectral-ML result is almost never the model — it is the preprocessing. A 2% baseline error swamps the difference between PCA and a transformer. §2 is the unit’s real content because almost none of it exists in the methods units.
07. Baseline / Background Subtraction
Algorithmic (model-free)
- SNIP — Statistics-sensitive Nonlinear Iterative Peak-clipping (Ryan et al. 1988): iteratively clip each channel to the min of itself and the mean of its \(\pm m\) neighbours; peaks survive, the smooth continuum is estimated.
- Asymmetric Least Squares (AsLS) (Eilers and Boelens 2005): penalized smoother with asymmetric weights — points above the baseline are down-weighted. Two knobs: smoothness \(\lambda\), asymmetry \(p\).
Physical (model-based)
- EELS: power-law \(A E^{-r}\) in a pre-edge window, or a linear combination of power laws + local background averaging that pool spatial redundancy (Cueva et al. 2012).
- EDX: bremsstrahlung continuum (Kramers + detector response + absorption).
- XPS: Shirley / Tougaard inelastic background.
Important
A wrong background biases every downstream feature — peak areas, ratios, latent coordinates. It is a systematic, not random, error: averaging more spectra does not remove it.
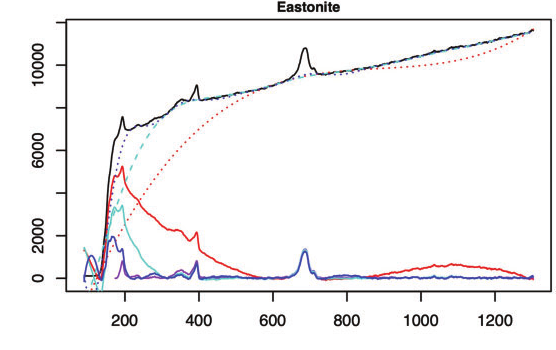
A real Raman spectrum (black) with a strong rising fluorescence background; several baseline estimates (dotted/dashed) and the resulting baseline-corrected spectra. Background subtraction is the measurement here, not housekeeping (Xu et al. 2021).
07a. EELS Background in the STEM — LCPL & Local Background Averaging

The STEM-specific problem. At atomic resolution and low dose, the power-law fit is itself dominated by Poisson noise — a noisy background becomes a systematic error in every extracted edge (slide 03).
- Linear combination of power laws (LCPL). One global \(E^{-r}\) is too rigid; a small basis of power laws captures curvature a single law misses.
- Local background averaging (LBA). Borrow background counts from spectrally-similar neighbours — the spectrum image is redundant, so averaging the background (not the signal) cuts its error without blurring the edge.
Important
Exploiting dataset redundancy improves background estimation and chemical sensitivity — the basis of the Cornell Spectrum Imager (Cueva et al. 2012). Better background craft, not a bigger model, is what lowers detection limits.
12. Spatial-Spectral Models for Spectrum Images
- A spectrum image is a cube \((x, y, E)\) — STEM-EDS easily \(256{\times}256{\times}2048\), STEM-EELS \(100{\times}100{\times}1024\).
- Naïve: unfold to \(N_\text{pix}\times D\), treat each pixel independently. Throws away that neighbouring pixels are almost the same spectrum.
- Better: exploit spatial correlation — factored 2-D spatial + 1-D spectral convolutions, or a 3-D conv-AE.
- Benefit: implicit spatial averaging denoises for free; spatial context separates interface pixels from bulk; learns core-shell / gradient structure.
Important
Trade-off. Spatial smoothing blurs sharp interfaces and can invent mixed spectra at boundaries — choose the receptive field to match the smallest real feature, not the noise.
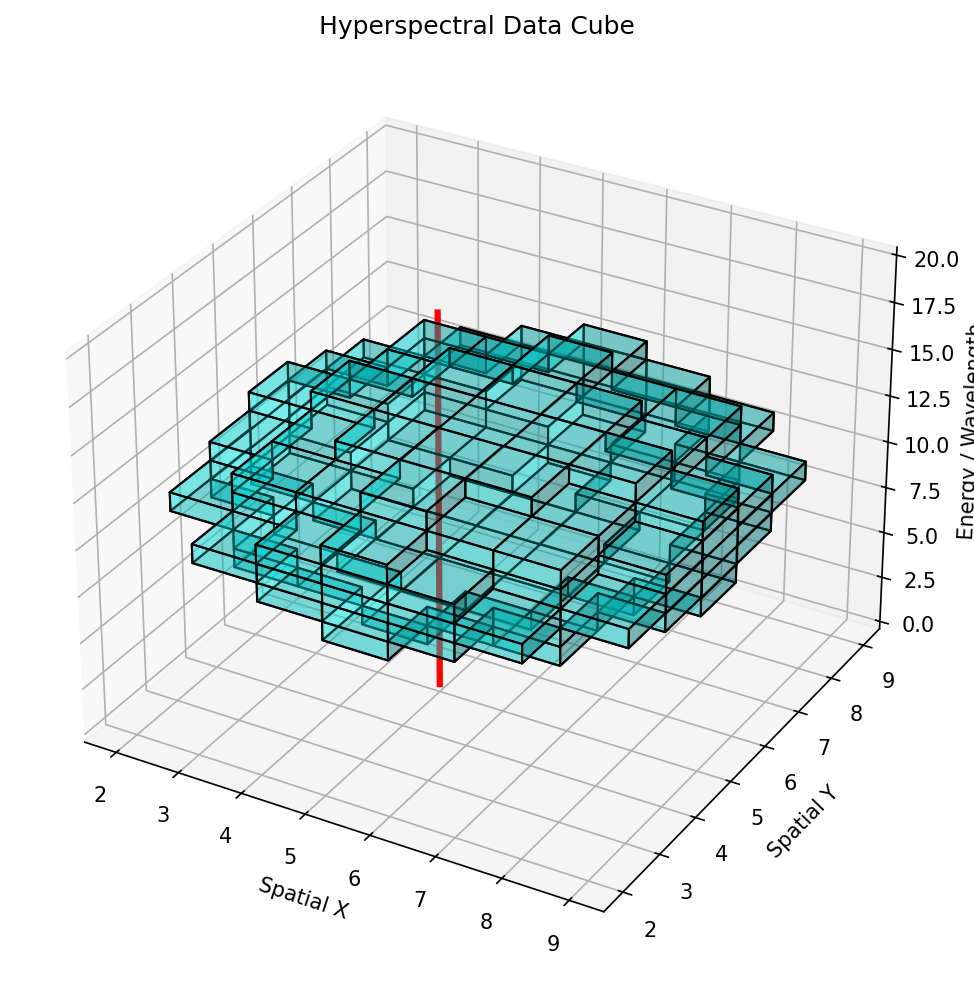
A spectrum image is an \((x,y,E)\) datacube — every pixel holds a full spectrum. Spatial-spectral models borrow strength from neighbouring (near-identical) pixels to denoise each spectrum.
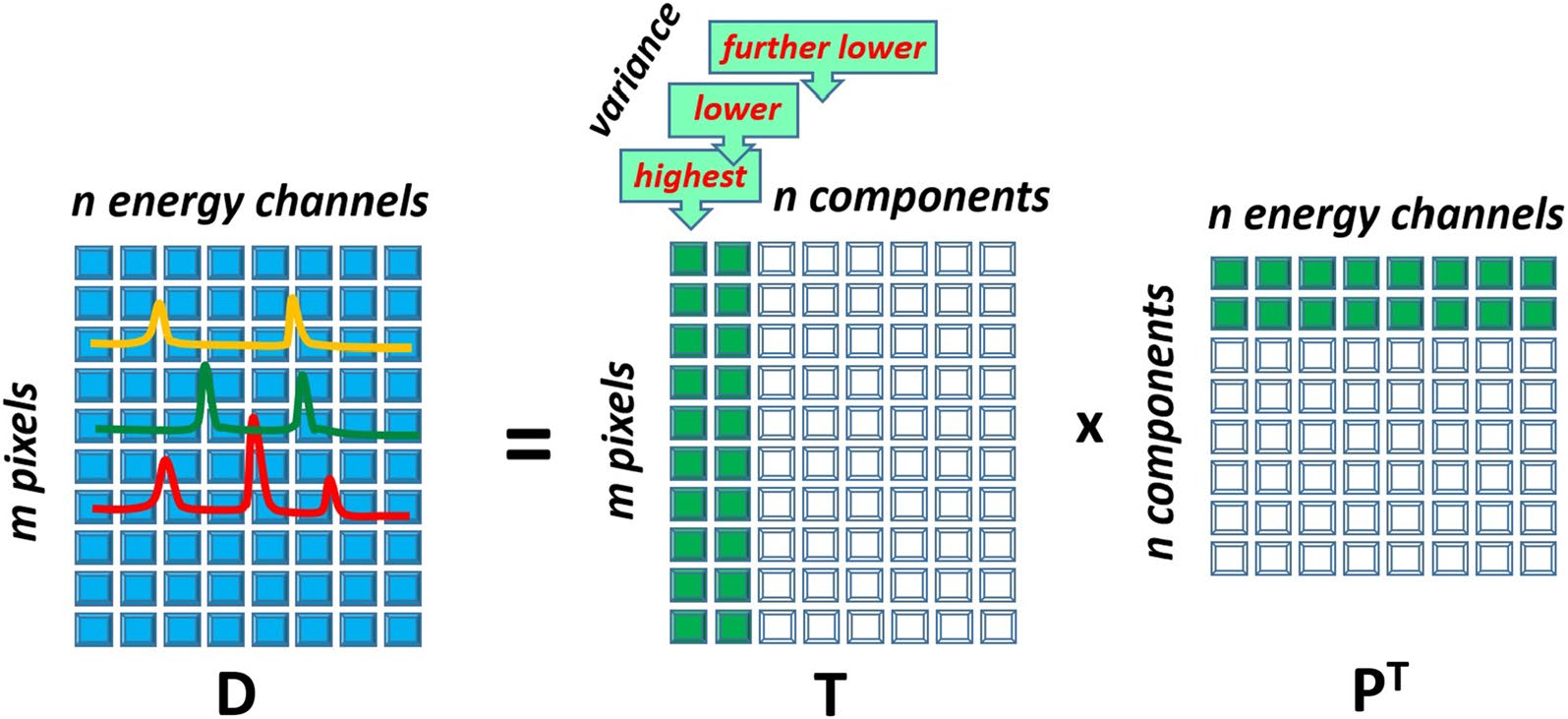
13. Reference Recap — Spectral Decomposition (one slide)
| Decomposition | Factorization | Spectral interpretation |
|---|---|---|
| PCA / SVD | \(\mathbf{X}\approx \bar{\mathbf{x}} + \mathbf{C}\mathbf{V}^\top\), \(\mathbf{V}\) orthonormal | Eigenspectra = orthogonal variation directions (can be negative — not physical phases) |
| NMF | \(\mathbf{X}\approx \mathbf{W}\mathbf{H}\), \(\mathbf{W},\mathbf{H}\ge 0\) | \(\mathbf{H}\) = end-member spectra (≈ pure phases), \(\mathbf{W}\) = abundance maps |
| AE / conv-AE | \(\mathbf{x}\!\to\!\mathbf{z}\!\to\!\hat{\mathbf{x}}\) | Non-linear latent; handles peak shift, not just mixing |
- The only thing this unit adds: the spectral reading — non-negativity is physical because photon counts and concentrations cannot be negative; orthogonality is a math convenience with no physical mandate.
13a. PCA of EELS Spectrum Images — Composition (Bosman et al. 2006)
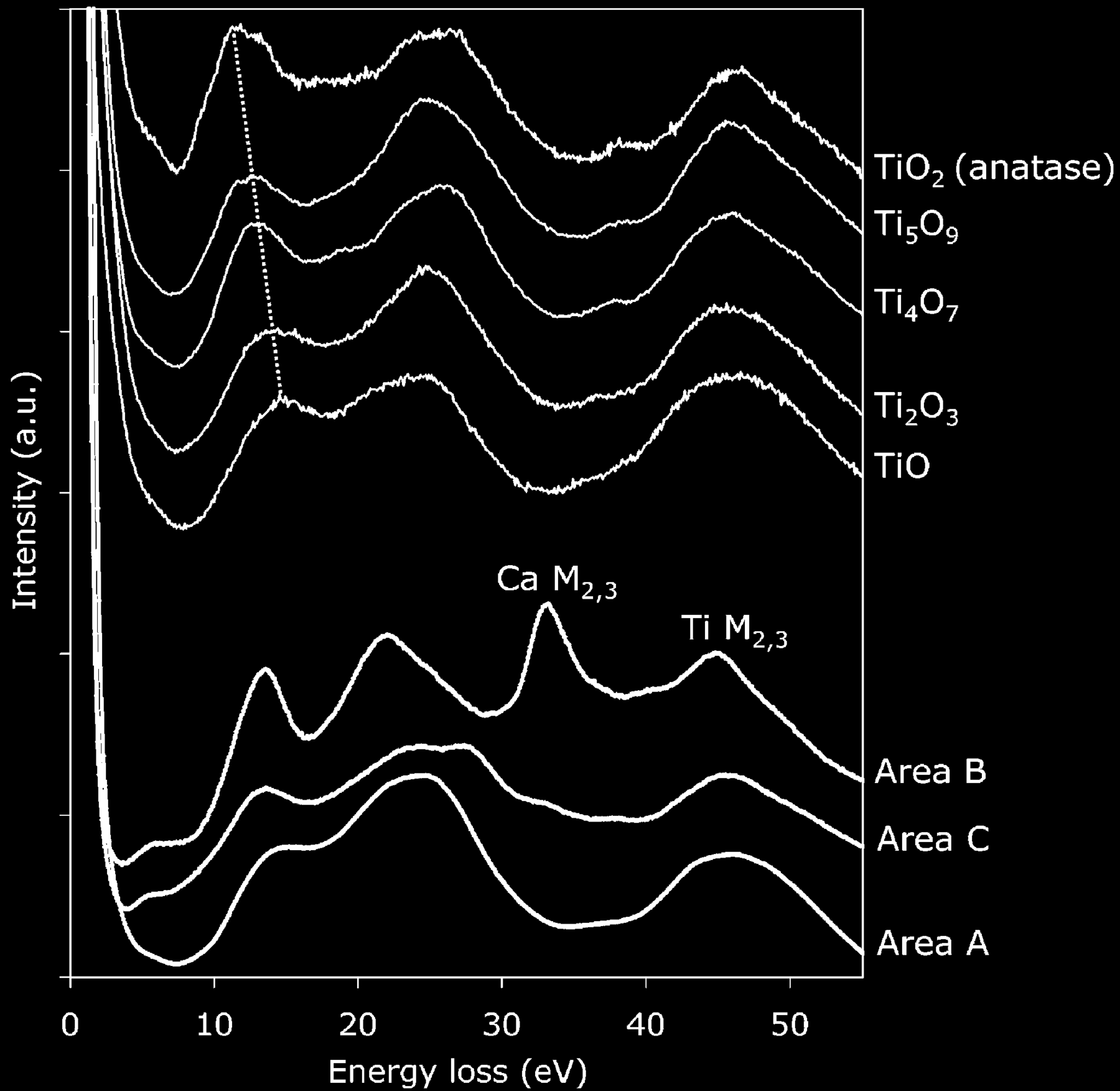
The seminal EM result. PCA of an EEL spectrum image extracts chemically relevant components — score maps localize phases, loadings are interpretable spectra (Bosman et al. 2006).
- Only a handful of phases → a few components carry the chemistry; the rest is noise (low intrinsic dimensionality, slide 03).
- Matching resolved area spectra to reference oxides assigns Ti valence (TiO, Ti₂O₃, Ti₄O₇, Ti₅O₉, TiO₂).
Note
This is slide 13’s PCA row in the STEM: the method is MFML u02; the reading of the loadings as chemistry is the materials content.
13b. Weighted PCA Recovers ELNES Bonding (Bosman et al. 2006)
Composition and bonding. With weighted / two-way-scaled PCA, the same decomposition recovers near-edge fine structure (ELNES) — bonding and orientation, not only which elements are present (Bosman et al. 2006).
- Why weight. Plain PCA weights channels by variance — under Poisson noise that means by intensity, so the background dominates. Scaling by the noise (variance-stabilizing) lets PCA see the weak edge.
Important
Get the weighting wrong and PCA “denoises” the bonding signal away. Weighting is not a detail — it decides whether the chemistry survives (slide 20a).
14a. MCR in the STEM — Unmixing EDS Spectrum Images (Kotula & Keenan 2006)

The EDS instantiation of slide 14. MCR applied to a raw STEM-EDS spectrum image returns a high-contrast set of component spectra + maps — no element-by-element windowing (Kotula and Keenan 2006).
- Each component is a non-negative spectrum (a phase) with a non-negative abundance map — the constraints are the physics (slide 13).
- Resolves overlapping lines (e.g. the Ga/Pt FIB artifact) into their own component instead of contaminating the chemistry.
Important
Sandia’s MSA-for-EM line of work is why MCR/PCA are the production default in EDS labs — decades before deep learning. Reach for a network only when these break (slide 24).
14b. Unmixing as Geometry — Endmembers & the Mixing Simplex (Dobigeon & Brun 2012)
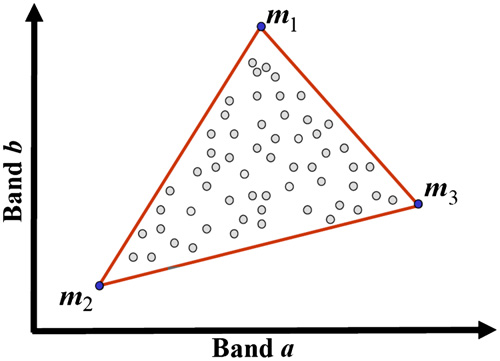
A geometric view of slide 14. Under linear mixing each spectrum is a convex combination of end-members → the data fill a simplex; its vertices are the pure phases.
- Closure (abundances sum to 1) is the simplex constraint; non-negativity keeps pixels inside it.
- This is the same geometry as the Gibbs triangle the autoencoder rediscovers on slide 21 — and the linear model slide 17 stress-tests.
Note
The endmember/abundance picture borrowed from hyperspectral remote sensing — spectroscopy’s cousin discipline. Same math, different photons.
17a. Bayesian Linear Unmixing of EELS Spectrum-Images (Dobigeon & Brun 2012)
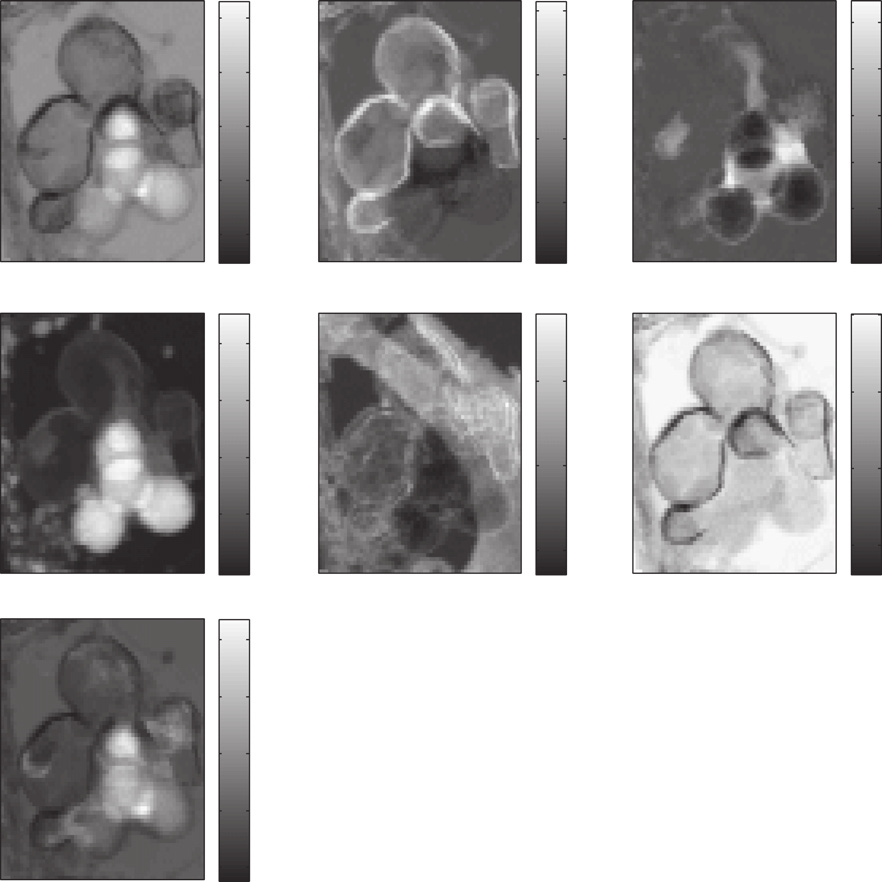
When PCA/ICA struggle. If end-member abundances are statistically dependent — the usual case in real maps — PCA/ICA unmix poorly. A Bayesian model with the simplex priors (slide 14b) estimates end-members + abundances and their uncertainty (Dobigeon and Brun 2012).
- Non-negativity and closure enter as priors, not post-hoc fixes.
- Returns posterior distributions → an error bar on every abundance (slide 16 discipline).
Important
A principled prior beats a generic decomposition when the physics (non-negativity, closure, dependence) is known. Encode the physics; don’t hope the SVD stumbles onto it.
18. Deep Denoising Autoencoders for EELS — the EM-Native Workhorse
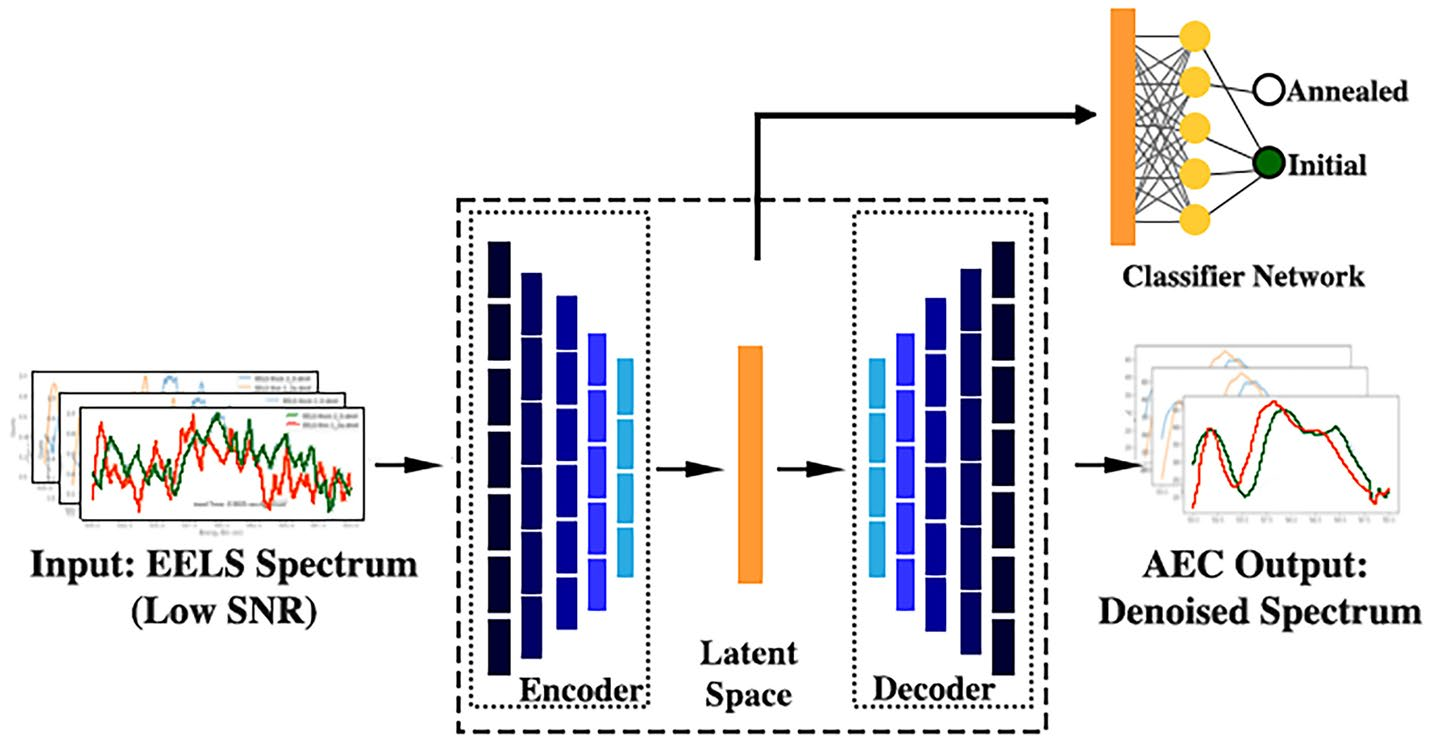
What the EM field actually deploys. Not a giant foundation model — a compact convolutional denoising autoencoder mapping noisy → clean spectra. RapidEELS (Pate et al. 2021) is the canonical case.
- 1-D conv encoder → small latent (≈5-D) → decoder → denoised spectrum.
- Train on simulated / paired clean–noisy spectra (slide 21); deploy at the column.
- The self-supervised / MAE extension (mask 75 %, reconstruct masked bins) is the generic recipe — method owned by MFML u09; add it when an unlabelled archive dwarfs the labels.
Note
The conv-DAE is the workhorse because it is small, fast, trainable on simulation, and auditable: it drops in as a preprocessing denoiser feeding the physical fit (slide 10), not an end-to-end black box.
18a. RapidEELS — Low-Dose Denoising at 25–400 FPS
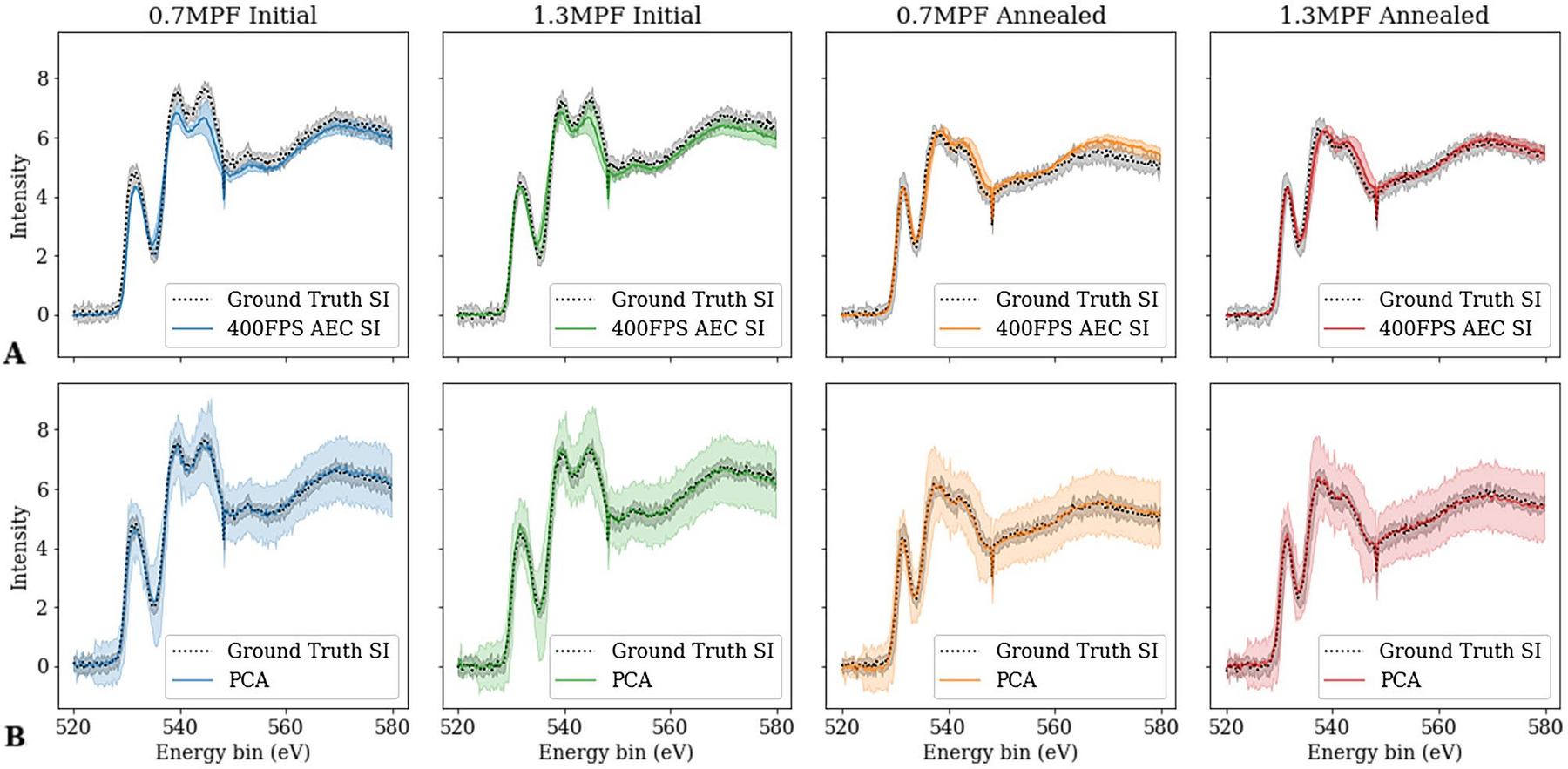
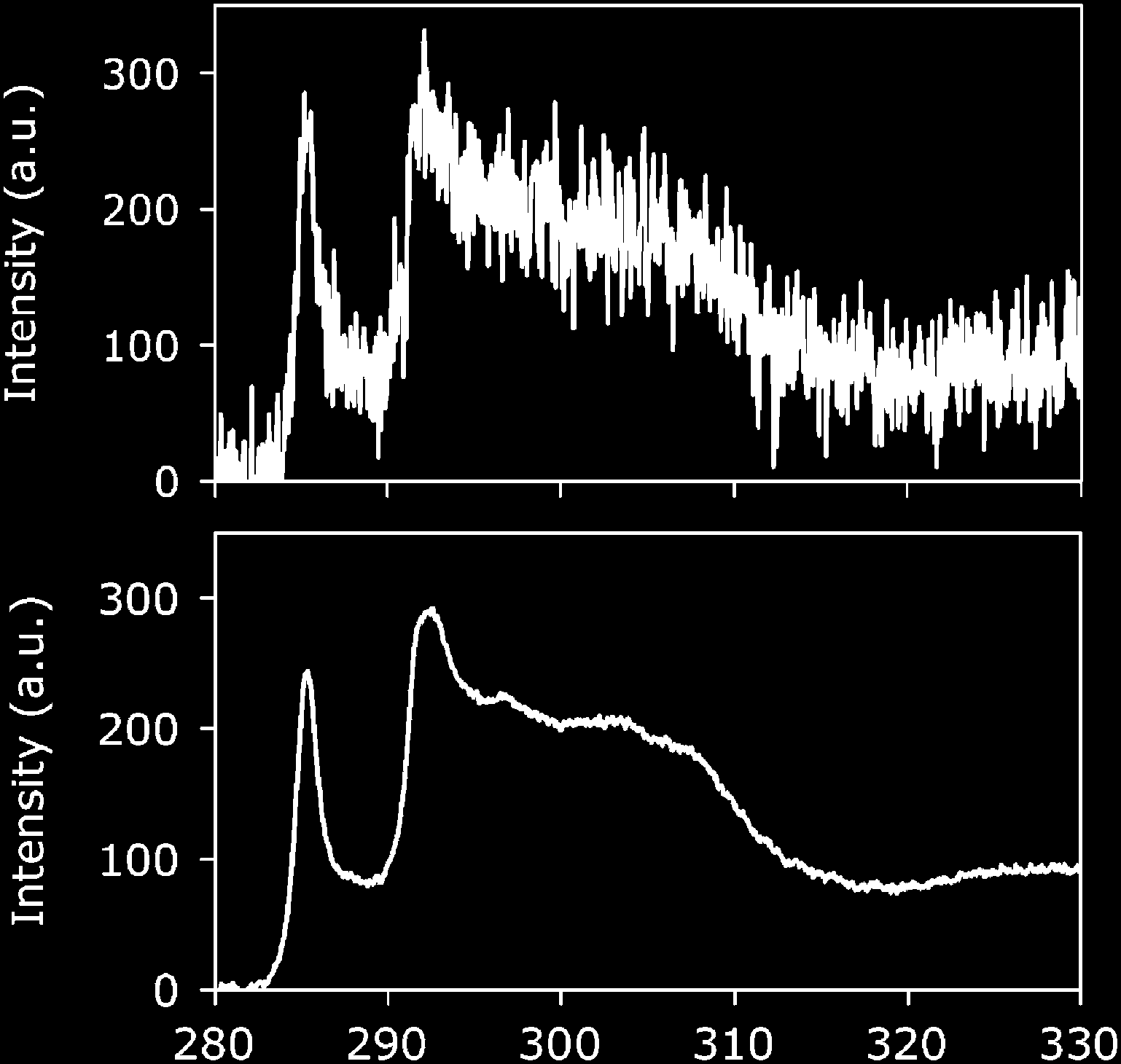
Denoised EELS at 25/100/200/400 FPS vs ground truth: the conv-DAE recovers the O-K / Fe-L edge shape even at ~15 counts/channel (shot-noise SNR ≈ 3.8), and beats 5- and 7-component PCA on fine-feature MSE (Pate et al. 2021).
- Dose, not method, is the constraint. At 400 FPS (0.0025 s dwell) the raw edge is buried in Poisson noise; the DAE restores a fittable edge.
- Beats PCA on fine-feature MSE (vs 5-/7-component) — the non-linearity helps where peak shape, not just intensity, carries the signal.
Important
Denoising here is a preprocessing step validated against ground truth (slide 10) — never a latent read as the answer (slide 17).
18b. From Latent to Oxidation State — Fe³⁺ vs Fe⁴⁺ (RapidEELS)
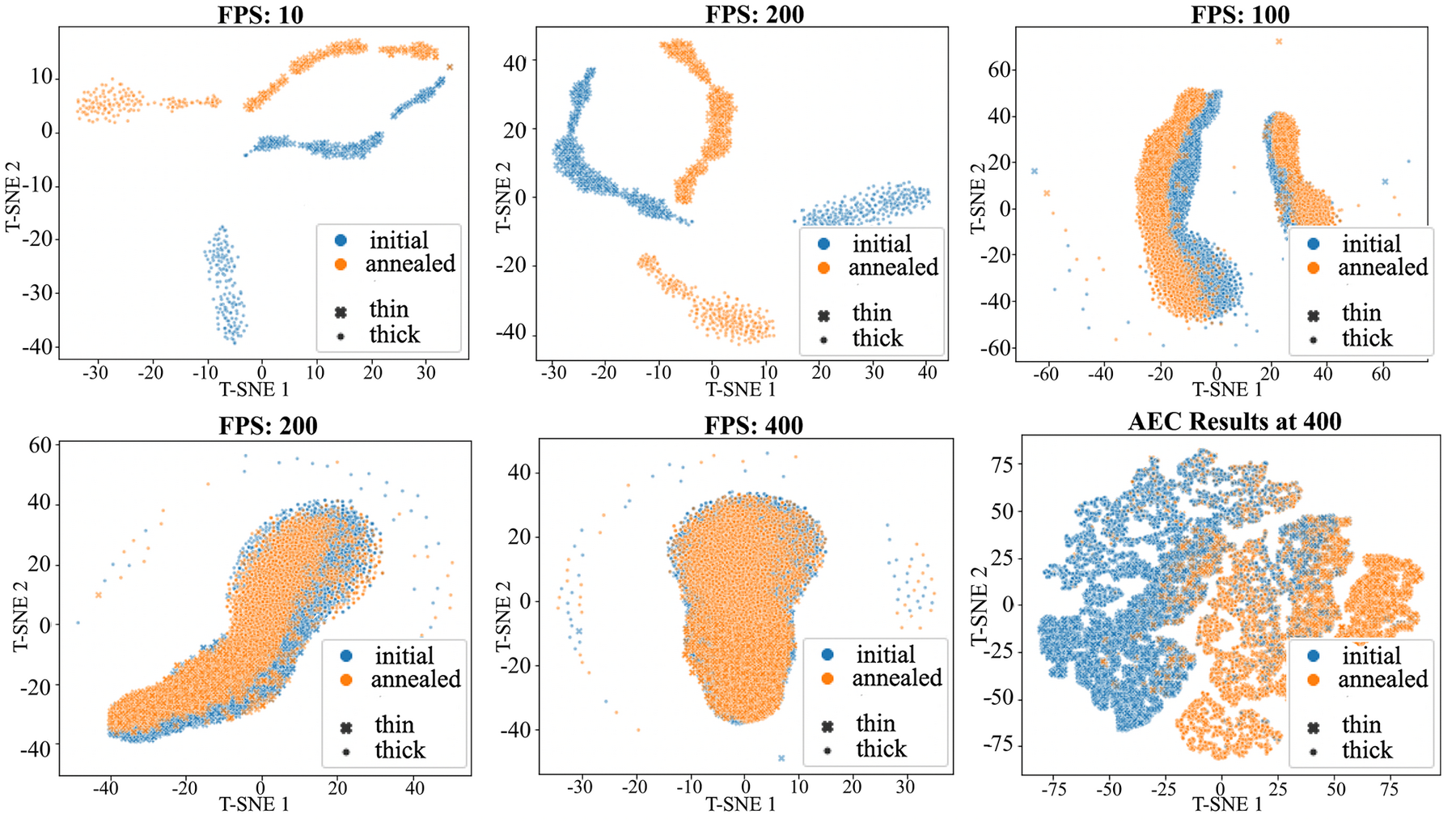
- Freeze the denoiser’s encoder; train a tiny classifier on the latent — the SSL “pretrain → probe” recipe (MFML u09), here on EELS.
- Accuracy degrades gracefully with dose: usable oxidation-state triage even at video rate.
Important
But a softmax class is not a calibrated valence. For the continuous mixed-valence gradient, read the fitted white-line ratio (slide 23), not the latent (slide 17). Classification is fast triage; the physical fit is the deliverable.
20a. Getting PCA Denoising Right — Weighting & Optimal Truncation

PCA denoising must be done right.
- Weight for Poisson noise before the SVD (variance-stabilizing) — otherwise high-count channels dominate and the weak signal is lost (slide 13b).
- Choose the truncation rank carefully: too few components erase real features, too many keep noise. Potapov & Lubk give an optimal truncation that beats ad-hoc scree-elbow choices (Potapov and Lubk 2019).

20b. When PCA Filtering Lies — Bias & Artifacts

The cautionary literature — take it seriously.
- Lichtert & Verbeeck (2013): PCA noise filtering introduces a significant bias in estimated parameters — precision can even beat the Cramér–Rao bound while the answer is wrong. Origin: incorrect retrieval of loadings for noisy data (Lichtert and Verbeeck 2013).
- Cueva et al. (2012): poor peak-to-background EELS, PCA-filtered → serious artifacts (Cueva et al. 2012).
Important
“Looks clean” ≠ “is correct”. A denoised map can be precise and biased at once. Validate against unfiltered fits / known references (slide 16) before trusting PCA-denoised numbers.
23. Case: EELS Spectrum Imaging — Fe Oxidation-State Mapping
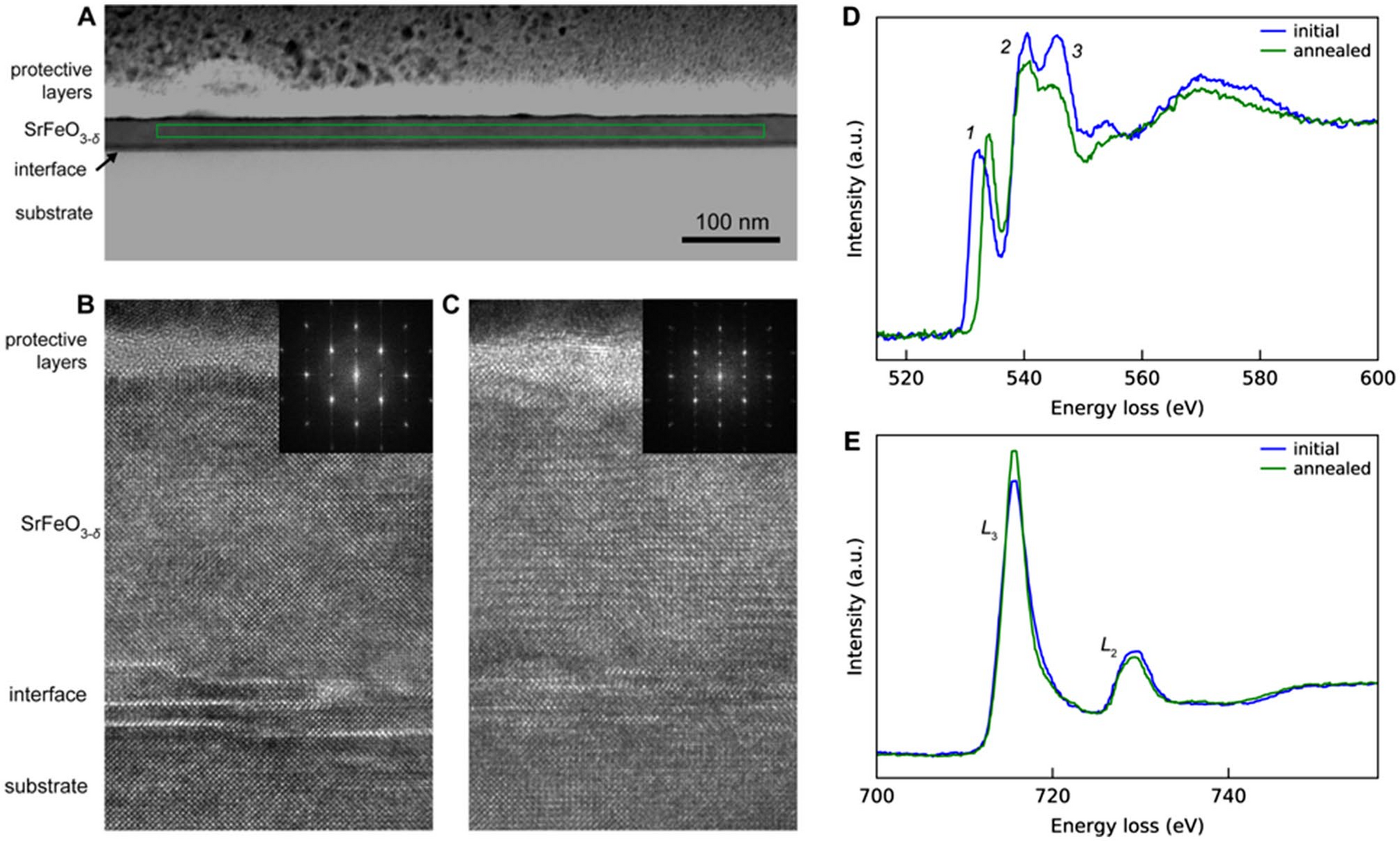
Problem. Map Fe oxidation state at nm resolution. The Fe-L₂,₃ white-line ratio (\(L_3/L_2\)) and onset shift (~0.3 eV, slide 04) separate the valences — but it is buried in Poisson noise at usable dose.
Pipeline. Power-law background (07/07a) → ZLP calibration (08) → DAE denoise pretrained on simulated Fe-L edges (Pate et al. 2021); weak signal → self-supervised UDVD (Wang et al. 2025) (18c) → constrained white-line fit (10) → continuous valence from the fitted ratio, not a raw latent (17).
Impact. Oxidation-state mapping at ~5–10× lower dose; resolves continuous mixed-valence gradients; validated against valence reference standards (16).
24a. Worked Case — STEM-EDS Phase Mapping of a Device Cross-Section

The end-to-end story. Raw EDS datacube → noise-weighted PCA denoise + optimal truncation (Potapov and Lubk 2019) → MCR for physical components (Kotula and Keenan 2006) → abundance maps registered to \((x,y)\) → interfacial chemistry of the device.
- Resolves nm-scale barrier / silicide layers and separates FIB Ga / Pt-cap artifacts into their own components (slide 14a).
- Decades old, still the production default — the bar any deep method must clear.
Important
The deliverable is which phase is where, with what spectrum — auditable components, not a latent embedding. Match the method to the question (throughput + interpretability), not to fashion.