flowchart LR
A["Raw Spectrum<br>x ∈ ℝ²⁰⁴⁸"] --> B["Center<br>x - x̄"]
B --> C["Project onto<br>Eigenspectra V"]
C --> D["Score Vector<br>c ∈ ℝᴷ"]
D --> E["Reconstruct<br>x̂ = x̄ + Vc"]
E --> F["Denoised<br>Spectrum"]
style A fill:#2d5016,stroke:#4a8c2a,color:#fff
style D fill:#1a3a5c,stroke:#2a6a9c,color:#fff
style F fill:#5c1a1a,stroke:#9c2a2a,color:#fffMachine Learning in Materials Processing & Characterization
Unit 10: ML for Characterization Signals




09. Interpreting Eigenspectra
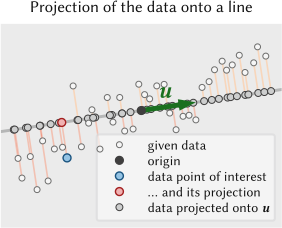
- PC1 (first eigenspectrum): Typically resembles the mean spectrum
- Captures the dominant overall shape (background + major peaks)
- PC2, PC3: Capture the dominant variations
- Often correspond to specific chemical differences between phases
- Example: PC2 might show positive Fe peaks and negative Cr peaks (Fe vs. Cr variation)
- Higher PCs (\(k > K_{\text{signal}}\)): Capture noise
- Appear as random oscillations with no physical meaning
11. Scree Plots: Choosing the Number of Components
How Many PCs to Keep? (Sandfeld et al. 2024)
- The scree plot shows the explained variance (eigenvalue) for each component
- Signal components have large eigenvalues; noise components have small, roughly equal eigenvalues
- The Elbow Rule: Keep components before the “elbow” where eigenvalues level off
- Cumulative variance: Often 95% or 99% of total variance is captured by \(K \sim 5\text{--}15\) components
- Alternative: Parallel analysis — compare eigenvalues against those from random data
12. Denoising via Reconstruction
Truncated PCA as a Filter (Sandfeld et al. 2024)
Algorithm:
- Compute eigenspectra from the dataset: \(\mathbf{V}_K = [\mathbf{v}_1, \ldots, \mathbf{v}_K]\)
- Project each noisy spectrum: \(\mathbf{c}_i = \mathbf{V}_K^\top (\mathbf{x}_i - \bar{\mathbf{x}})\)
- Reconstruct: \(\hat{\mathbf{x}}_i = \bar{\mathbf{x}} + \mathbf{V}_K \mathbf{c}_i\)
- The reconstruction \(\hat{\mathbf{x}}_i\) retains only the signal subspace — noise is discarded

- Equivalent to reducing acquisition time by 10x while maintaining chemical sensitivity
20. Non-linearity: The Power of AE vs PCA
- PCA: Finds the best linear subspace (a hyperplane)
- AE: Finds the best non-linear manifold (a curved surface)
- Example — XRD peak shift:
- As lattice parameter \(a\) increases, the (111) peak shifts to lower \(2\theta\)
- PCA needs multiple components to approximate this shift
- An AE learns: “one latent variable controls peak position” — direct physical meaning
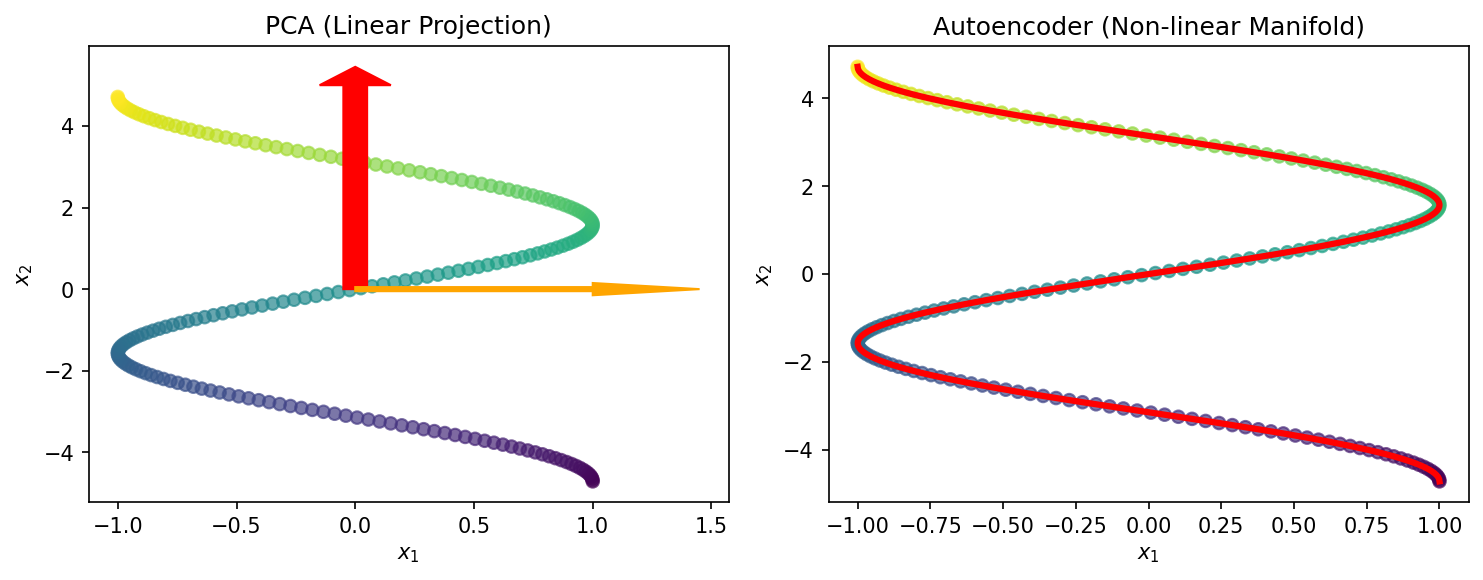
- Non-linearity lets the AE learn physically meaningful latent variables
24. DAE Example: EELS Spectra
Denoising the Fe-L\(_{2,3}\) Edge
- Problem: At low dose, the EELS fine structure that distinguishes Fe\(^{2+}\) from Fe\(^{3+}\) is buried in noise
- Approach:
- Train a DAE on simulated Fe-L edge spectra with known oxidation states
- Add Poisson noise at realistic dose levels during training
- Apply trained DAE to experimental spectra pixel-by-pixel
- Result: Clear Fe\(^{2+}\)/Fe\(^{3+}\) discrimination at 10x lower dose than conventional analysis
29. Anomaly Detection with Autoencoders
- Train the AE on “normal” spectra from the expected phases
- For a new spectrum \(\mathbf{x}\), compute the reconstruction error: \(e = \|\mathbf{x} - \hat{\mathbf{x}}\|^2\)
- If \(e > \tau\) (threshold), the spectrum is anomalous — it does not fit the learned representation
- Materials applications:
- Detecting unexpected phases or contamination
- Flagging instrument malfunctions (detector artifacts, calibration drift)
- Finding rare events (nano-precipitates, grain boundary segregation)

- Unlike supervised anomaly detection, this requires no labels — only knowledge of what “normal” looks like
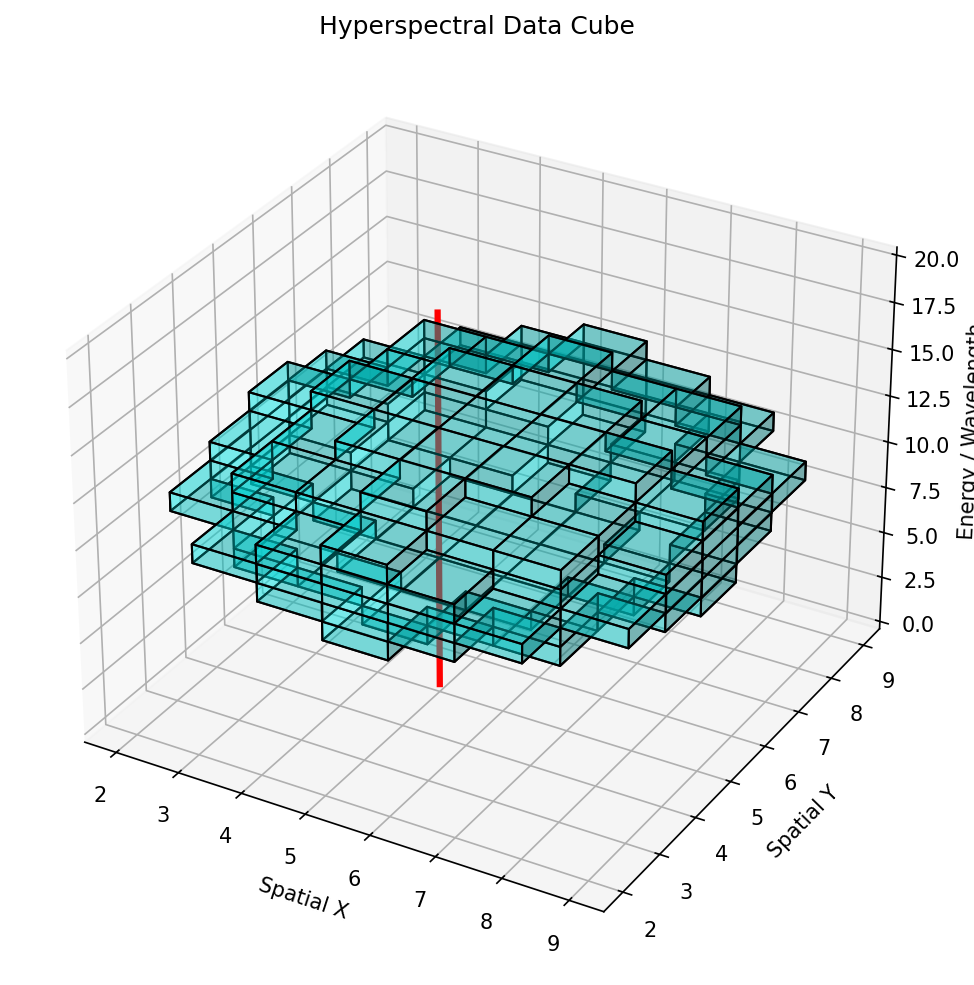
34. Multi-Spectral and Hyperspectral Data
The Data Cube: \((x, y, E)\)
- In spectrum imaging, every pixel \((x, y)\) has an associated spectrum \(\mathbf{s}(E)\)
- The result is a 3D data cube: two spatial dimensions + one spectral dimension
- Typical sizes:
- STEM-EDS: \(256 \times 256\) pixels \(\times\) \(2048\) channels \(= 134\) million values
- STEM-EELS: \(100 \times 100\) pixels \(\times\) \(1024\) channels \(= 10\) million values
- Naive approach: Unfold to a \(N_{\text{pixels}} \times D_{\text{channels}}\) matrix, apply PCA/AE per spectrum
- Better approach: Exploit spatial correlations — neighboring pixels likely have similar spectra
42. Case Study: Automatic XRD Phase Identification
Problem
- Given a noisy XRD pattern, identify which crystallographic phases are present
- Traditional: Match peaks against the ICDD database (manual, slow, error-prone for mixtures)
ML Approach
- Train an autoencoder on simulated XRD patterns for all candidate phases
- Encode the unknown pattern into latent space
- Use nearest-neighbor classification or clustering in latent space
Results
- Handles multi-phase mixtures by decomposition in latent space
- Robust to preferred orientation and peak broadening (which confuse database matching)
- Can detect amorphous phases as anomalies (high reconstruction error)

44. Case Study: Large-Scale EDS Maps
The Scale Challenge
- Modern SEM/STEM-EDS: \(512 \times 512\) pixels, 2048 channels = ~500,000 spectra
- Multiple fields of view → millions of spectra per sample
PCA-Based Pipeline
- Apply PCA to the unfolded data cube (\(N \times D\) matrix)
- Denoise: Reconstruct using top-\(K\) components (typically \(K = 10\text{--}20\))
- Cluster in score space using K-means
- Map cluster assignments back to spatial coordinates → phase map
Results
- Denoised maps reveal trace elements below the raw noise floor
- Phase maps identify 5-8 distinct phases automatically
- Processing time: Minutes on a standard workstation (PCA is fast!)

45. Clustering in Latent Space: UMAP Visualization
From Latent Codes to Phase Maps (Sandfeld et al. 2024)
- After dimensionality reduction (PCA or AE), each spectrum is a point \(\mathbf{z}_i \in \mathbb{R}^K\)
- UMAP (Uniform Manifold Approximation and Projection) projects \(K\)-dimensional latent codes to 2D for visualization
- Preserves both local and global structure (better than t-SNE for this)
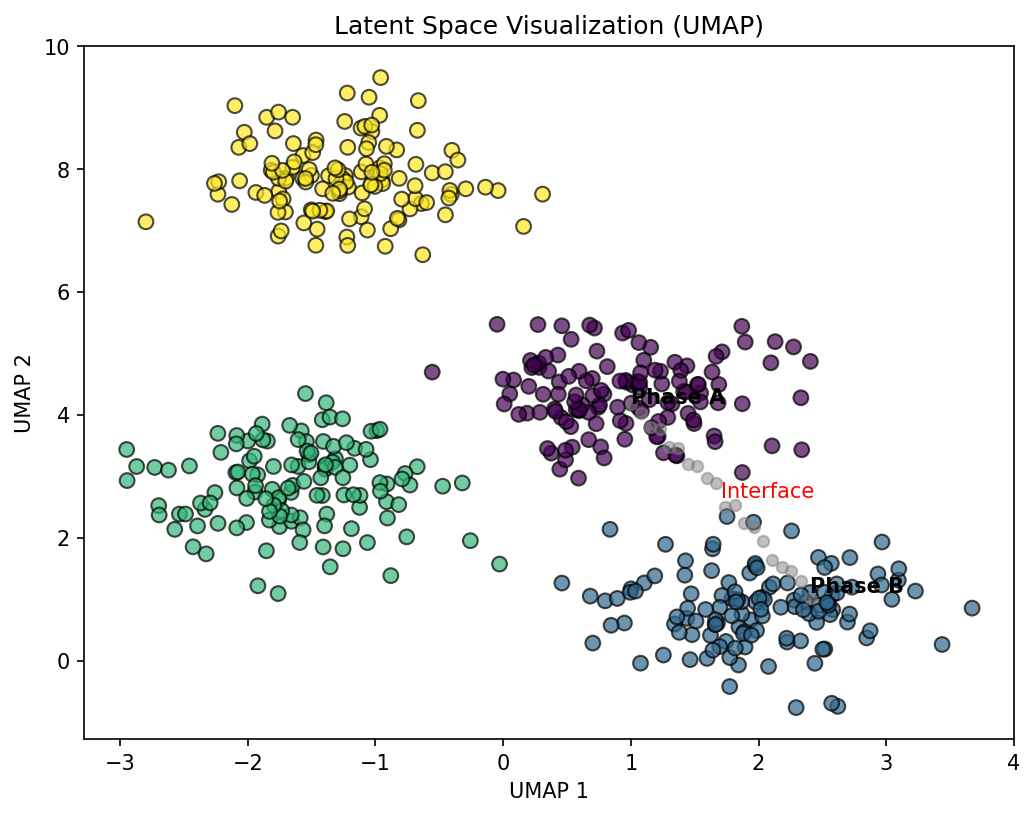
- Clusters in UMAP space correspond to distinct material phases
- Bridges between clusters indicate transition regions (interfaces, diffusion zones)
- Outliers flag anomalies or rare phases