Machine Learning for Characterization and Processing
Unit 13: Course Recap — From Materials Data to Trustworthy Models
AI 4 Materials / KI-Materialtechnologie




Unit 1 — What makes materials data special?
The question: why is ML on materials data fundamentally different from mainstream ML?
- Small data, high cost: \(10\)–\(10^3\) samples, not millions.
- Multi-scale & multi-modal: images + spectra + logs.
- Curse of dimensionality: you cannot sample densely.
- White / grey / black-box spectrum — pick by data size and domain knowledge.
- CRISP-DM structures the project, question → deployment.
- Correlation \(\neq\) causation; leakage lurks in metadata.
The grey-box strategy (Neuer et al. 2024; Sandfeld et al. 2024): \[ \sigma_y(c) = \underbrace{\Delta\sigma_{\text{SSS}}(c; \varepsilon, G)}_{\text{physics baseline}} + \underbrace{f_{\text{ML}}(c)}_{\text{data-driven residual}} \]
Unit 2 — The key equations
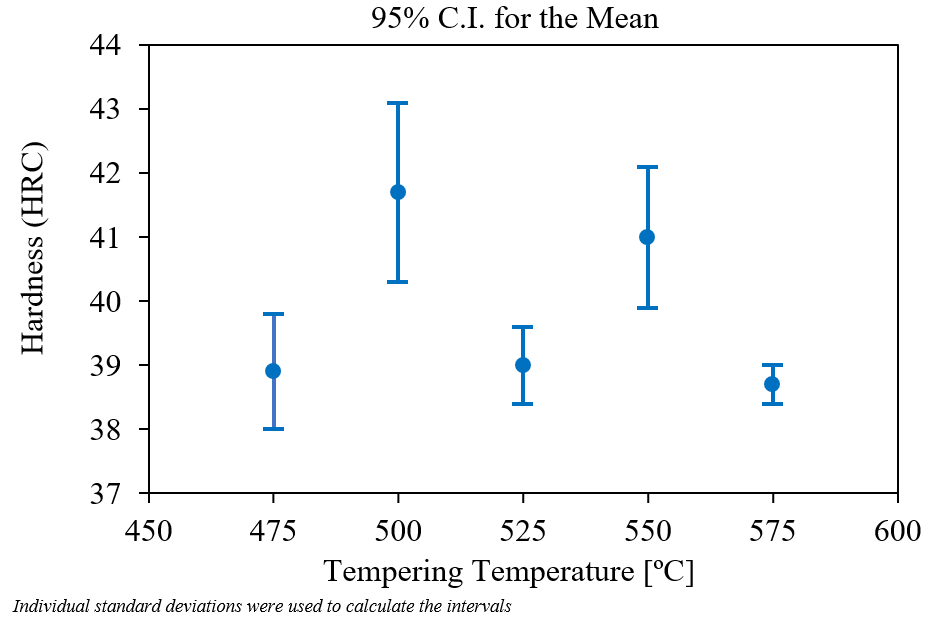
The imaging equation — the most important of the unit (Neuer et al. 2024): \[ y(\mathbf{r}) = (h \ast x)(\mathbf{r}) + n(\mathbf{r}) \]
Bayes’ theorem, which turns the noise model into the loss function: \[ P(\boldsymbol{\theta} \mid \mathbf{X}) = \frac{P(\mathbf{X} \mid \boldsymbol{\theta})\, P(\boldsymbol{\theta})}{P(\mathbf{X})} \]
- MSE is the Gaussian likelihood; Poisson data needs a Poisson NLL.
- Diagnose with a variance–mean plot: \(\sigma^2 \propto \mu\) means shot noise.
Unit 3 — The key equations
- Standardization \(z_i = (x_i - \mu)/\sigma\) — required by every distance-based and regularized method.
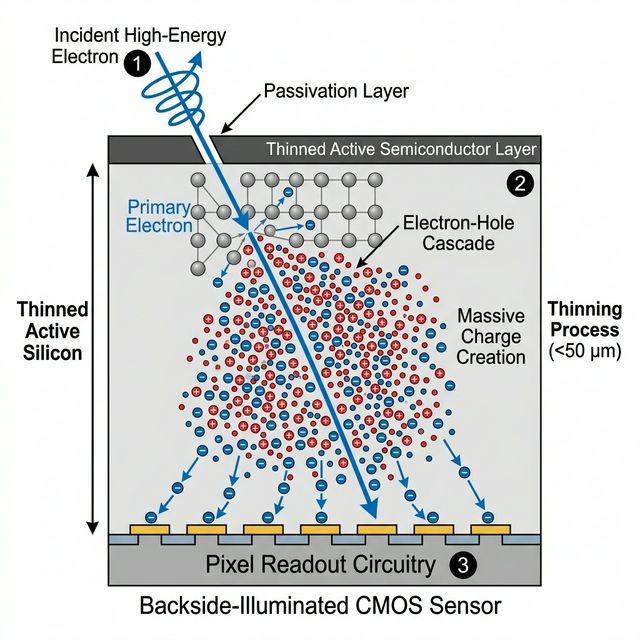
The bias–variance decomposition for \(y = f(x) + \varepsilon\) — why validation design matters (Sandfeld et al. 2024): \[ \mathbb{E}[(\hat{y} - y)^2] = \bigl(\mathbb{E}\hat{y} - f(x)\bigr)^2 + \mathrm{Var}(\hat{y}) + \sigma^2 \]
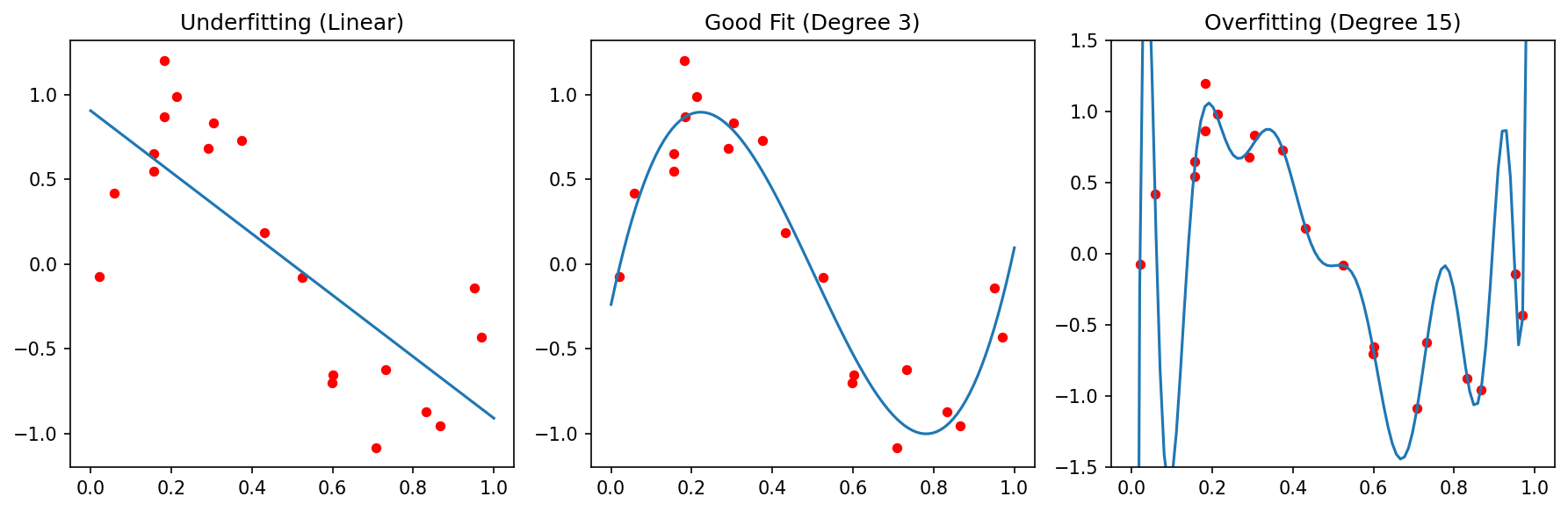
The three regimes every validation curve is trying to distinguish: too stiff (high bias), well-balanced, too flexible (high variance).
Unit 4 — The key method
Two-point statistics generalize stereology (Sandfeld et al. 2024): \[ S_2(\mathbf{r}) = P\!\bigl(\text{phase}(\mathbf{x})=\alpha \,\wedge\, \text{phase}(\mathbf{x}+\mathbf{r})=\alpha\bigr) \]
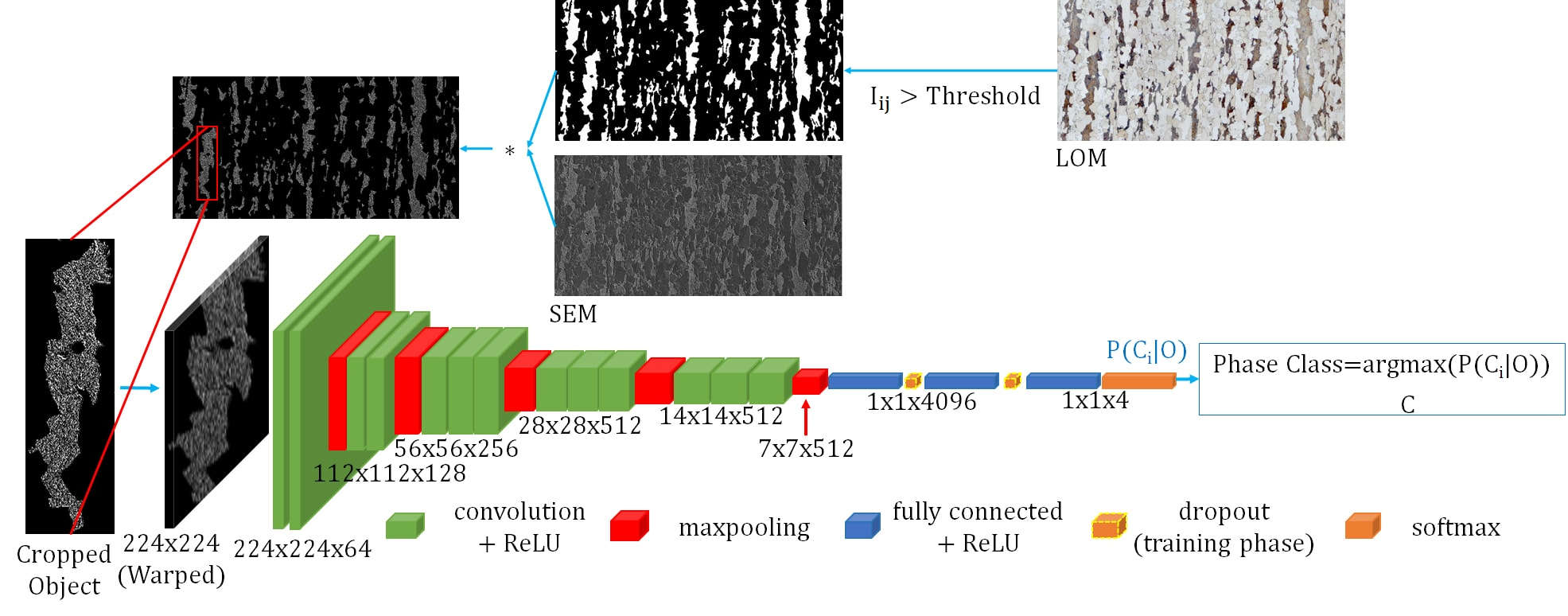
The hero result that motivated the unit: a fully convolutional network reaches 93.94% on steel constituent classification where classical pipelines reached 48.9% — the representation change alone unlocks the gain (Azimi et al. 2018).
Unit 5 — Method I: clustering
The K-means objective (Bishop 2006): \[ \min_{\{\mu_k\},\, \{c_i\}} \sum_{i=1}^{N} \|\mathbf{x}_i - \mu_{c_i}\|_2^2 \]
- Select \(k\) with silhouette, elbow, or BIC — and be able to defend the choice.
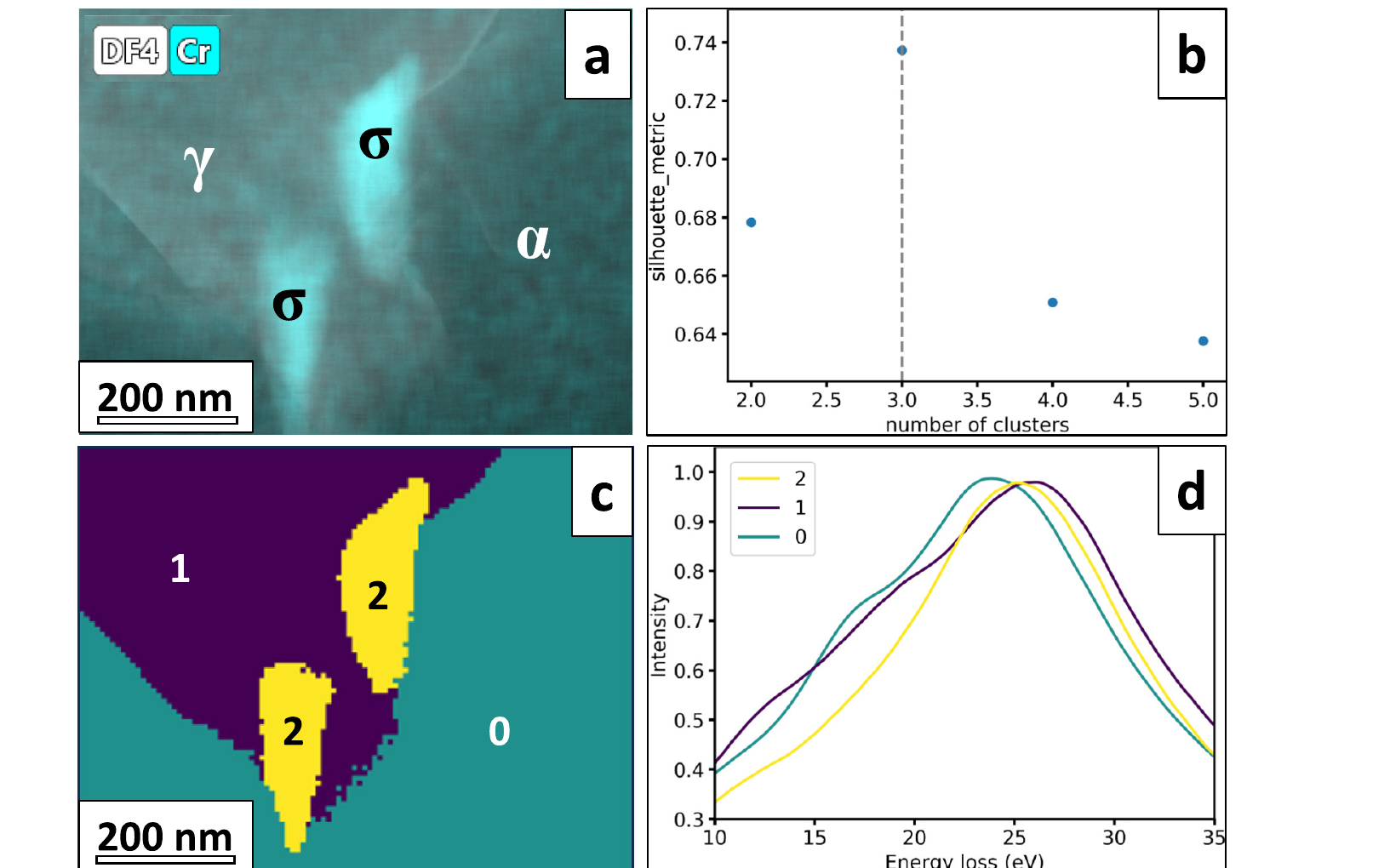
Phase mapping of industrial duplex stainless steel by K-means on low-loss EELS spectra: the cluster centroids are physically interpretable spectra.
Unit 5 — Method II: representations & autoencoders
Autoencoder objective and its anomaly score (Goodfellow et al. 2016): \[ \min_\theta\; \mathbb{E}_{x \sim \mathcal{D}}\, \|x - g_\theta(f_\theta(x))\|_2^2, \qquad a(x) = \|x - g_\theta(f_\theta(x))\|^2 \]
- The bottleneck dimension is an inductive bias: too small underfits structure, too large learns the identity.
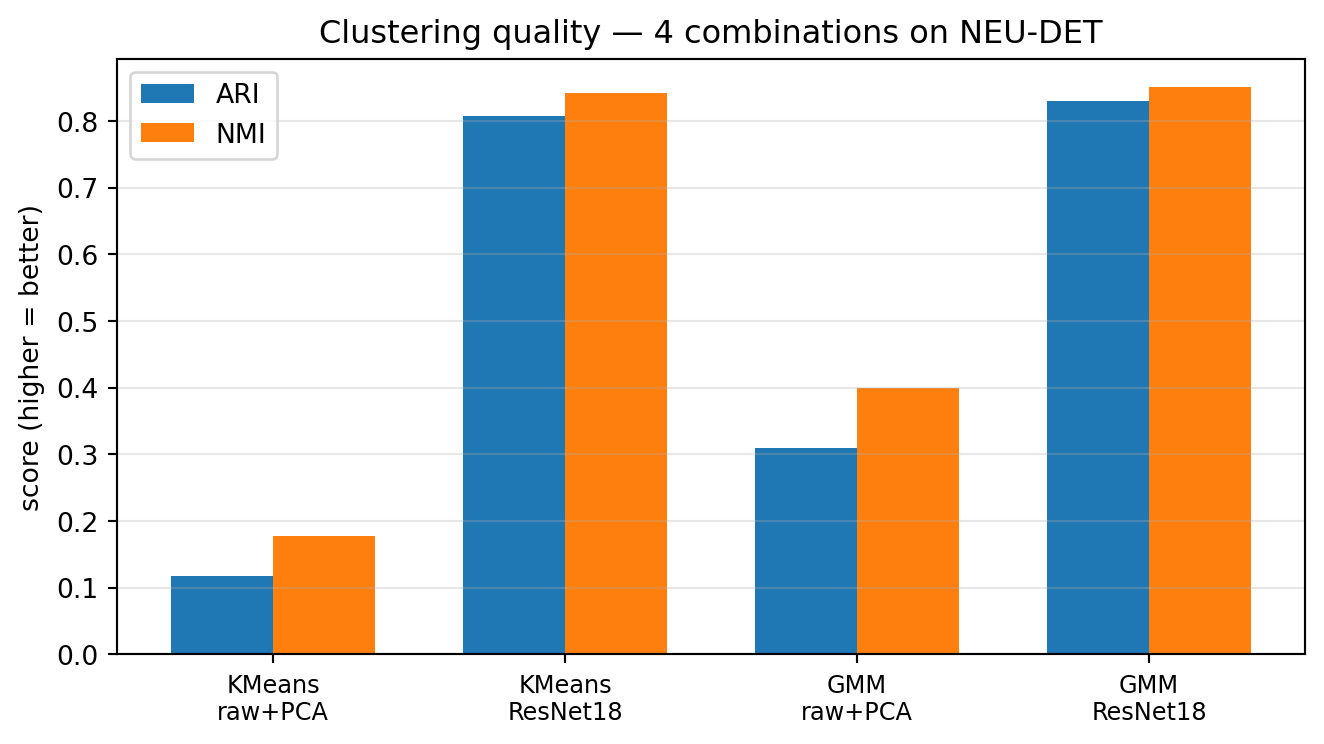
The unit’s core lesson: identical K-means, different representation — raw pixels score ARI 0.12 on NEU-DET steel defects, ResNet18 embeddings score 0.81.
Unit 6 — Data scarcity & transfer learning
The question: how can deep models work with 50–500 labeled micrographs instead of millions?
- Transfer learning: ImageNet features transfer because early layers are generic — transferability falls with depth (Yosinski curve) (Yosinski et al. 2014).
- Differential learning rates protect pretrained features: \[ \text{lr}_{\text{backbone}} = \frac{\text{lr}_{\text{head}}}{100} \]
- Augmentation must preserve the physics — rotation is illegal if direction matters.
- Synthetic data: powerful pretraining, but \(p_{\text{synth}}(x) \neq p_{\text{real}}(x)\) — the generator fails exactly on what it omits.
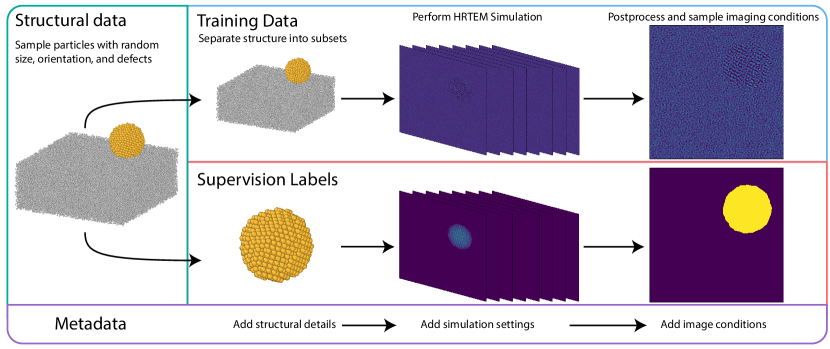
Unit 7 — The key equations
The LSTM cell update whose additive structure lets gradients flow through time: \[ C_t = f_t \odot C_{t-1} + i_t \odot \tilde C_t \]
Heteroscedastic Gaussian NLL — fit the mean and an honest variance: \[ -\log p(x_{t+1}\mid \mu_t, \sigma_t^2) = \tfrac{(x_{t+1}-\mu_t)^2}{2\sigma_t^2} + \tfrac{1}{2}\log\sigma_t^2 + \mathrm{const.} \]
- Epistemic part from deep ensembles or MC dropout (Gal and Ghahramani 2016; Lakshminarayanan et al. 2017).
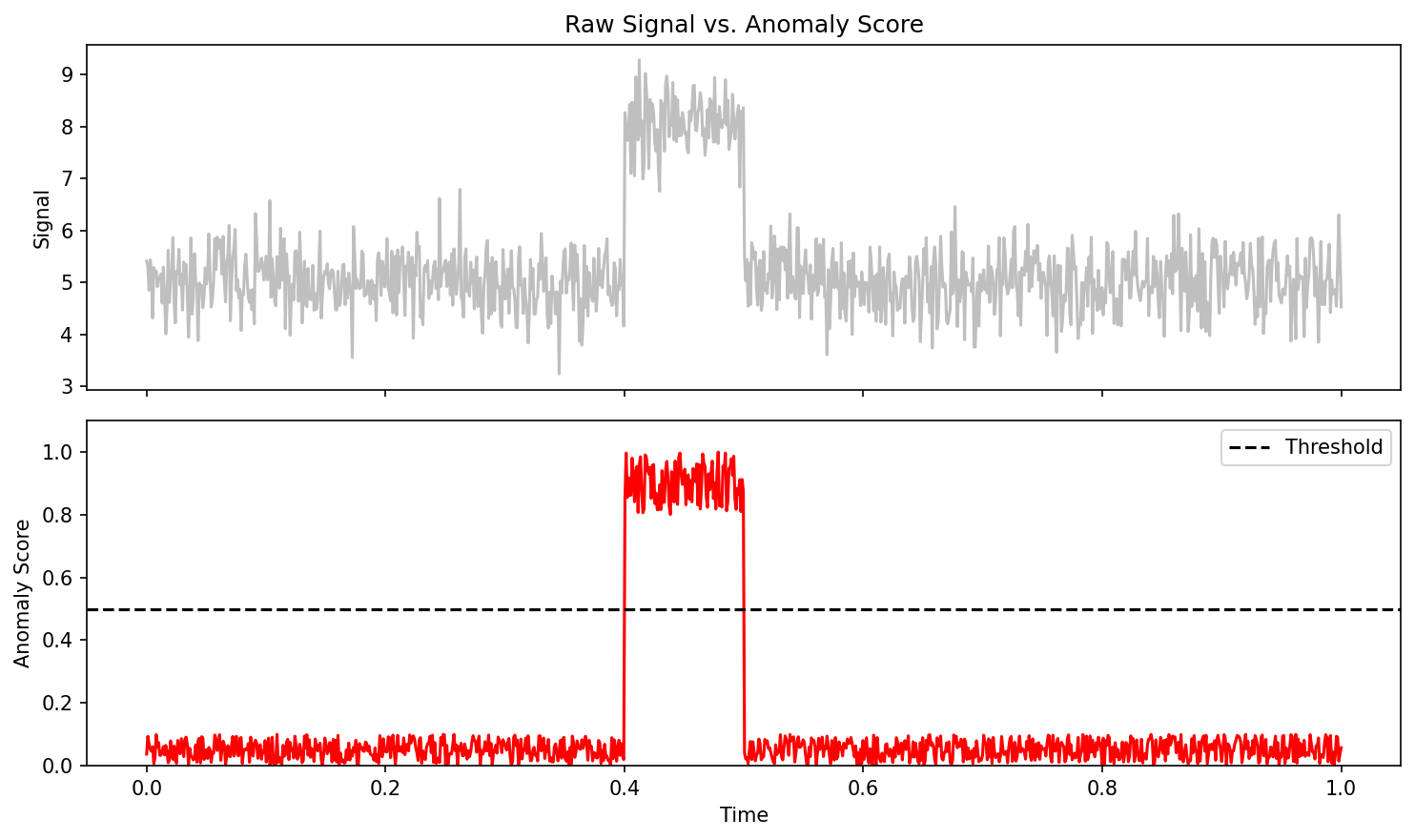
Unit 8 — The key equations
The regularized inverse problem (Neuer et al. 2024): \[ \hat{\mathbf{x}} = \arg\min_{\mathbf{x}} \|f(\mathbf{x}) - \mathbf{y}_\text{obs}\|^2 + \lambda R(\mathbf{x}) \]
SINDy — the governing equation as a sparse combination of library terms (Brunton et al. 2016): \[ \frac{d\mathbf{x}}{dt} = \boldsymbol{\Theta}(\mathbf{x})\,\boldsymbol{\xi} \]
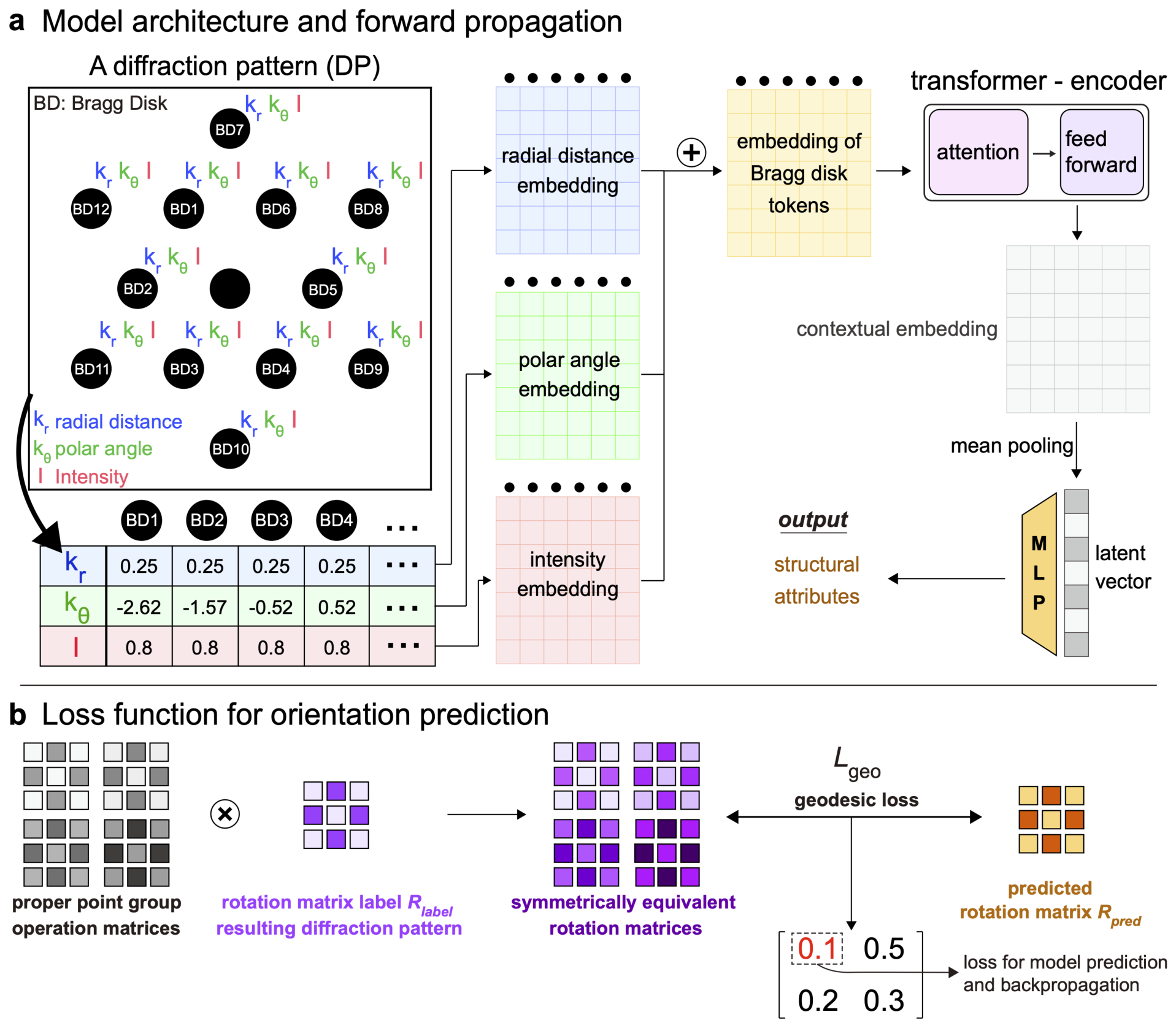
Unit 9 — The key method
Linear spectral unmixing — and its fundamental ambiguity (Kotula and Keenan 2006): \[ \mathbf{X} = \mathbf{C}\mathbf{S}^\top + \mathbf{E}, \qquad \mathbf{X} = (\mathbf{C}\mathbf{T})(\mathbf{T}^{-1}\mathbf{S}^\top) \]
- Any invertible \(\mathbf{T}\) fits equally well: rotational ambiguity. Physical constraints — non-negativity, closure, selectivity, known spectra — collapse the feasible band.
- Denoising by weighted PCA with optimal truncation (Potapov and Lubk 2019); keep the residual channel for anomaly detection.

The unit’s core architecture: every modality flows through background subtraction → calibration/alignment → normalization → deconvolution → reduction/decomposition.
Unit 10 — Method I: attention
Scaled dot-product attention — the core mechanism (Vaswani et al. 2017): \[ \mathrm{Attn}(Q, K, V) = \mathrm{softmax}\!\left(\frac{QK^\top}{\sqrt{d_k}}\right) V \]
- A CNN needs \(\sim L/2\) stacked \(3{\times}3\) layers to connect antipodal Bragg discs; attention does it in one.
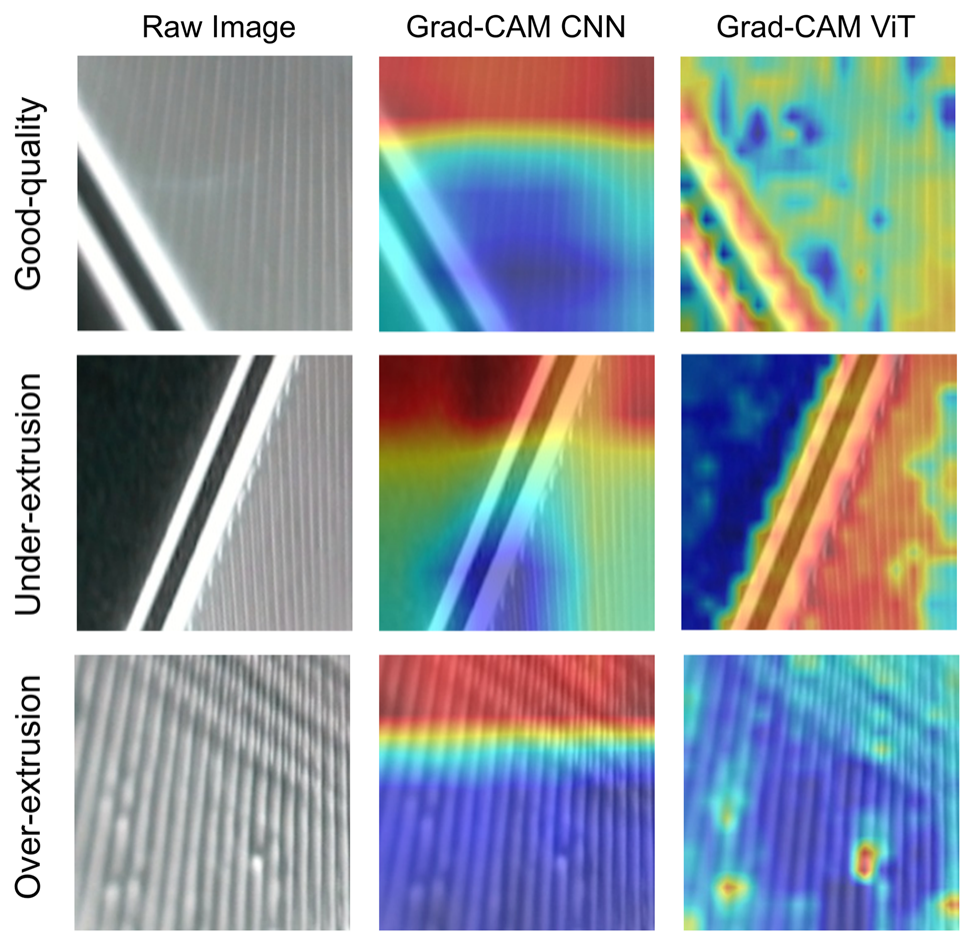
Unit 10 — Method II: efficiency & the training recipe
Flash Attention: tiled computation with online softmax in SRAM \[ \mathcal{O}(L^2) \;\to\; \mathcal{O}(L) \quad \text{in memory} \]
- The label-scarce recipe: collect unlabeled data → self-supervised pretraining (MAE, DINOv2) → freeze backbone → fine-tune the head on 50–500 labels with group-wise splits.
Unit 11 — Method I: the PINN composite loss
\[ J = J_{\text{data}} + \lambda\, J_{\text{phys}} + \lambda_b\, J_{\text{BC}} \]
- Autodiff evaluates the PDE residual on dense collocation points; sparse measurements anchor the data term — that’s how a handful of pyrometer readings becomes a dense temperature field.
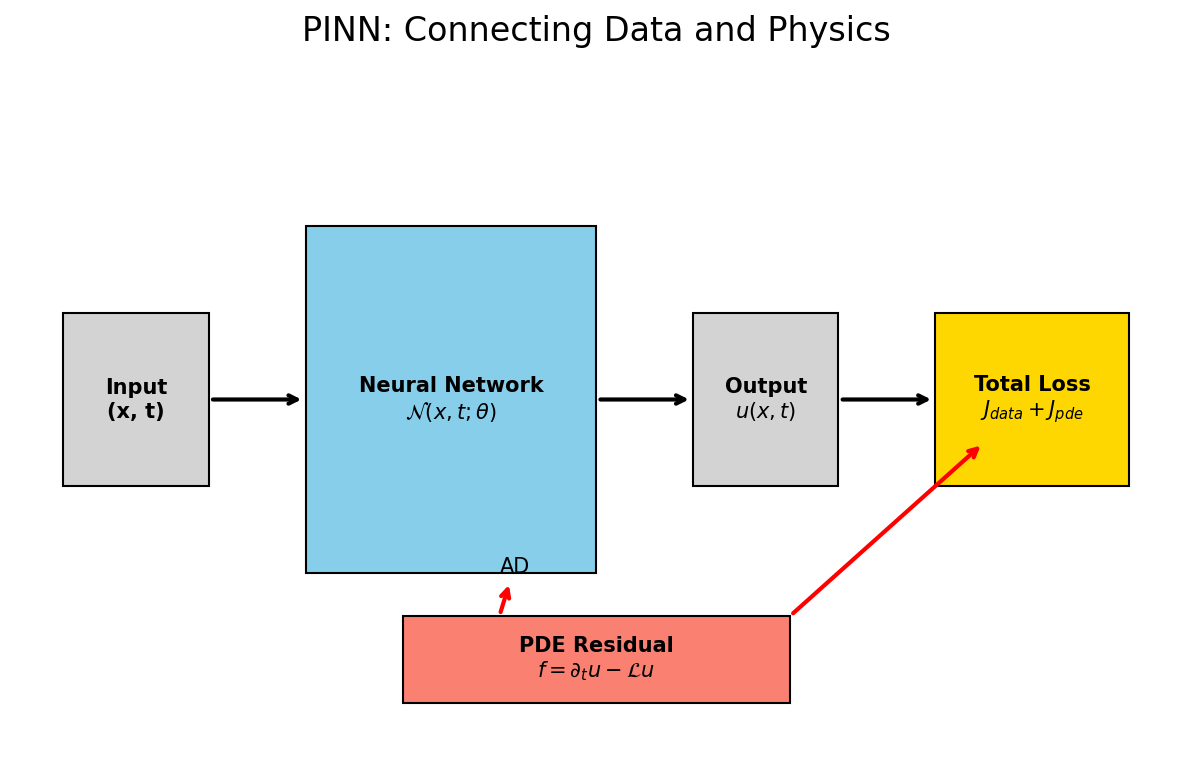
The PINN data flow: the network output feeds the data loss directly and, through automatic differentiation, the PDE residual loss.
Unit 11 — Method II: constraint patterns
- Pattern A — soft penalty: quick, approximate, tunable via \(\lambda\).
- Pattern B — full PINN: known PDE + sparse data → dense super-resolution between measurements.
- Pattern C — symmetry: augmentation (cheap, approximate) vs. equivariant architecture (exact, costly).
- Pattern D — structural: softplus increments make monotonicity mathematically exact.
- Neural operators solve whole families of boundary conditions and geometries at inference speed.
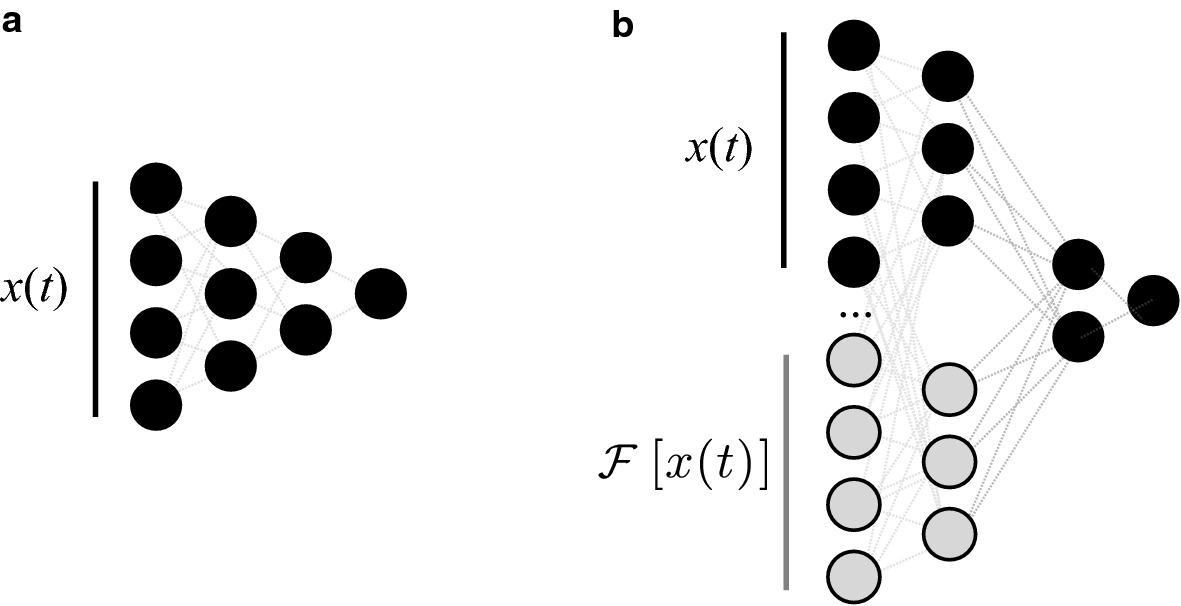
The Fourier-input idea behind FNO layers: the same network, operating on FFT-transformed inputs, sees global structure a pointwise network misses.
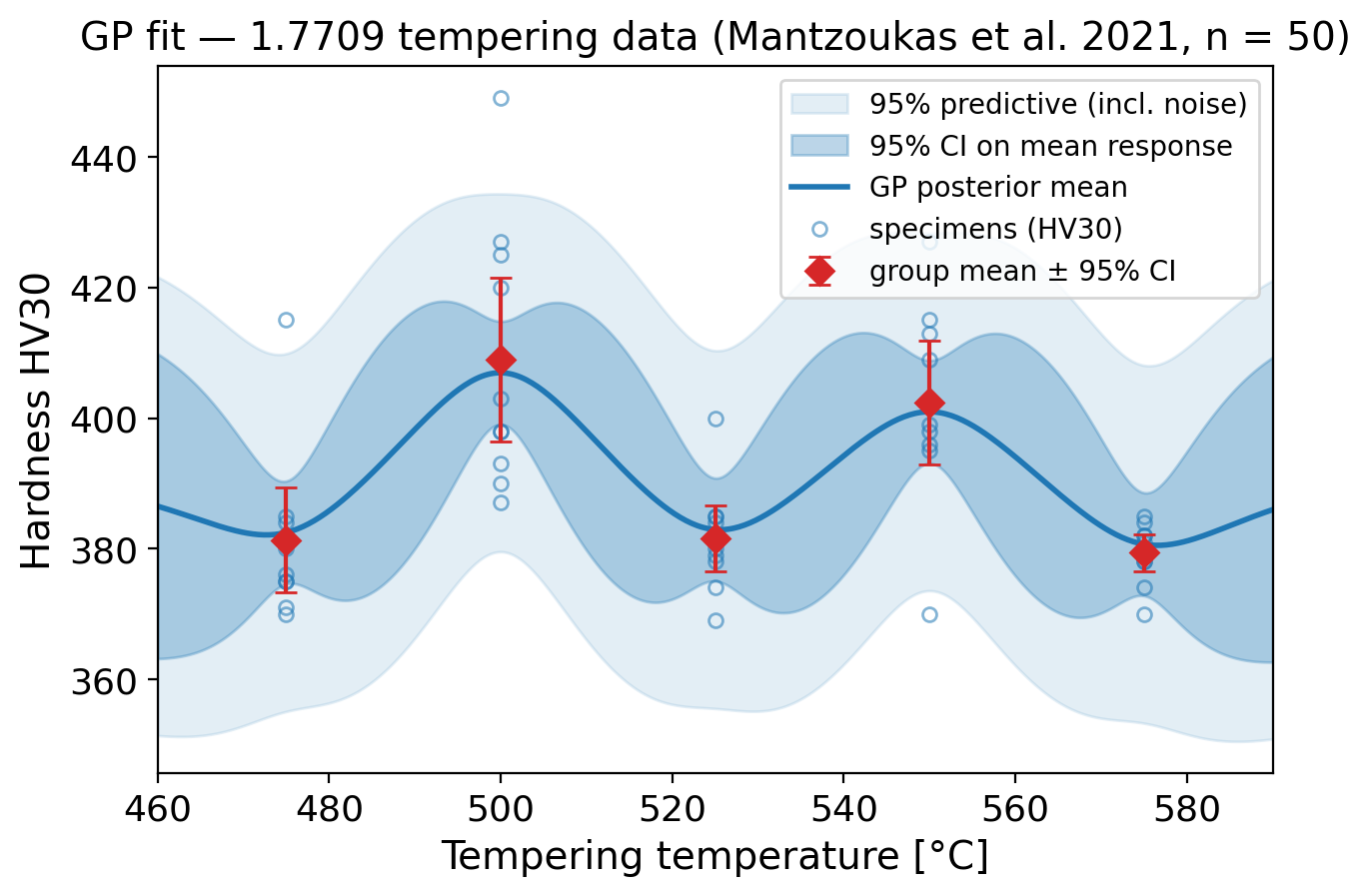
Unit 12 — Method I: Gaussian Processes
The RBF kernel, whose length scale \(\ell\) is a physical correlation length: \[ k_{\text{RBF}}(T, T') = \sigma_f^2 \exp\!\left(-\frac{(T - T')^2}{2\,\ell^2}\right) \]
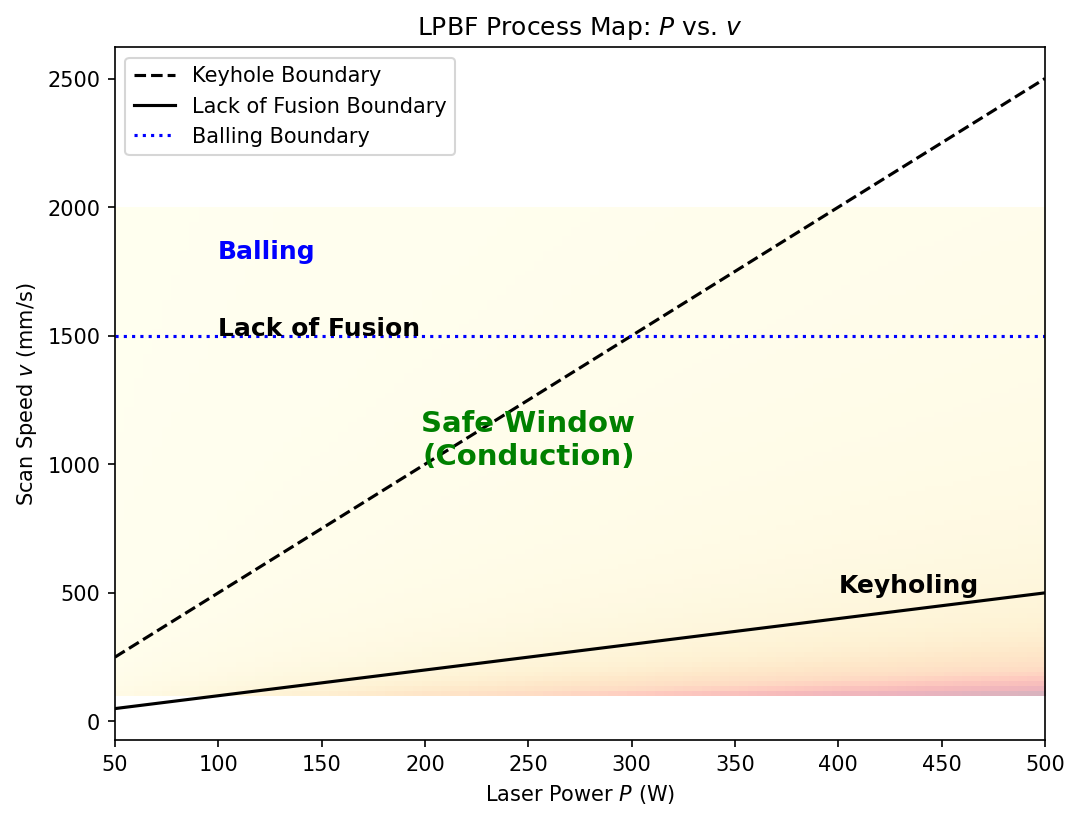
The acquisition function that turns \(\sigma\) into an experiment plan: \[ \alpha_{\text{UCB}}(P,v) = \mu(P,v) + \beta\,\sigma(P,v) \]
Unit 12 — Method II: uncertainty for deep networks
MC Dropout at inference: average \(T\) stochastic passes, report per-pixel entropy (Gal and Ghahramani 2016): \[ \bar{p}_{i,c} = \tfrac{1}{T}\sum_t p_{i,c}^{(t)}, \qquad H_i = -\sum_c \bar{p}_{i,c} \log \bar{p}_{i,c} \]
- Deep ensembles (\(M \in [5,10]\)) remain the empirical gold standard for NN calibration (Lakshminarayanan et al. 2017).

Per-pixel honesty on MetalDAM micrographs: entropy is low inside well-formed phases and high exactly where human annotators hesitate — phase boundaries and defect rims.