Data Science for Electron Microscopy
Lecture 1: Introduction




Outline
Formalities

Introduction
to
Electron
Microscopy
Data
Basic Pytorch
Knowledge

.

Book that covers many topics of the course

Interactive deep learning book with code, math, and discussions
Implemented with PyTorch, NumPy/MXNet, JAX, and TensorFlow
Adopted at 500 universities from 70 countries
We will use the pytorch framework for our coding
STEM operating modes
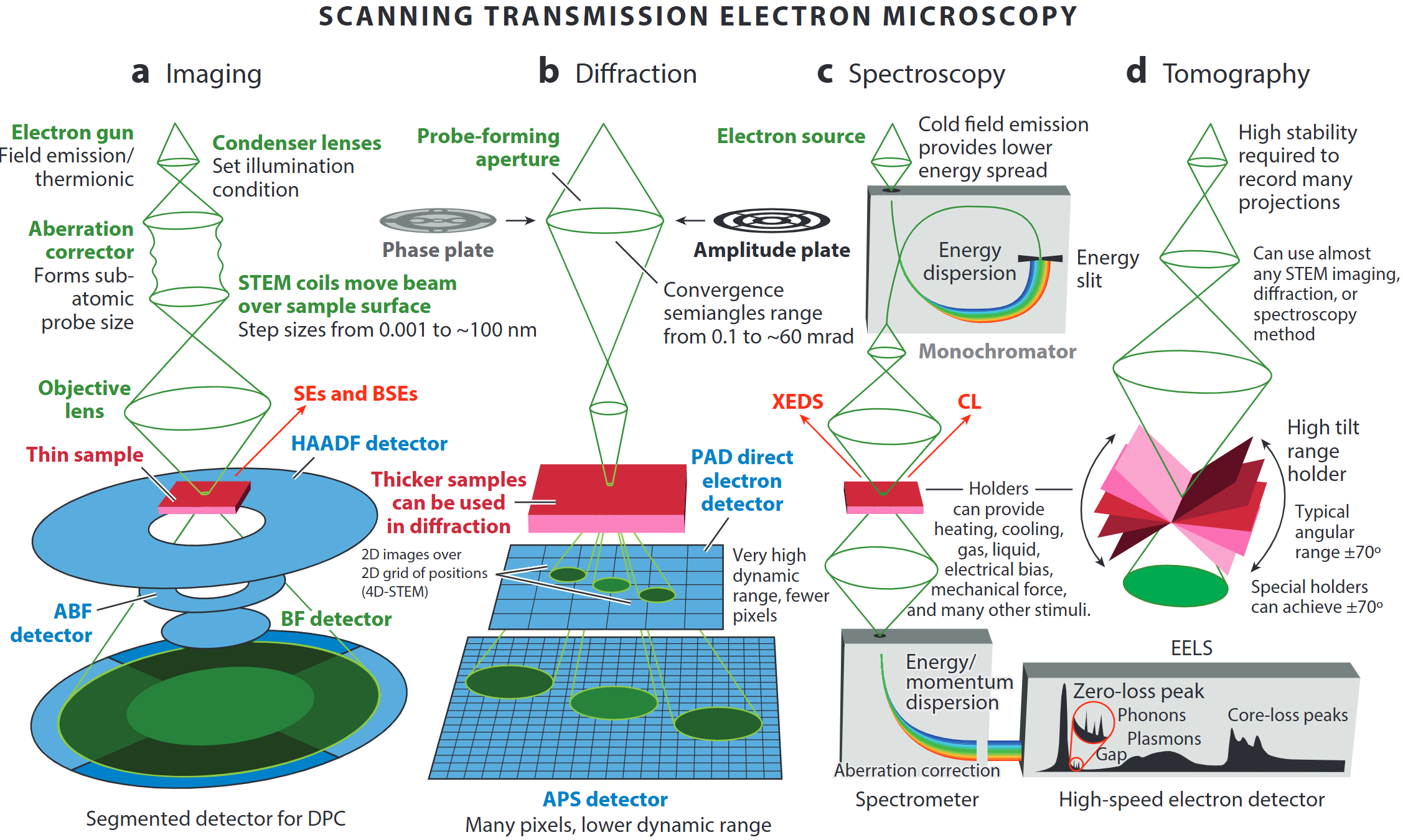
- A modern microscope can switch on the fly between
- incoherent imaging,
- diffraction/4D-STEM,
- EELS / XEDS spectroscopy, and
- tilt-series tomography
- incoherent imaging,
- “A synchrotron in a microscope”: one tool covers Å-to-µm length-scales and meV-to-keV energy-scales.
4DSTEM - Design of experiments
Single-atom Z-contrast

- HAADF collects high-angle incoherent scattering → intensity ∝ Z^1.6 – Z^1.9
- Detects & counts individual heavy atoms, even inside a nanowire.
- Sub-picometre column-position metrology enables strain & segregation studies.
Calibrated composition imaging

- Absolute detector-response calibration converts HAADF signal to atomic areal density .
- Enables nm-scale composition profiles (here Al₀.₂Ga₀.₈N) & local thickness determination to ≈1 nm.
Seeing light elements – ABF/BF
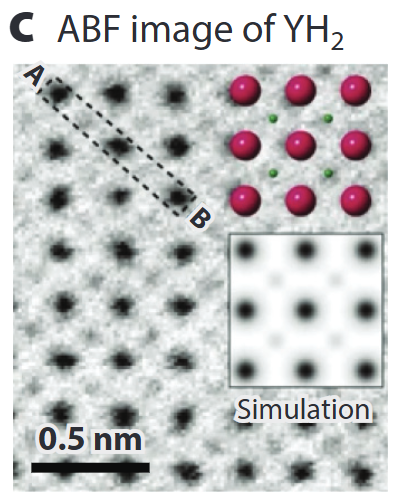
- Annular Bright-Field (ABF) records low-angle transmitted beam: simultaneously heavy & very light atoms (H, Li, O) .
- Quantitative contrast modelling (multislice + frozen phonon) allows thickness & defocus refinement.
Mapping internal fields – DPC
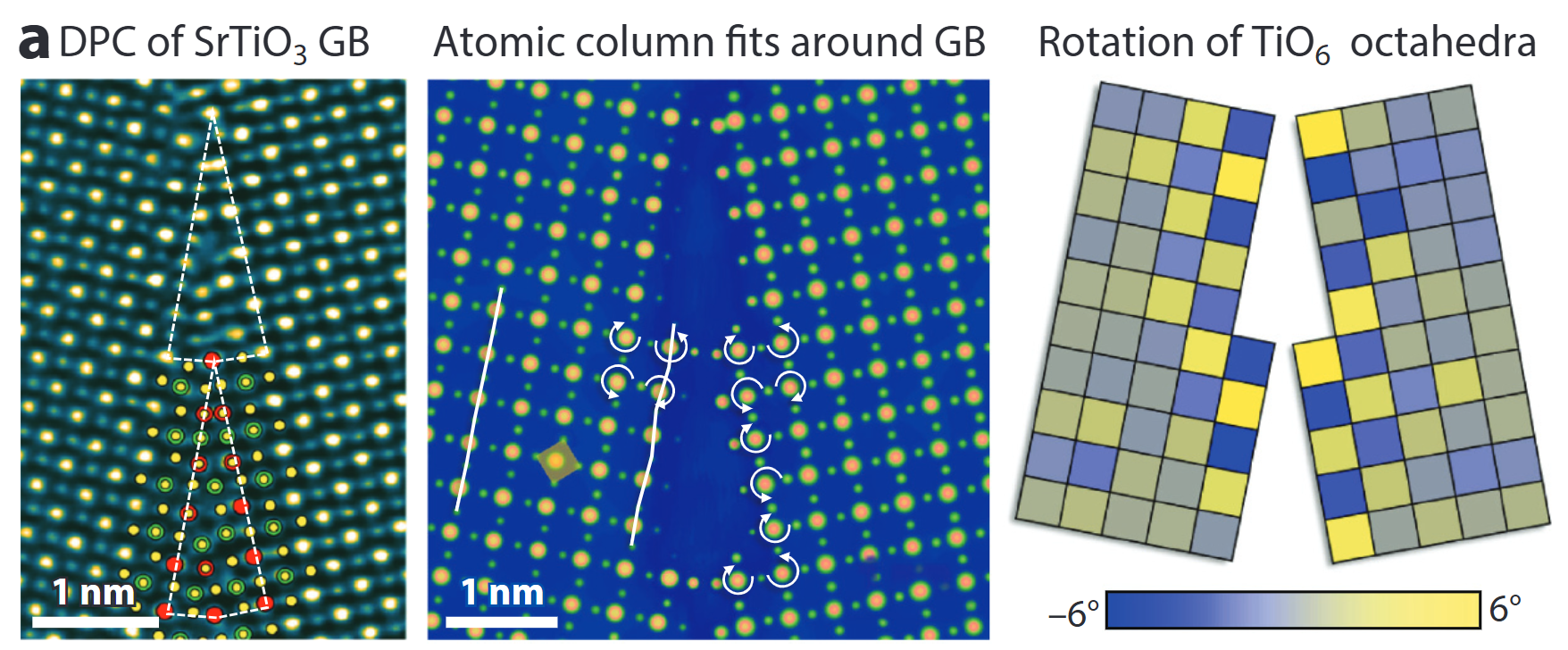
- Segmented / pixelated detectors yield differential phase-contrast (DPC) images.
- Linear to projected electric-field; with sample flip or advanced analysis → magnetic induction too .
- Here: TiO₆ octahedra rotations and GB polarity resolved at the picometre level.
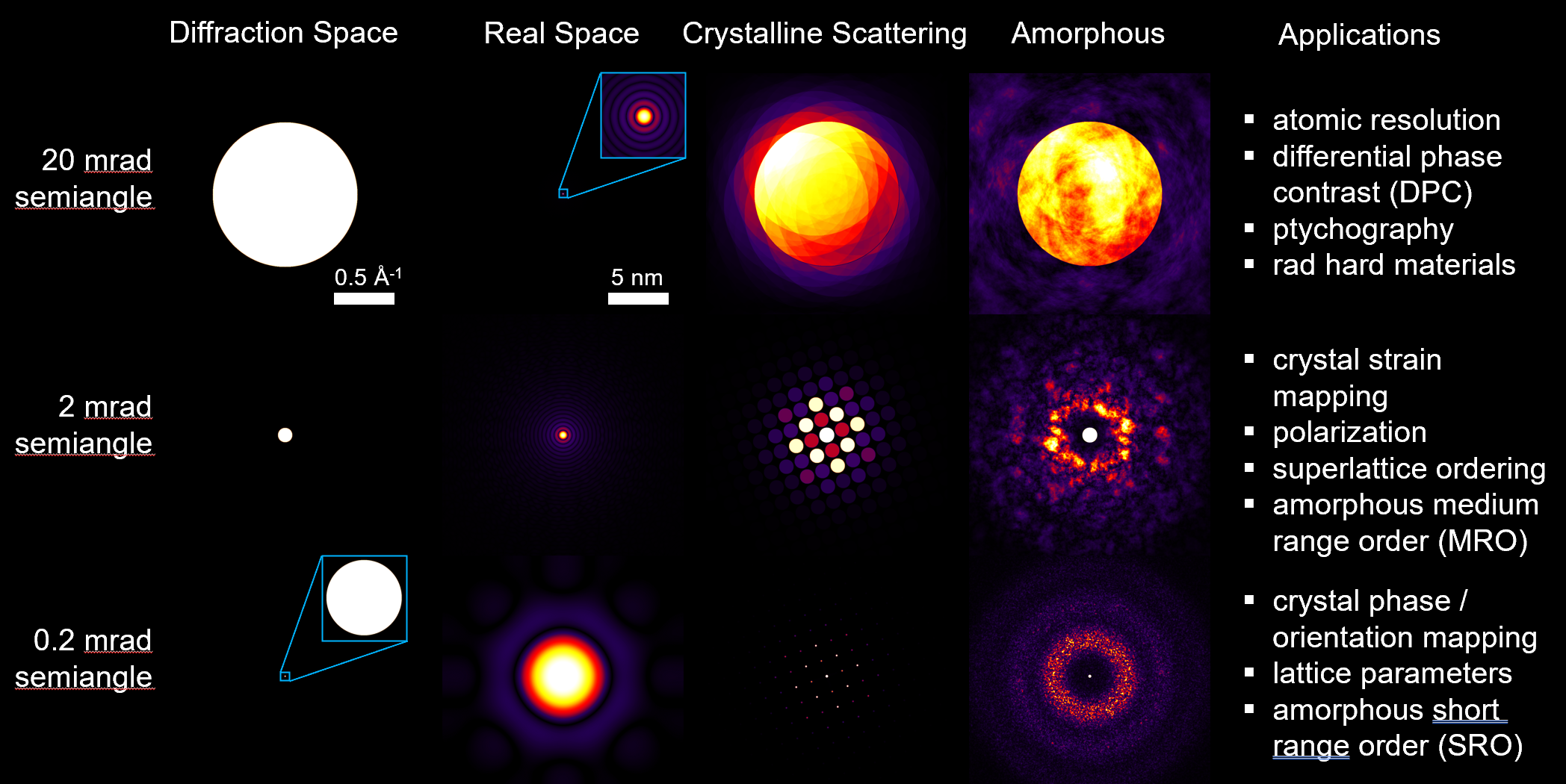
4D-STEM diffraction & orientation mapping
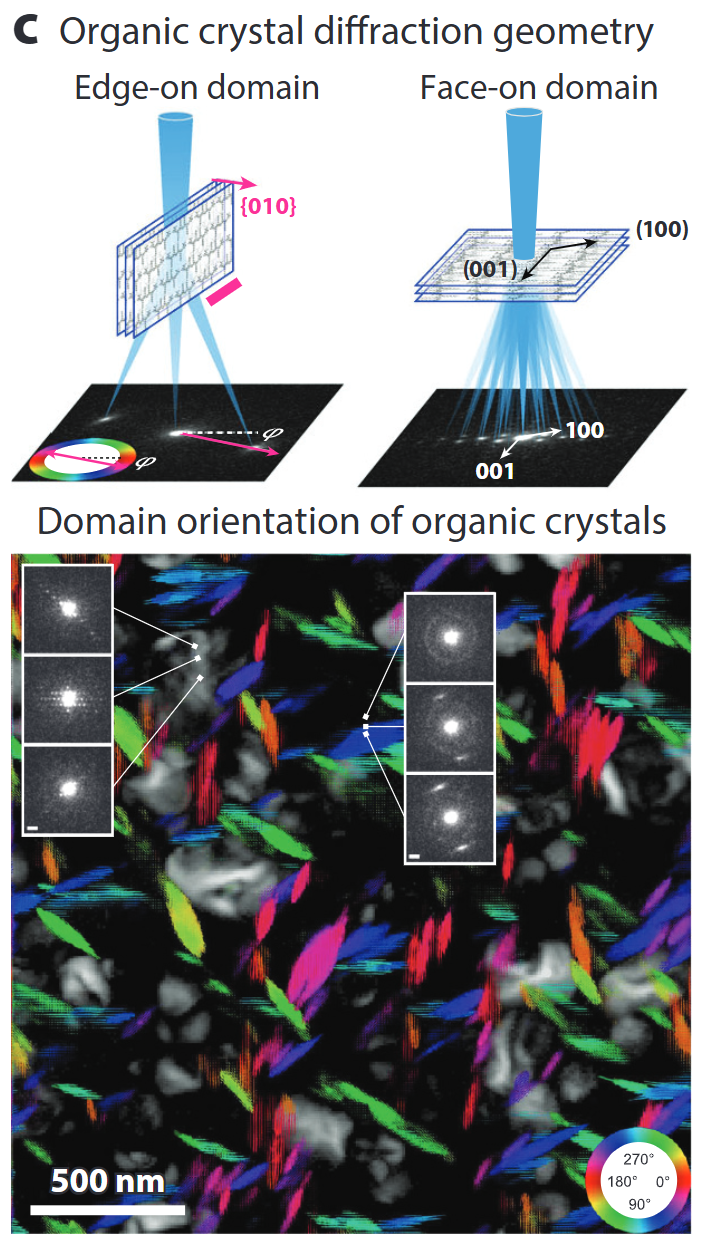
- Pixelated cameras record a CBED pattern at every probe position → 4D data cube.
- From disks, extract local strain, orientation, thickness, even (via ptychography) phases beyond the probe NA.
- Matching experiment to simulation (thermal + inelastic) achieves quantitative thickness/chemistry
Spectroscopy – EELS/XEDS

- STEM-EELS resolves plasmons (few eV), phonons (meV) & core-loss fine structure (bonding, oxidation).
- Combined with modelling (BEM, DFT, multiplet) for nanophotonic mode mapping .
- Parallel XEDS gives simultaneous 3-D elemental maps.
Atomic electron tomography
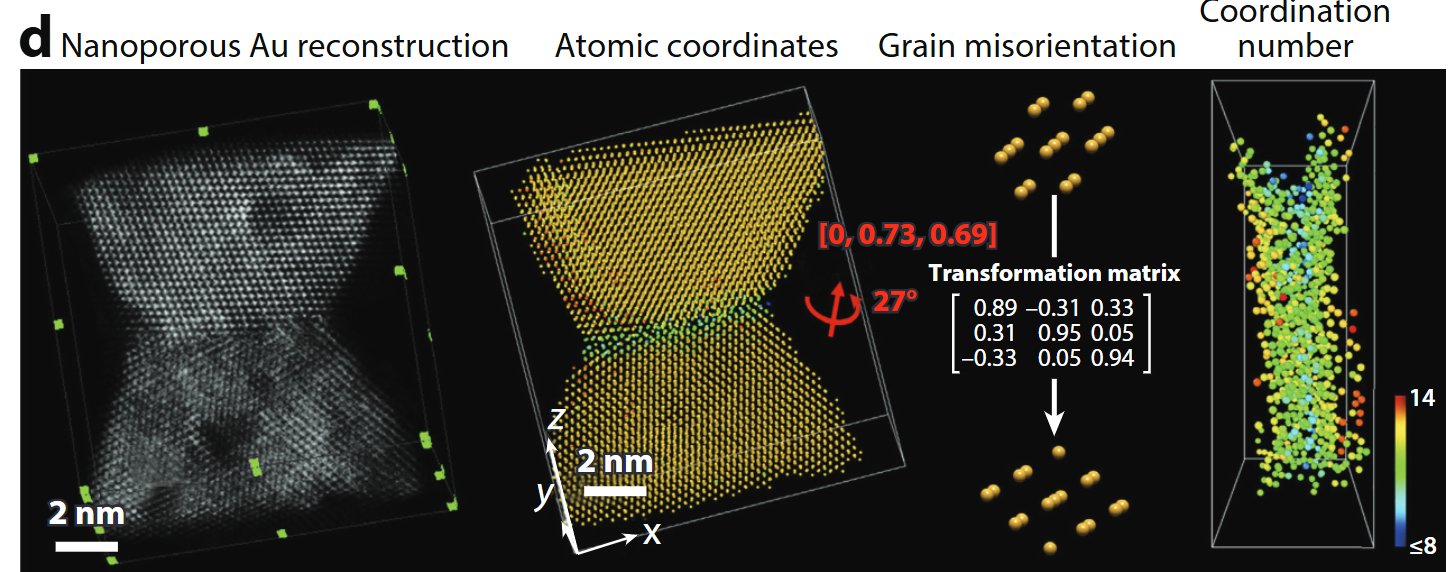
- Tilt-series HAADF/ptychography + iterative reconstruction → 3-D coordinates of every atom in ≤20 nm objects .
- Enables full strain tensors, defect cores, compositional ordering.
Simulation accelerators – PRISM
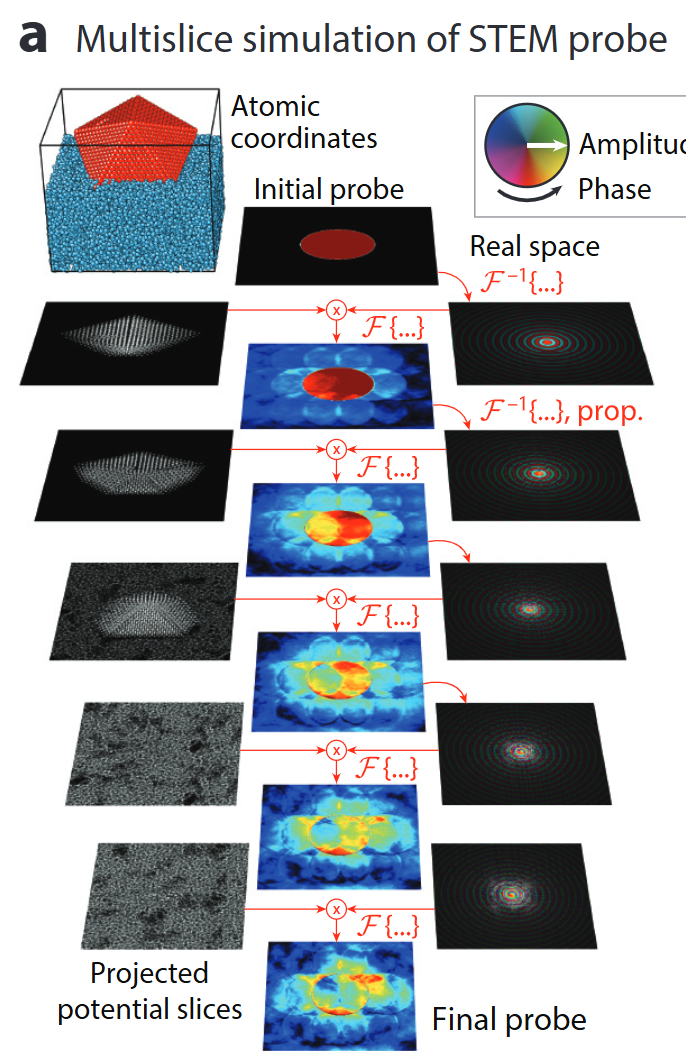
- Quantitative STEM hinges on ab-initio accurate multislice simulations.
- PRISM re-uses plane-wave slices → orders-of-magnitude faster with <1 % error .
- Powers real-time experiment steering & big-data 4D-STEM analysis.
The data-driven TEM framework (Figure 1)
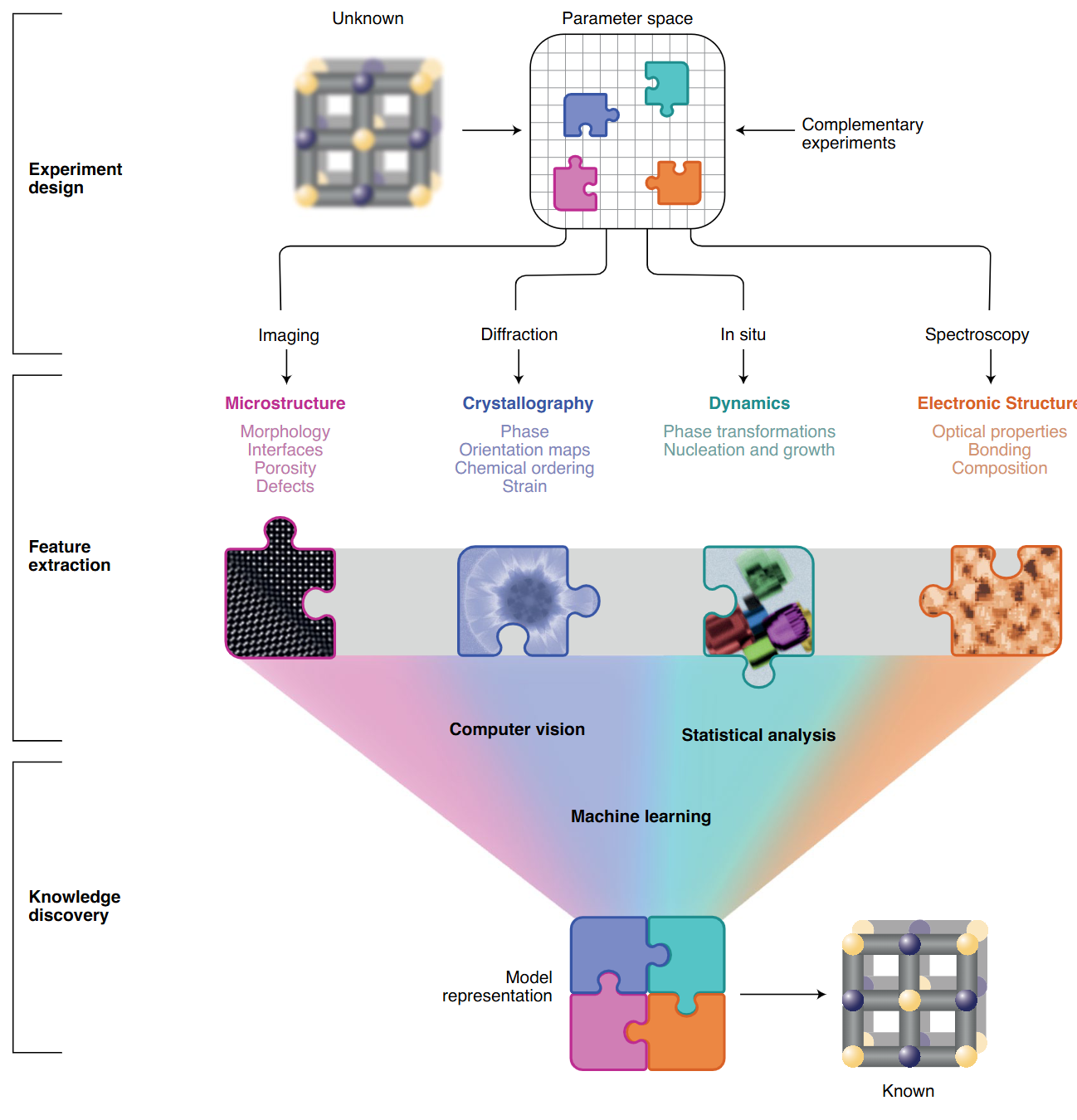
- Three nested layers turn unknown samples → quantifiable descriptors
- Experiment design
- Feature extraction
- Knowledge discovery
- Experiment design
- Open, interoperable control + AI links all layers into a virtuous cycle.
① Experiment design (Fig 1 top)
- GPU-accelerated simulations predict detection limits & dose budgets before the first electron hits the sample.
- ML mines prior-work databases (future) to recommend optimal imaging / spectroscopy modes in real time.
- Outcome: fewer trial-and-error sessions; cost & time savings.
② Feature extraction (Fig 1 middle)
- Records complete data streams (e.g. 4D-STEM diffraction cubes) for flexible post-processing
- Combines complementary modalities to overcome projection & damage artefacts.
- Requires automation and low-level access for batch surveys & in-situ studies.
③ Knowledge discovery (Fig 1 bottom)
- AI/ML trained on physical models classifies multidimensional signals → structure, bonding, dynamics.
- FAIR data standards and open repositories enable meta-analysis & reproducibility.
- Vision: adaptive microscopy where data choose the next experiment step on-the-fly.
Detectors drive the data deluge (Figure 2 a)
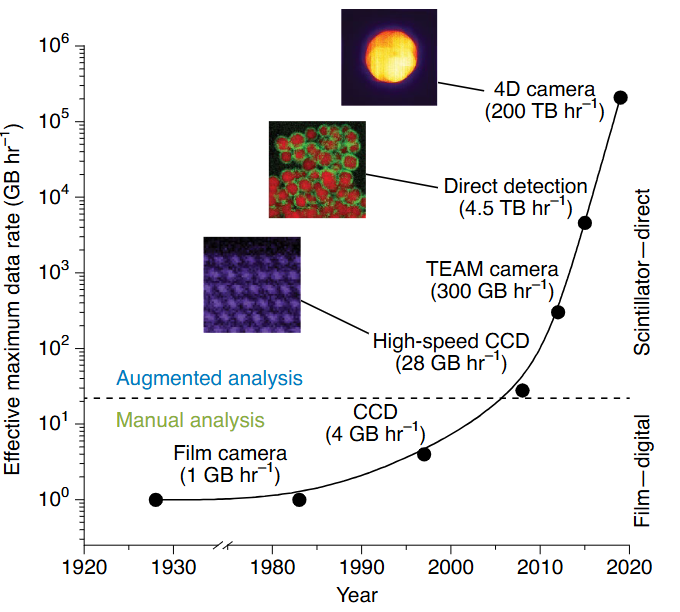
- From film (1 GB h⁻¹) to 4D pixelated cameras (200 TB h⁻¹) – a 10⁸× leap in two decades.
- Computing & storage must scale in lock-step; edge processing at the microscope becomes essential.
Workflow evolution (Figure 2 b)
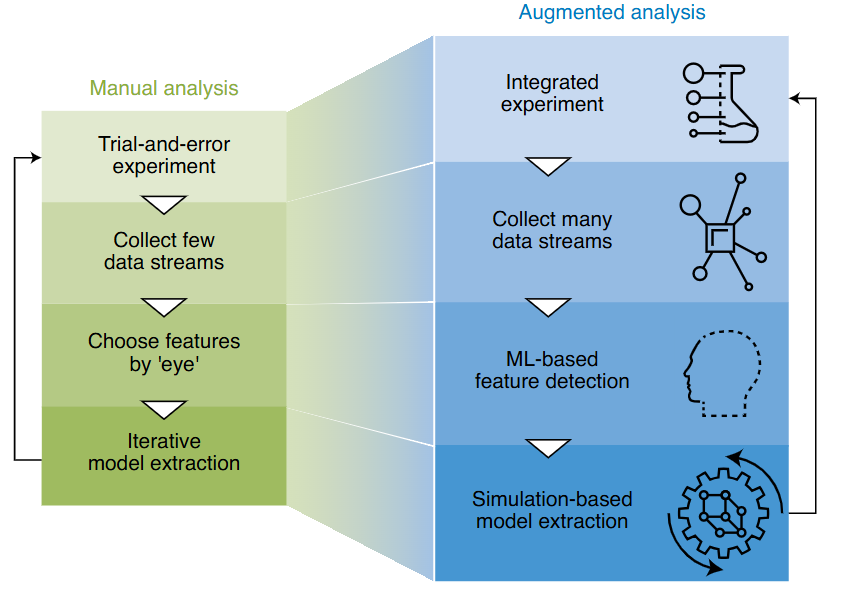
- Manual: choose features “by eye”, serial data, iterative models.
- Augmented: collect many data streams, ML finds features, simulation-based model extraction.
- Integrated experiment control enables closed-loop, crowd-sourced materials discovery.