Data Science for Electron Microscopy
Week 3: Linear algebra & PCA you actually need




Projection: the core operation
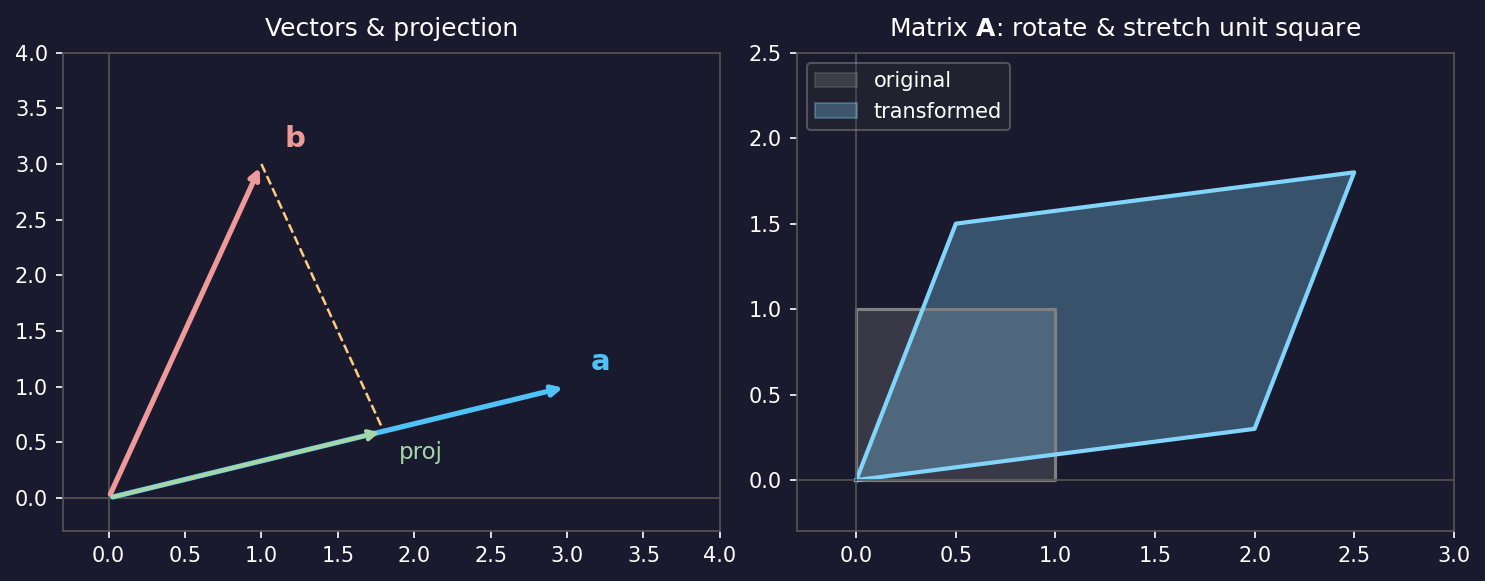
- Scalar projection of \(\mathbf{b}\) onto unit vector \(\hat{\mathbf{a}}\): \(c = \hat{\mathbf{a}}^T \mathbf{b}\).
- Vector projection: \(\text{proj}_{\mathbf{a}} \mathbf{b} = c \, \hat{\mathbf{a}}\).
- The residual \(\mathbf{b} - \text{proj}_{\mathbf{a}}\mathbf{b}\) is perpendicular to \(\mathbf{a}\).
- This decomposition — “how much lies along \(\mathbf{a}\)?” — is what PCA does in every direction.
Matrices as geometric transformations
![]()
- A matrix \(\mathbf{A}\) maps every vector \(\mathbf{x}\) to a new vector \(\mathbf{y} = \mathbf{Ax}\).
- Geometrically: \(\mathbf{A}\) rotates, stretches, and (for non-symmetric \(\mathbf{A}\)) shears space.
- The data matrix \(\mathbf{X} \in \mathbb{R}^{N \times D}\): \(N\) spectra (rows), each with \(D\) energy channels (columns).
- One row = one spectrum = one point in \(\mathbb{R}^D\).
- Convention for this week: observations in rows, features in columns.
The data matrix: EM spectra as points in high-D space
- Each EELS spectrum \(\mathbf{x}_i \in \mathbb{R}^{1024}\) is a point in 1024-D space.
- The cloud of \(N\) spectra occupies only a tiny corner of that space — most directions are empty.
- Intrinsic dimensionality: if a sample has \(K\) distinct chemical phases, the spectra approximately lie on a \(K\)-dimensional subspace.
- Key intuition: for a two-phase sample, all spectra are linear combinations of two end-members → they lie on a 2-D plane inside \(\mathbb{R}^{1024}\).
- PCA finds and extracts that plane.
SVD: the rotate–stretch–rotate decomposition
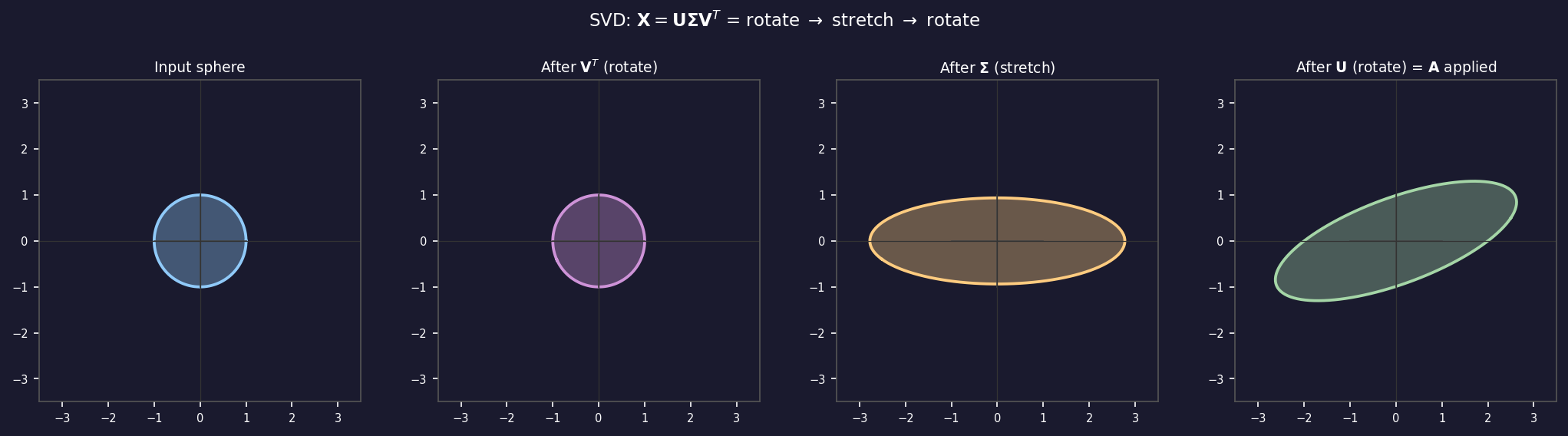
- Any matrix \(\mathbf{X}\) (data matrix or otherwise) can be written as: \[\mathbf{X} = \mathbf{U} \boldsymbol{\Sigma} \mathbf{V}^T.\]
- \(\mathbf{V}\): right singular vectors — input rotation (principal directions in feature space).
- \(\boldsymbol{\Sigma}\): singular values on the diagonal — how much each direction is stretched.
- \(\mathbf{U}\): left singular vectors — output rotation (scores in observation space).
The scree plot: how many components to keep?
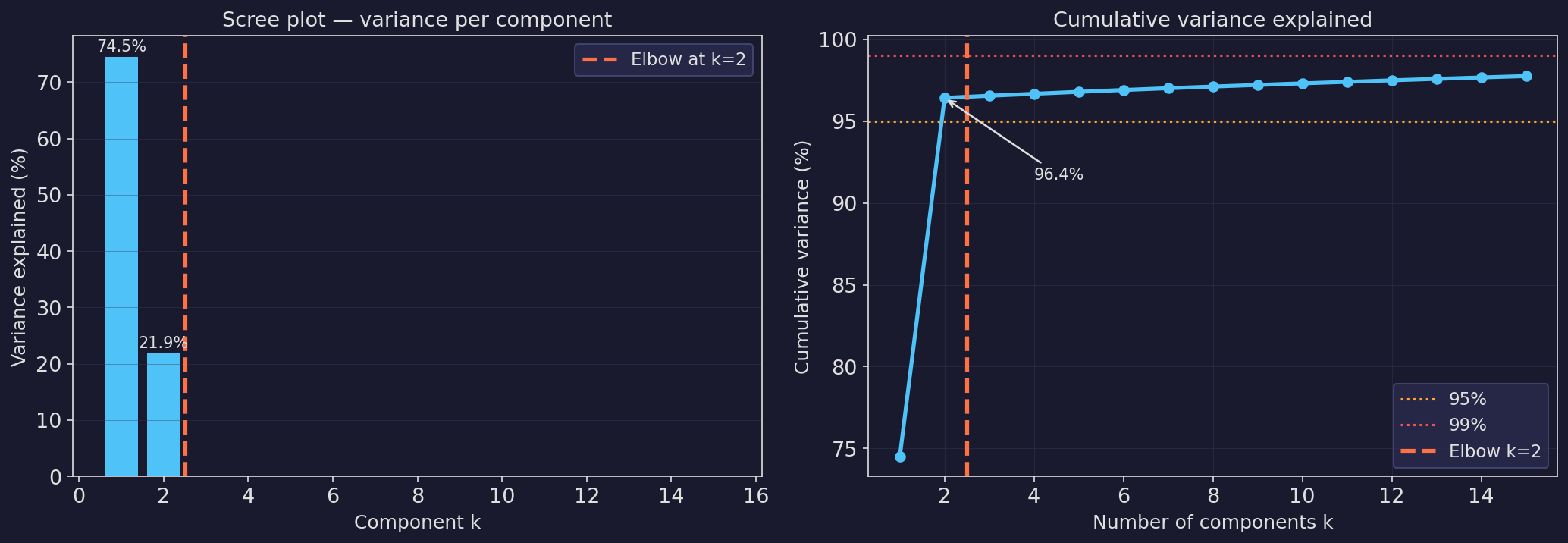
- Plot the variance explained \(\lambda_k / \sum_k \lambda_k\) (or \(\sigma_k^2\)) for each component.
- Signal components: steeply decreasing — each one captures a large portion of variance.
- Noise components: flat floor — all roughly equal variance (noise is isotropic).
- Elbow rule: keep components before the curve flattens.
- Cumulative variance: keep the smallest \(K\) such that \(\geq 95\%\) (or \(\geq 99\%\)) of variance is explained.
PCA denoising of EELS: the experiment
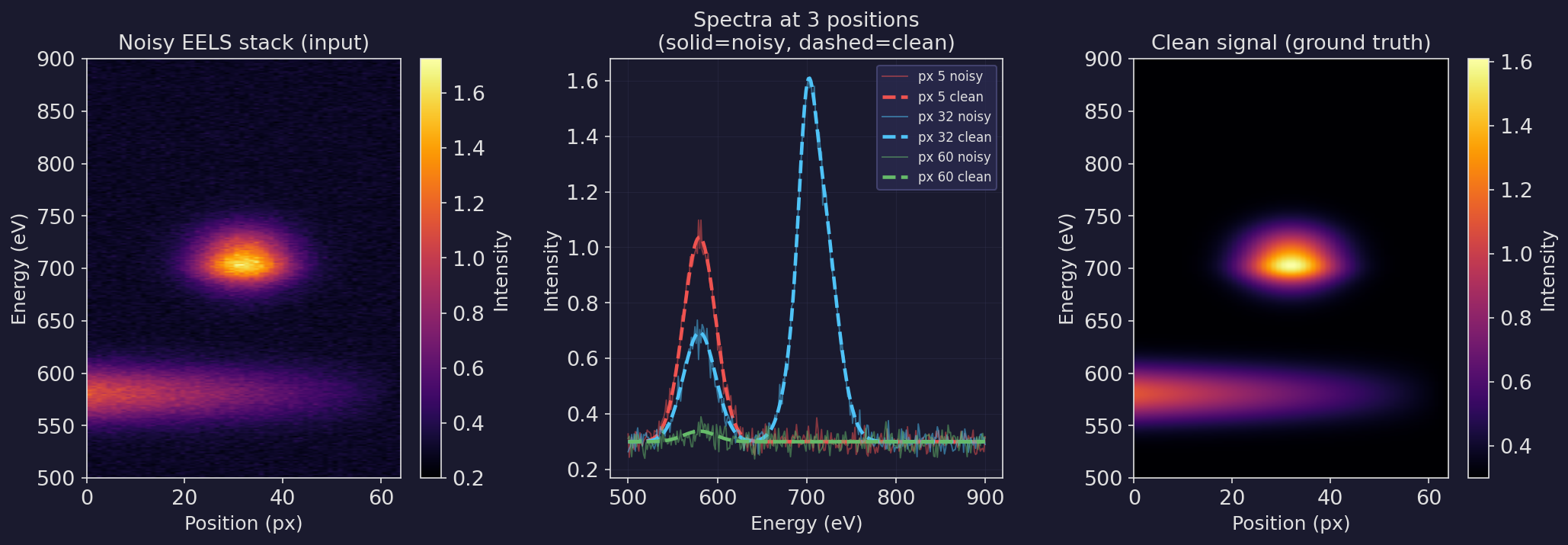
- Setup: 64-pixel × 300-channel synthetic EELS line scan.
- Two latent components: Fe-L edge (~710 eV) dominant in the centre; Cr-L edge (~580 eV) dominant at the edges.
- Noise: Poisson (scale = 500 counts); realistic low-dose EM conditions.
- Goal: recover the clean spectra from the noisy stack using PCA truncation.
- Signal is low-rank! Only 2 true latent components → data matrix has rank ≤ 2.
PCA denoising: reconstruction with k components
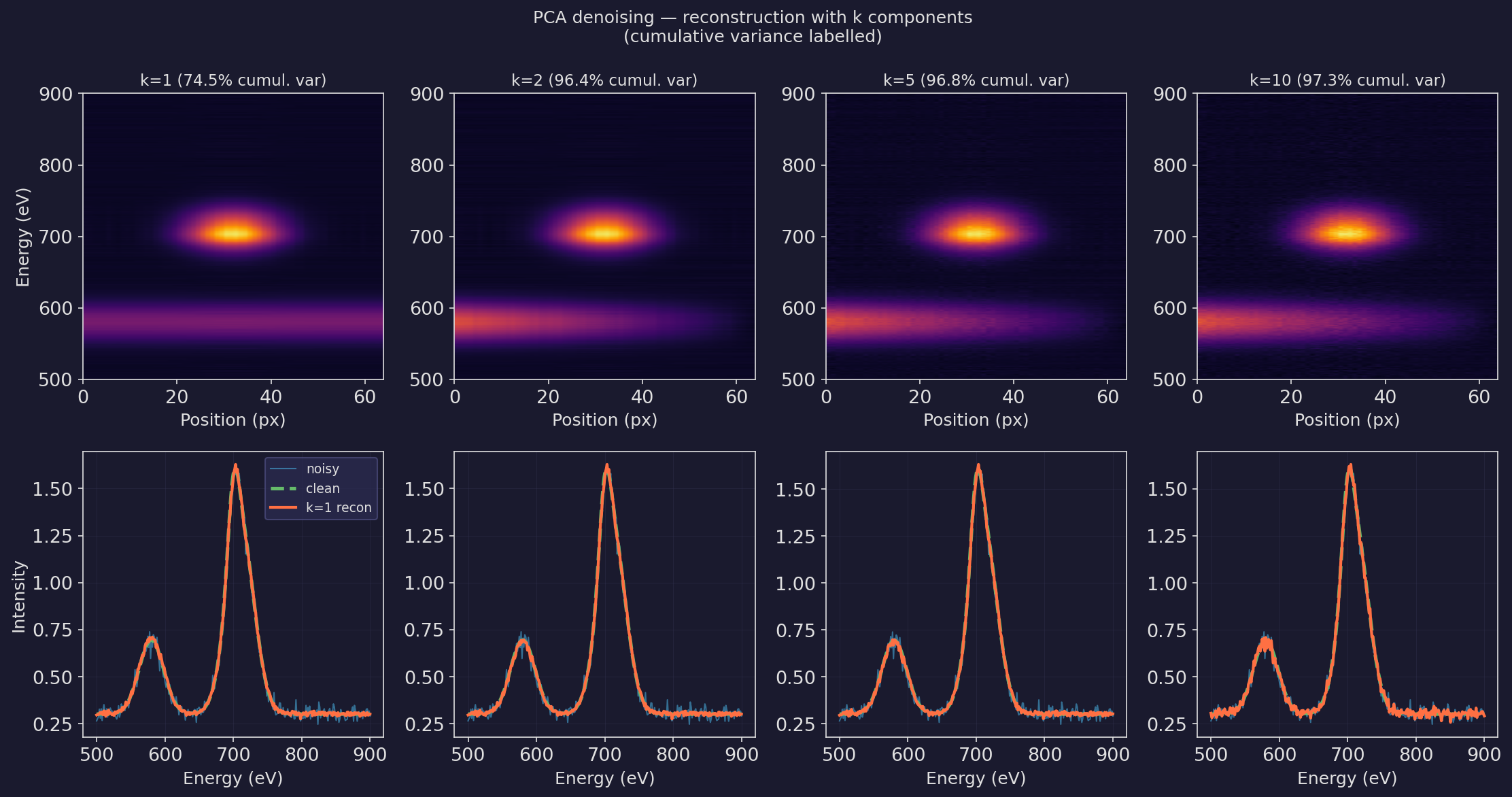
- k = 1: over-denoised — missing the Cr component; systematic error.
- k = 2: near-perfect — recovers both chemical components; smooth and accurate.
- k = 5: slightly under-denoised — residual noise from 3 noise components added back in.
- k = 10: significantly under-denoised — many noise components included.
- Optimal k = 2 matches the scree-plot elbow. Not coincidence — the elbow marks where truncation switches from “removing noise” to “adding noise.”
Eigen-spectra: the spectral shapes of variation
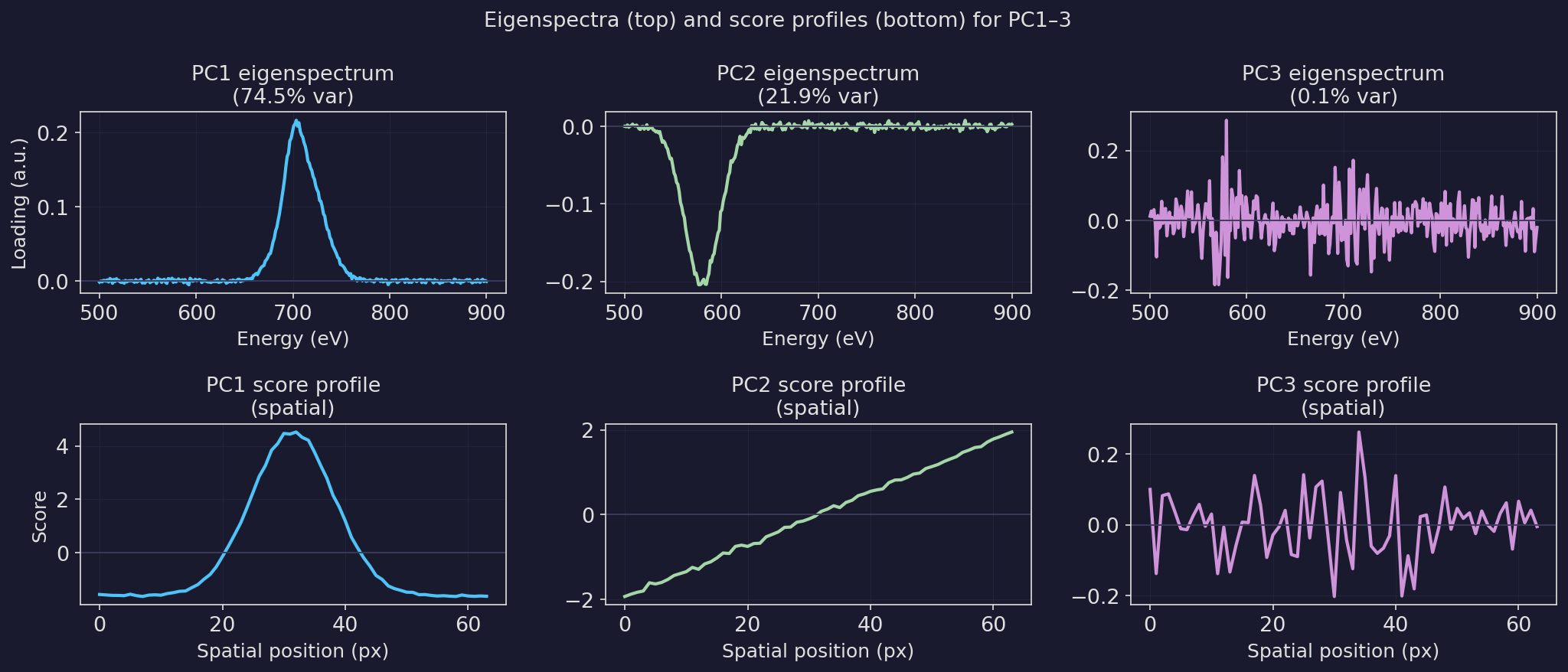
- PC1 eigenspectrum: the direction of maximum variance — here dominated by the Fe-L edge shape.
- PC2 eigenspectrum: second direction — captures Cr-L contrast (positive Cr-L, negative Fe-L background).
- PC3+ eigenspectrum: no recognisable peaks — random noise pattern.
- Note: eigenspectra can have negative values (they are basis vectors, not physical spectra).
- Physical spectra are reconstructed as: \(\hat{\mathbf{x}}_i = \bar{\mathbf{x}} + c_{i1}\mathbf{v}_1 + c_{i2}\mathbf{v}_2\).
Ill-conditioning: when correlated features cause trouble
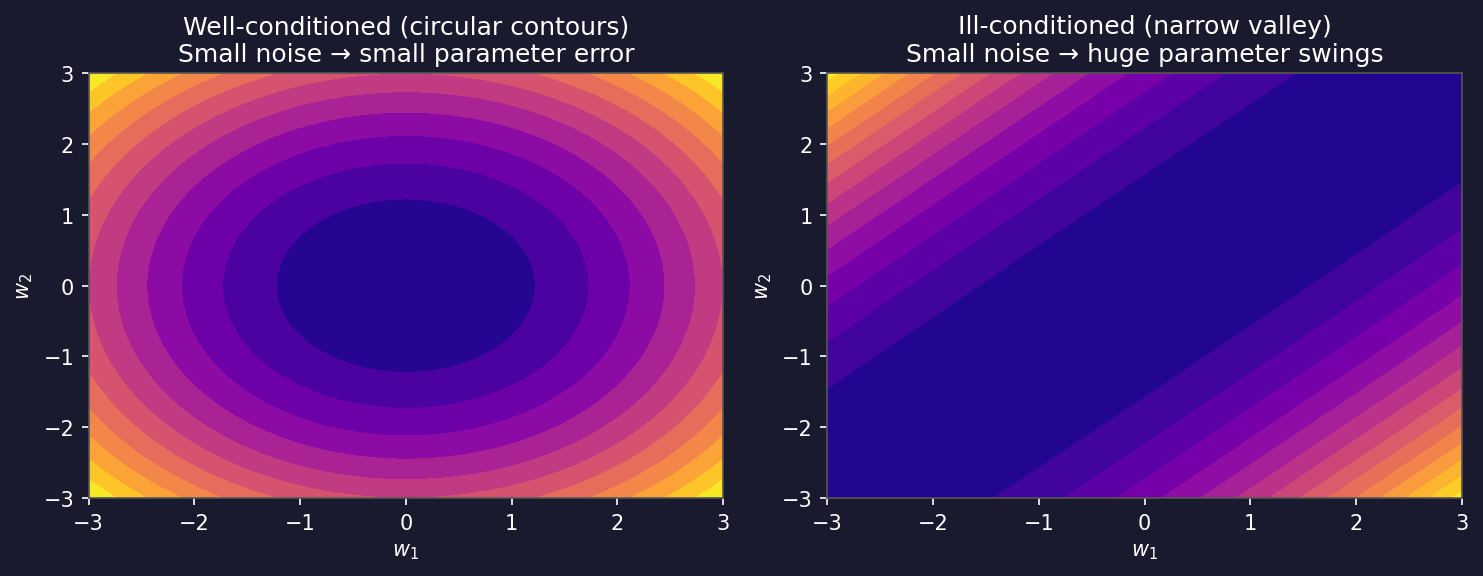
- Condition number \(\kappa = \sigma_\text{max}/\sigma_\text{min}\) — ratio of largest to smallest singular value.
- Well-conditioned: \(\kappa \approx 1\) (circular contours). Ill-conditioned: \(\kappa \gg 1\) (narrow valley).
- Cause: highly correlated features → data matrix nearly singular → small \(\sigma_\text{min}\) → large \(\kappa\).
- Effect: a tiny change in the data produces huge, unstable swings in the estimated parameters Murphy, Kevin P., (2012).