Data Science for Electron Microscopy
Week 4: Regression, gradient descent & honest validation




MAE and Huber — robust alternatives
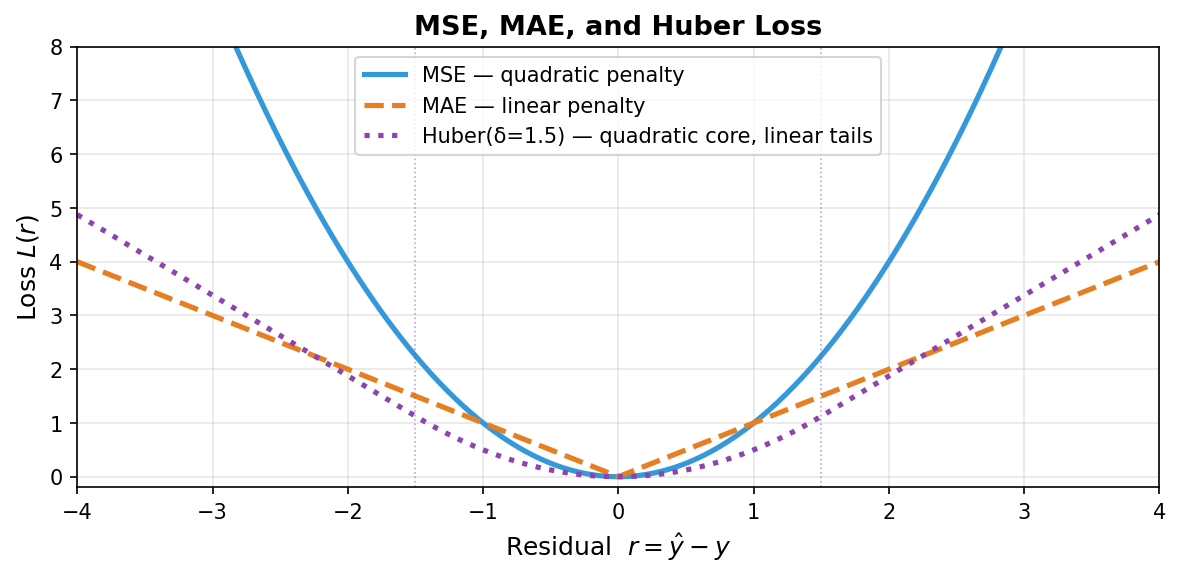
- MAE: \(L = |\hat{y} - y|\) — linear penalty, robust to outliers. Probabilistic identity: MLE under Laplacian residuals. Caveat: non-differentiable at zero → sub-gradient methods needed.
- Huber: quadratic inside \(|r| \le \delta\), linear outside. Best of both: smooth optimisation where residuals are small, robust to spikes. Standard tool when most EM crops are clean but occasional detector artefacts occur.
- Rule of thumb: start with MSE; switch to Huber if residual plots show heavy tails.
The loss landscape — a bowl in weight space
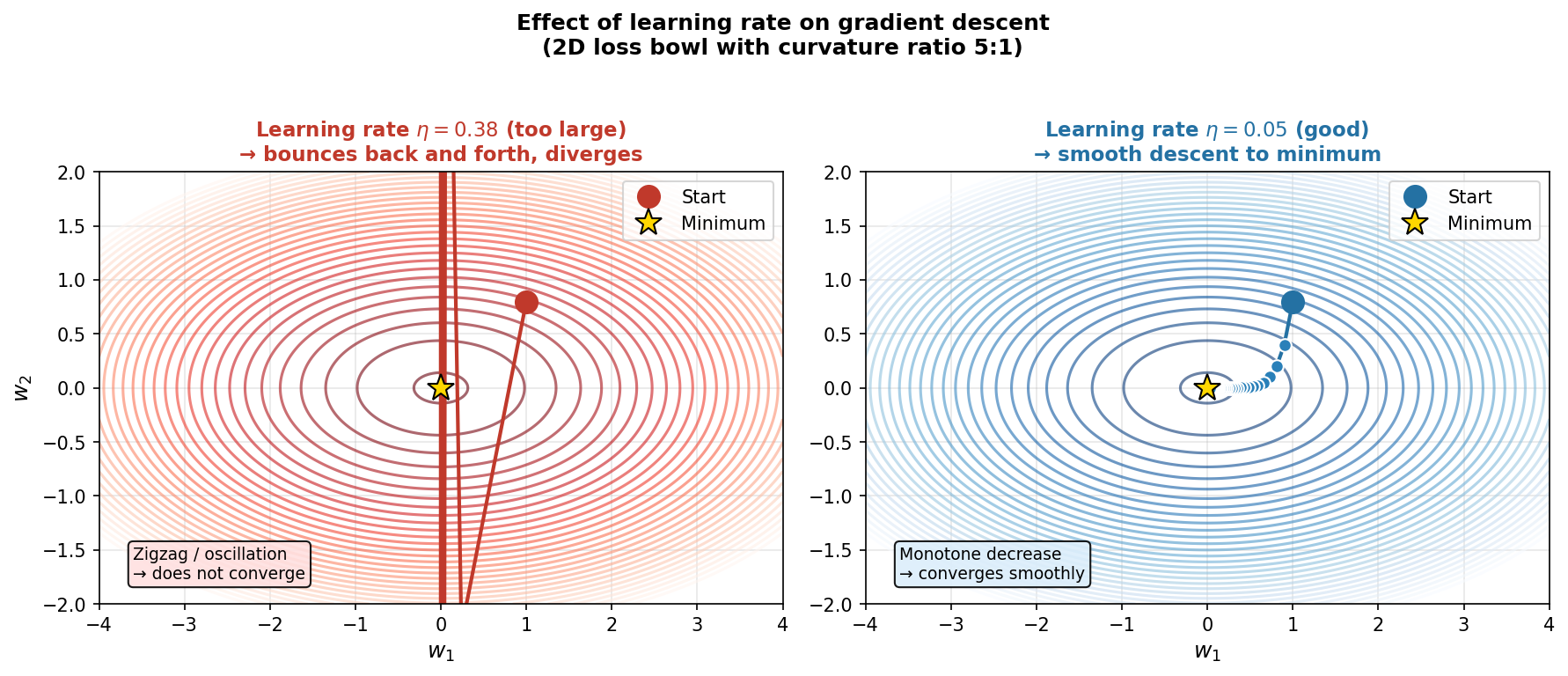
- Loss landscape: the surface \(\hat{R}(\mathbf{w})\) over all possible weight vectors \(\mathbf{w}\).
- For MSE linear regression: a convex bowl — one global minimum, no local traps.
- Gradient descent update: \(\mathbf{w}_{t+1} = \mathbf{w}_t - \eta\,\nabla_\mathbf{w}\hat{R}(\mathbf{w}_t)\).
- \(\eta\) = learning rate — the step size along the negative gradient.
- The contour lines are level sets of the loss; GD crosses them at right angles (steepest descent).
Learning rate — too small, just right, too large
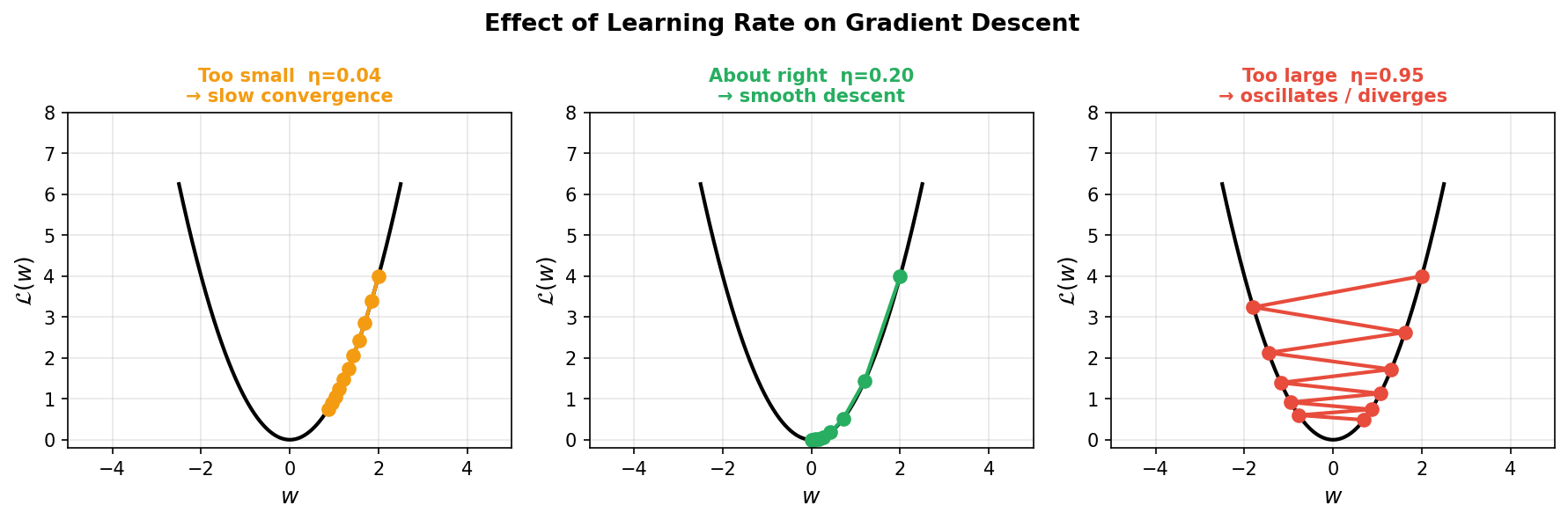
- Too small (\(\eta \ll 1/L\), \(L\) = Lipschitz constant of gradient): correct direction but tiny steps → converges in theory, but takes too long in practice.
- About right: loss decreases monotonically; convergence in tens to hundreds of steps.
- Too large (\(\eta > 2/L\)): overshoots the minimum repeatedly → oscillates or diverges.
- Rule of thumb: start at \(\eta = 0.01\)–\(0.1\), monitor the loss curve, reduce if it bounces.
Adam — the go-to optimiser
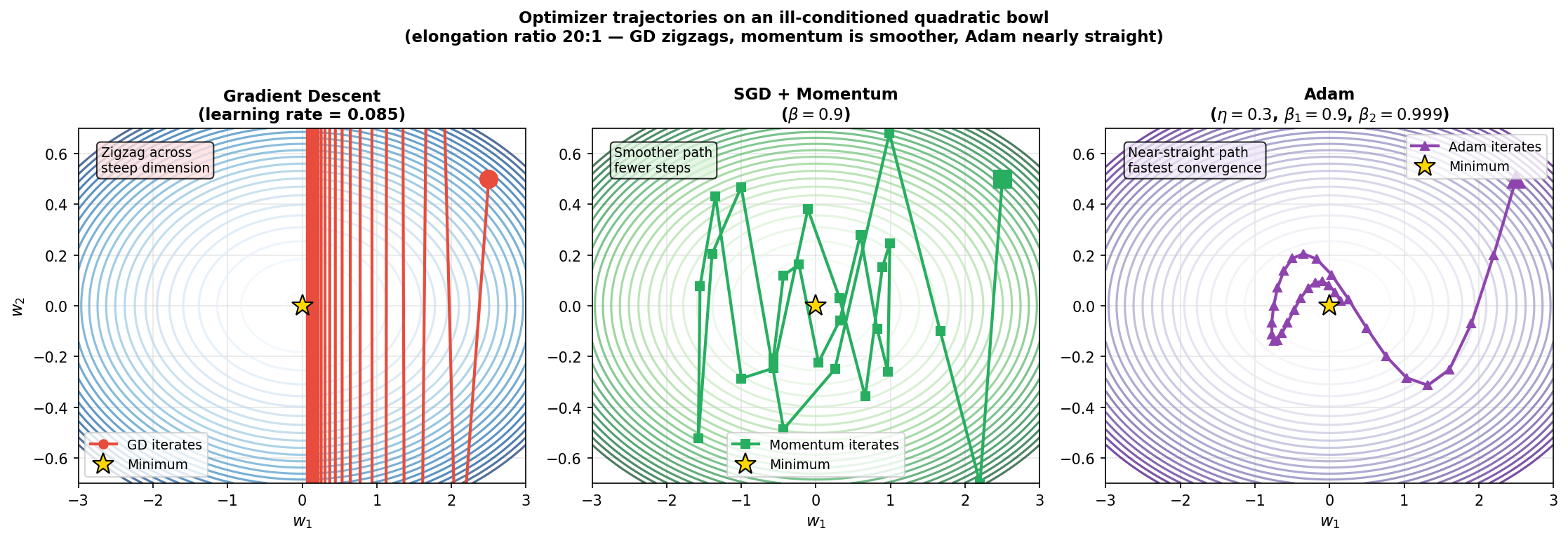
- Adam: tracks both the gradient (momentum term \(\hat{\mathbf{v}}_t\)) and the squared gradient (adaptive scaling \(\hat{\mathbf{s}}_t\)): \[\mathbf{w}_t \leftarrow \mathbf{w}_{t-1} - \frac{\eta\,\hat{\mathbf{v}}_t}{\sqrt{\hat{\mathbf{s}}_t} + \epsilon}\]
- Adaptive scaling: each parameter gets its own effective learning rate — large for slowly-updated parameters, small for fast ones.
- Typical hyperparameters: \(\eta = 0.001\), \(\beta_1 = 0.9\) (momentum), \(\beta_2 = 0.999\) (RMS), \(\epsilon = 10^{-8}\).
- For most EM projects: use Adam at its default settings unless you have a specific reason to change them.
Overfitting and underfitting
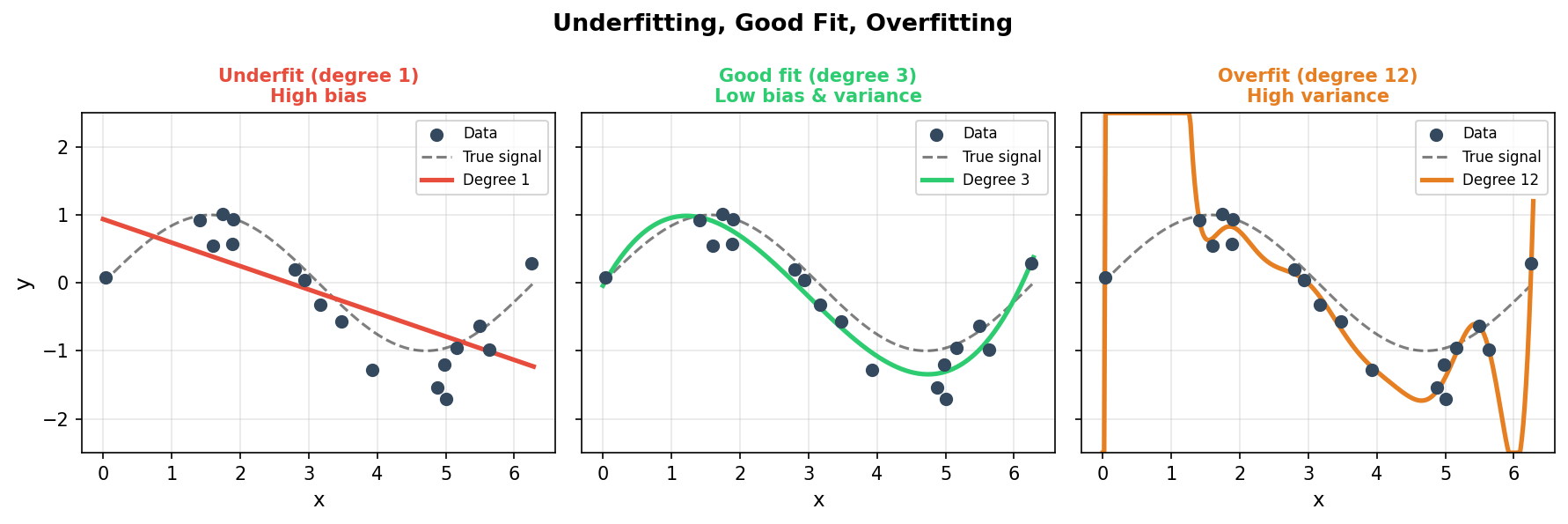
- Underfit (high bias): model too simple — cannot capture the pattern. Training and test errors are both high.
- Good fit (balanced): training error ≈ test error; the model captures the signal, not the noise.
- Overfit (high variance): model too flexible — memorises training noise. Training error ≈ 0, test error ≫ 0.
- In EM: a degree-12 polynomial fitted to 18 noisy data points passes through every point but predicts wildly on new samples.
Why a held-out test set is sacred

- Train set: fit model parameters (\(\mathbf{w}\)).
- Validation set: tune hyperparameters (\(\lambda\), architecture, learning rate). Can look at this repeatedly.
- Test set: final, one-time evaluation — reports the honest generalisation score.
- Rule: you may never use test-set information to change any modelling decision. Once you look at the test score and adjust your model, it becomes a second validation set, not a test set.
K-fold cross-validation
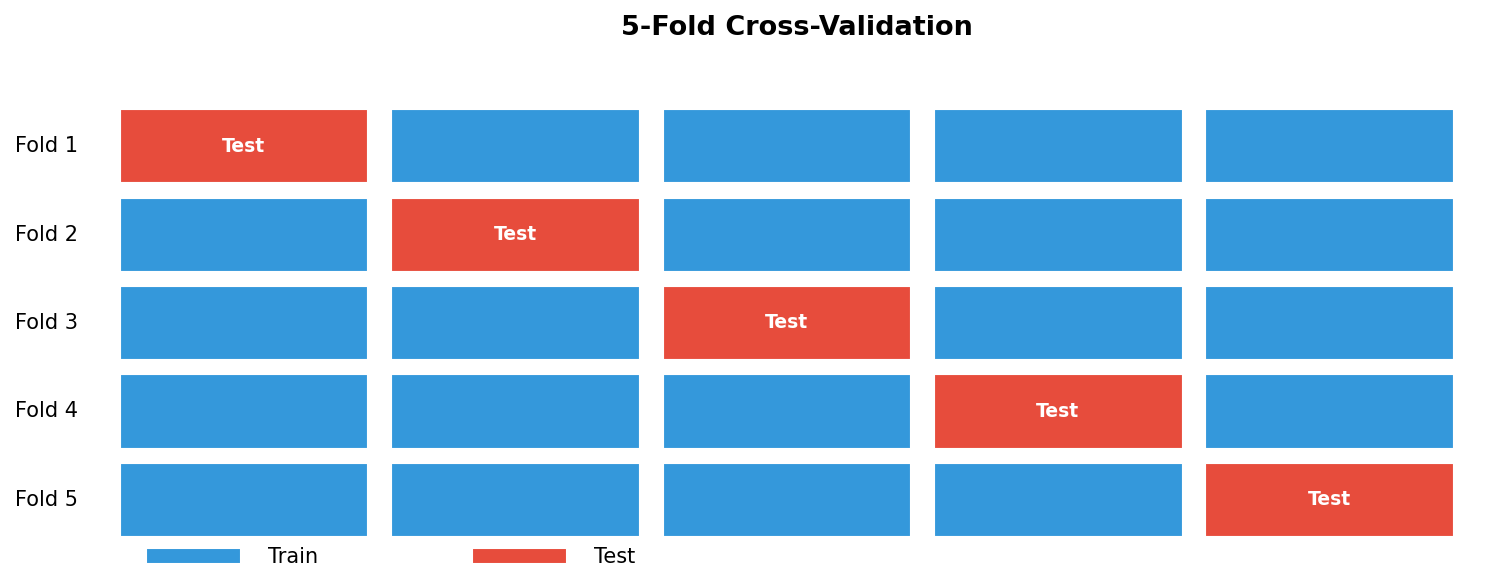
- Recipe: split data into \(k\) equal folds. For \(i=1,\ldots,k\): train on all folds except \(i\); test on fold \(i\). Report \(\overline{\text{MSE}} \pm \text{std}(\text{MSE})\).
- Every data point contributes to both training and testing — no waste.
- The std tells you how stable the estimate is across splits.
- Defaults: \(k=5\) for compute-bound situations; \(k=10\) for moderate datasets (\(N \sim 10^3\)); \(k=N\) (LOOCV) for very small datasets (\(N < 30\), common in materials science).
- Cost: \(k\) trainings — skip for slow deep models; use repeated holdout with multiple seeds instead.
The EM leakage trap: crops from one specimen
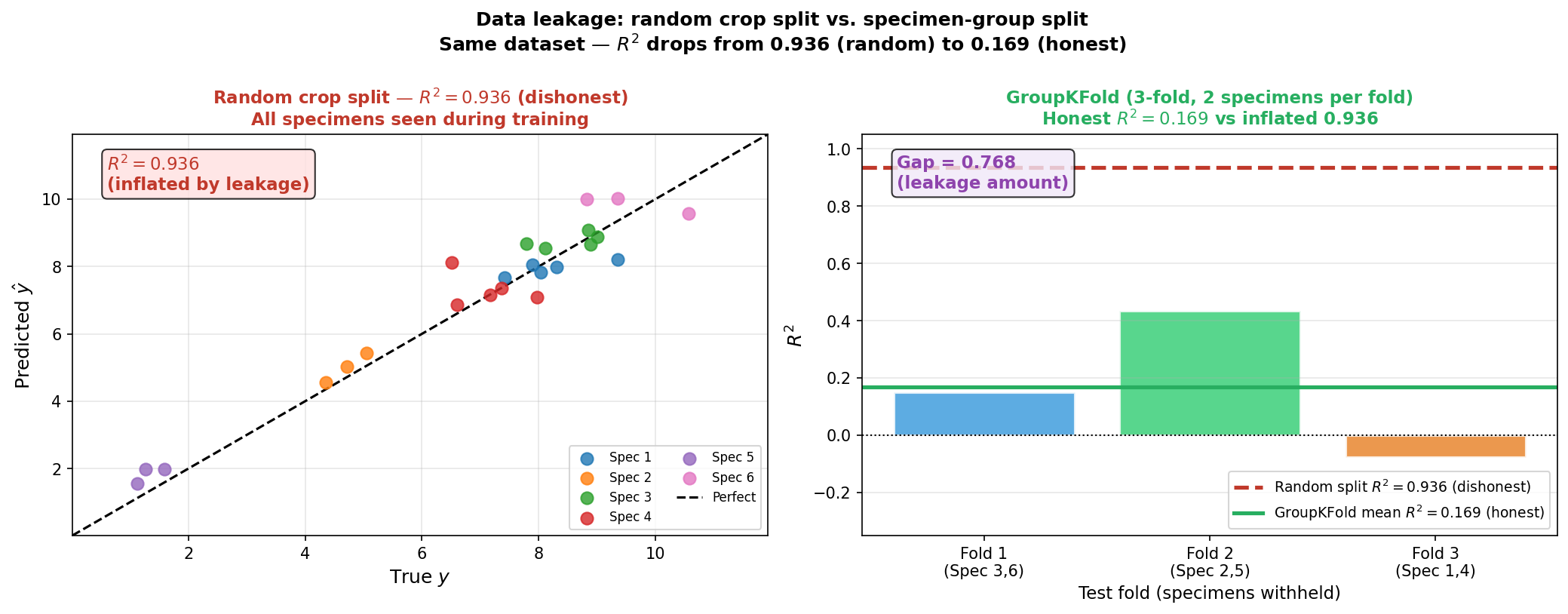
- The scenario: 6 EM specimens, 20 crops each — 120 training examples. A per-specimen property (e.g., composition, lattice parameter, stoichiometry) is the target \(y\).
- Random crop split (\(R^2 = 0.936\)): crops from Specimen 3 land in both train and test. The model learns “Specimen 3 looks like this” and predicts well on test crops — but it has memorised a specimen, not the property.
- 3-fold specimen-group split (mean \(R^2 = 0.169\)): entire specimen pairs are in test only. The model must generalise across specimen identities — the honest evaluation.
Regression metrics: MAE, RMSE, \(R^2\)
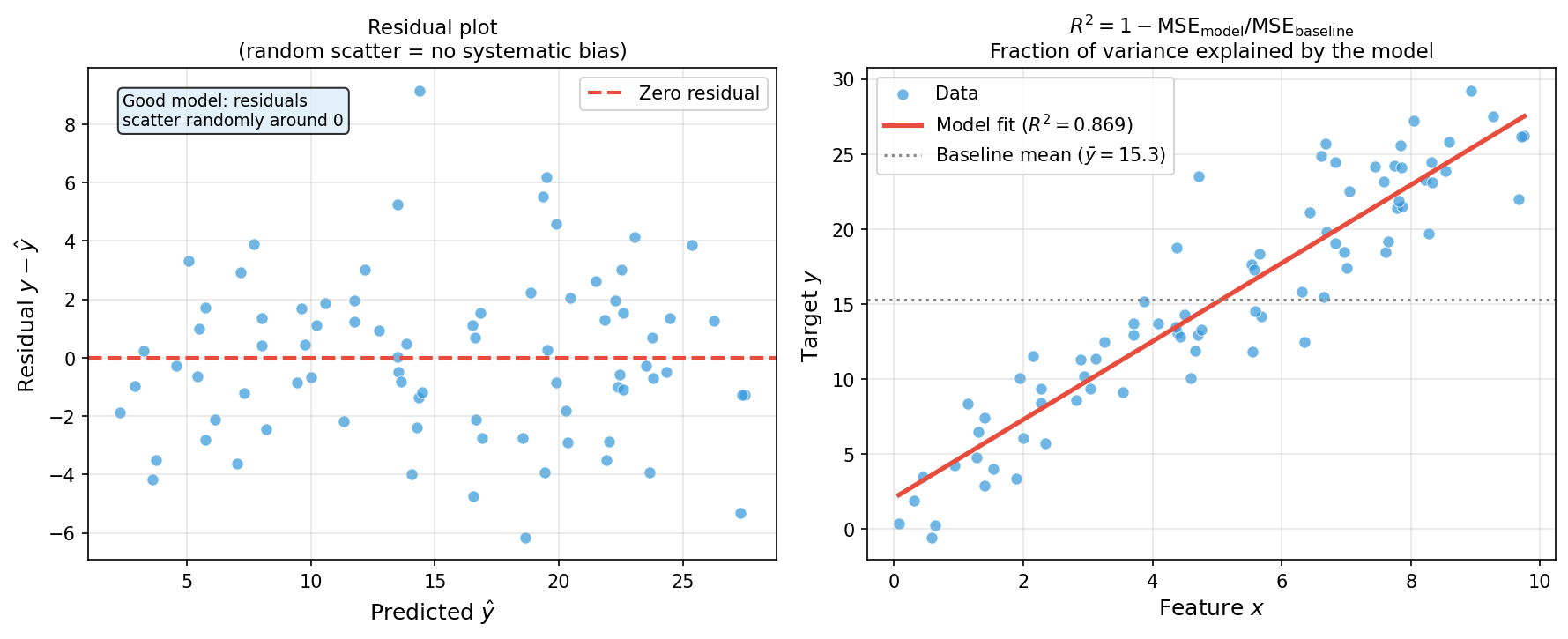
- \(\mathrm{MAE} = \frac{1}{n}\sum|y_i - \hat{y}_i|\) — in the same units as \(y\); robust to outliers.
- \(\mathrm{RMSE} = \sqrt{\tfrac{1}{n}\sum(y_i - \hat{y}_i)^2}\) — in the same units as \(y\); penalises large errors more.
- \(R^2 = 1 - \mathrm{MSE}_\text{model}/\mathrm{MSE}_\text{baseline}\) — fraction of variance explained; scale-free. \(R^2 = 1\): perfect. \(R^2 = 0\): no better than predicting \(\bar{y}\). \(R^2 < 0\): worse than baseline.
- Always report \(R^2\) on held-out data, not training data.
Classification and segmentation metrics
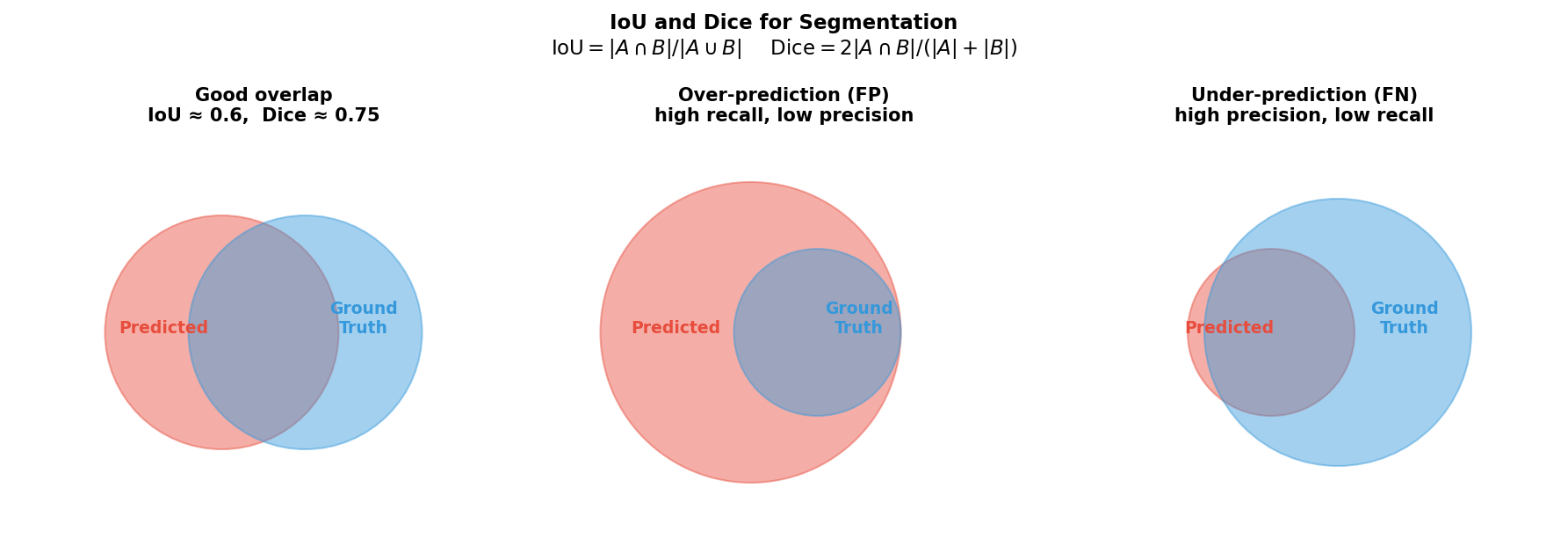
- Precision = TP / (TP + FP) — of what I called positive, how much was correct?
- Recall = TP / (TP + FN) — of what was truly positive, how much did I find?
- F1 = Dice = \(2 \cdot P \cdot R / (P + R)\) — harmonic mean; penalises lopsided precision/recall.
- IoU (Jaccard) = \(|A \cap B| / |A \cup B|\) — standard for object detection and segmentation.
- Rule: defect detection → maximise recall. Particle picking → balance via F1/Dice.
- \(\text{Dice} = 2\,\text{IoU}/(1 + \text{IoU})\); IoU is always ≤ Dice for the same prediction.