Data Science for Electron Microscopy
Week 6: CNNs for microscopy images




The parameter explosion: a concrete count
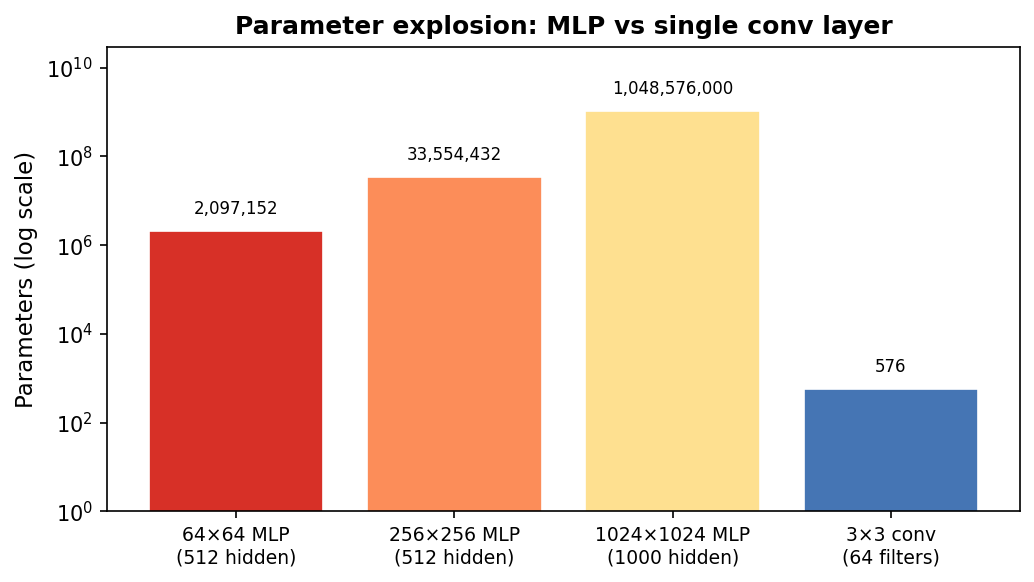
MLP parameter count vs a single convolutional layer for images of increasing size. Note the log scale. A 1024×1024 image with 1000 hidden neurons requires ~10⁹ weights; 64 conv filters of size 3×3 require only 576.
The sliding-window operation step by step

Two-dimensional cross-correlation (the operation CNNs actually use). The 3×3 kernel slides one position at a time. At each position, nine element-wise multiplications are summed to give one output value. The output grid records the detector response at every spatial location.
Convolution on a synthetic grain image
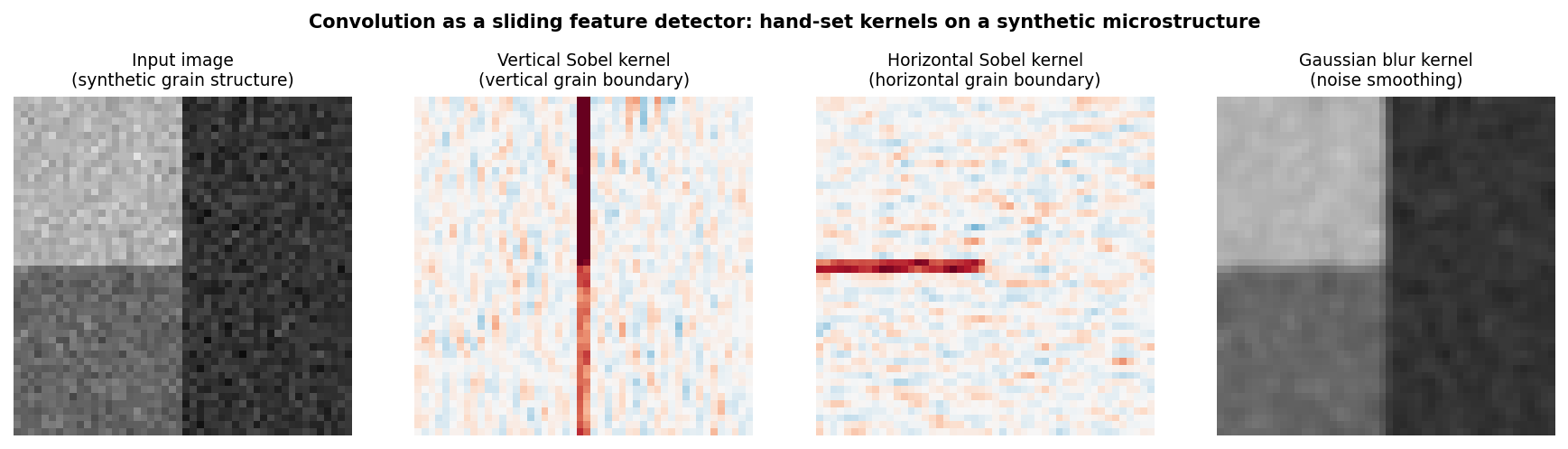
Convolution applied to a synthetic two-grain microstructure. Left: input image (two grains with different intensities, separated by vertical and horizontal boundaries). Centre-left: vertical Sobel kernel responds strongly at the vertical grain boundary. Centre-right: horizontal Sobel responds at the horizontal boundary. Right: Gaussian blur smooths noise. All kernels are 3×3; weights are hand-set, not trained.
Kernels as feature detectors

Three classic 3×3 kernels. Left: vertical Sobel — responds to left–right intensity changes. Center: horizontal Sobel — responds to top–bottom changes. Right: Laplacian — responds to any local intensity peak or boundary. Numbers are the kernel weights.
In a trained CNN, the network discovers these (and more complex) filters automatically from labelled examples — no manual kernel design needed.
Stride and padding: controlling output size
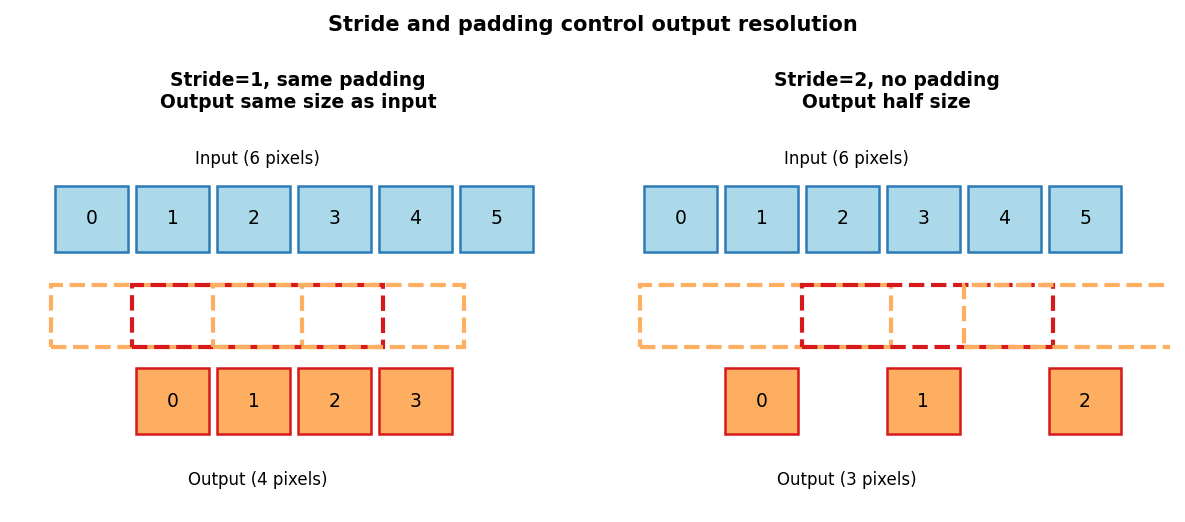
Stride=1 with same-padding (left): the kernel moves one pixel at a time and output is the same size as input. Stride=2 (right): the kernel skips every other position, halving spatial resolution.
- Padding (same): add zeros around the border → output size = input size. Standard in most segmentation architectures.
- Stride \(s\): move the kernel \(s\) pixels per step → output size \(\approx H/s\).
- A 3×3 kernel with padding=1, stride=1 keeps height and width: \(H_{out} = \lfloor(H+2-3)/1\rfloor+1 = H\).
Weight sharing: the key efficiency principle
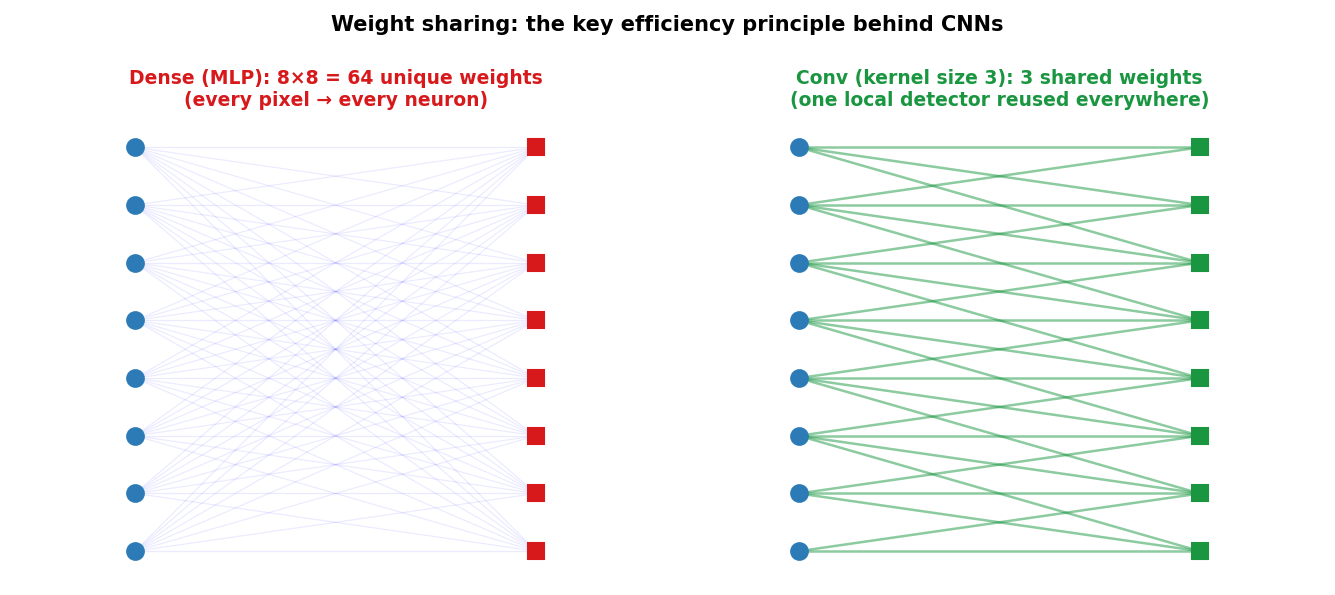
Dense layer (left): every input node connects to every output node — \(n_{in} \times n_{out}\) unique weights. Conv layer (right): the same 3-weight kernel connects each output node to only a local neighborhood of inputs — 3 shared weights total (for the 1-D case shown).
Pooling: summarising local responses

Max-pooling with a 2×2 window. For each non-overlapping 2×2 region, keep the maximum value. Spatial resolution halves in each dimension; channel count is unchanged.
- Max pooling: keep the strongest activation in each local window. Answers: “did this feature appear here?”
- Average pooling: compute the mean. Answers: “how strongly was this feature present overall?”
- No learned parameters — purely deterministic aggregation.
- \(2\times2\) max-pool: halves height and width, doubles the effective receptive field of later layers.
Receptive fields: how much context does one neuron see?
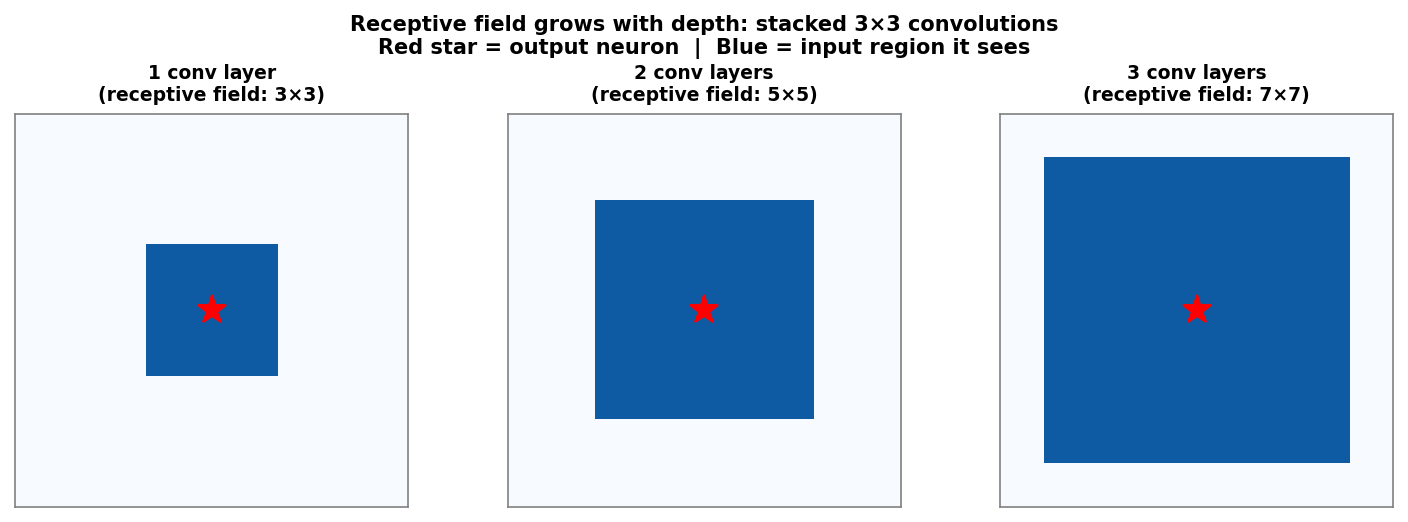
Receptive field of a single output neuron grows with depth. One 3×3 conv layer: 3×3 input region. Two stacked layers: 5×5 region. Three layers: 7×7 region. Red star marks the output neuron; blue region is its receptive field in the input image.
Feature hierarchy: edges → motifs → structures → properties
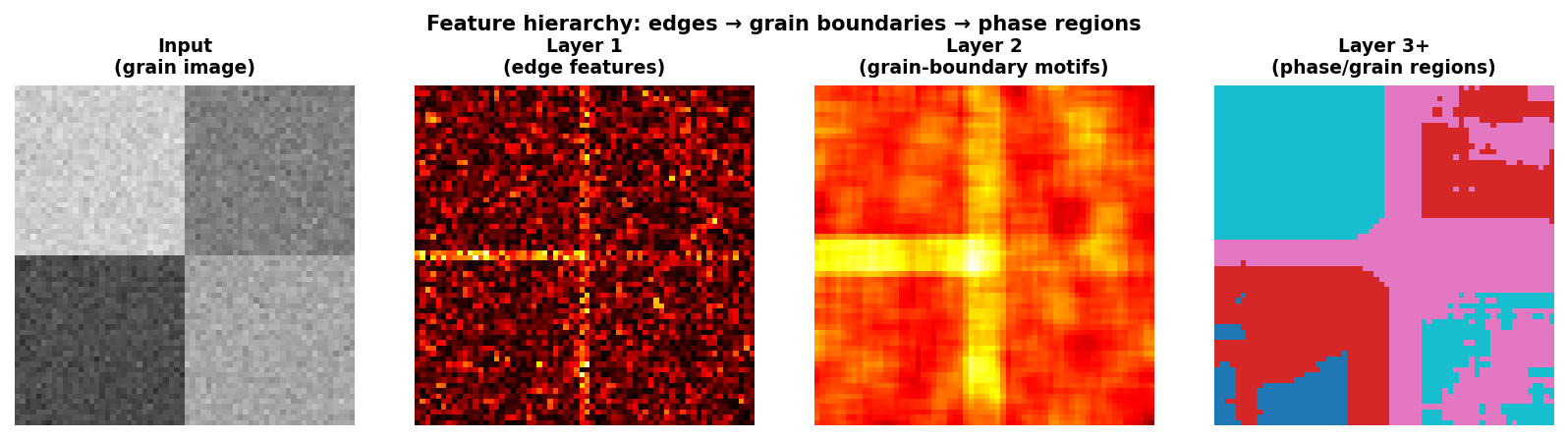
Feature hierarchy on a synthetic grain microstructure. Input (left): two-grain image with boundaries. Layer 1 (centre-left): Laplacian-like edge features highlight all boundaries. Layer 2 (centre-right): neighbourhood-level grain-boundary motifs. Layer 3+ (right): coarse phase/grain-region labels.
CNN architectures in one breath: the arc from 1998 to 2015
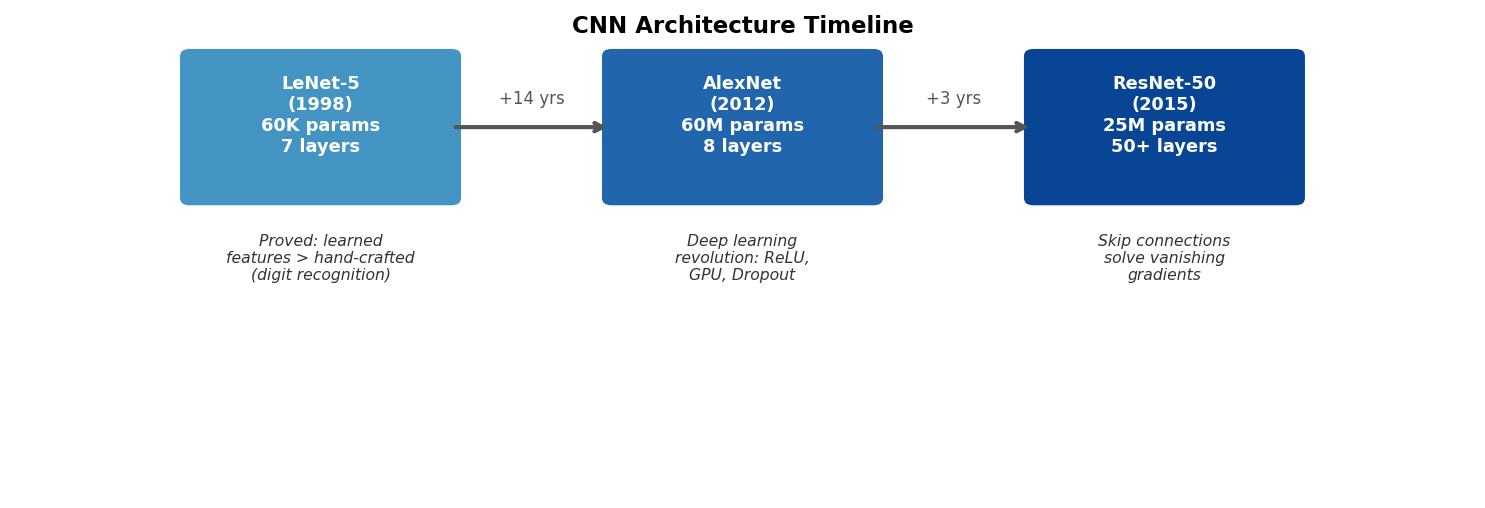
Timeline from LeNet (1998) to AlexNet (2012) to ResNet (2015). Each box states the year, approximate parameter count, depth, and key innovation. Read left to right as increasing depth, scale, and capability.
ResNet: skip connections solve vanishing gradients He, Kaiming et al., (2016)
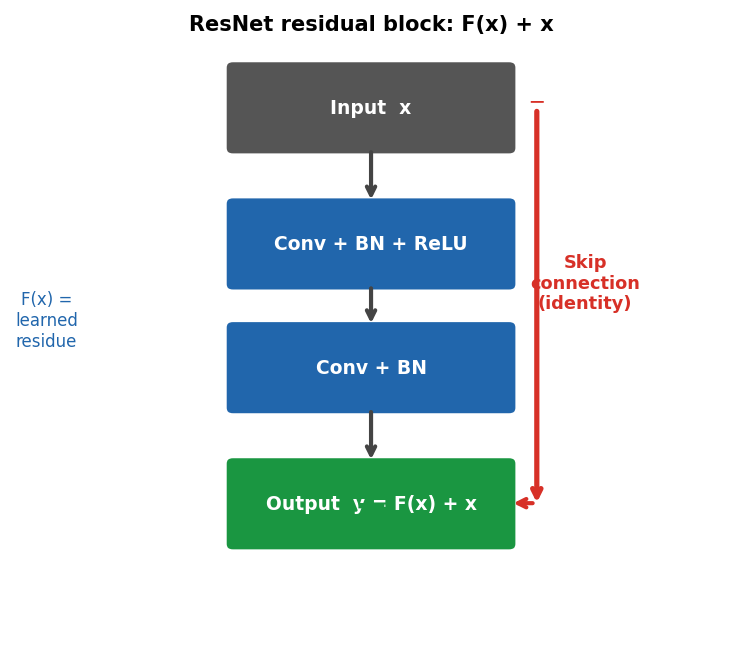
ResNet residual block. The main path learns a residual function F(x) = y − x. The skip connection adds the input x directly to the output. During backpropagation, gradients flow through the skip path without attenuation — solving the vanishing gradient problem for 50+ layer networks.
\[\mathbf{y} = F(\mathbf{x}) + \mathbf{x}\] Instead of learning the target \(\mathbf{y}\), learn the residual \(F(\mathbf{x}) = \mathbf{y} - \mathbf{x}\).
U-Net: encoder–decoder for segmentation Ronneberger, Olaf et al., (2015)
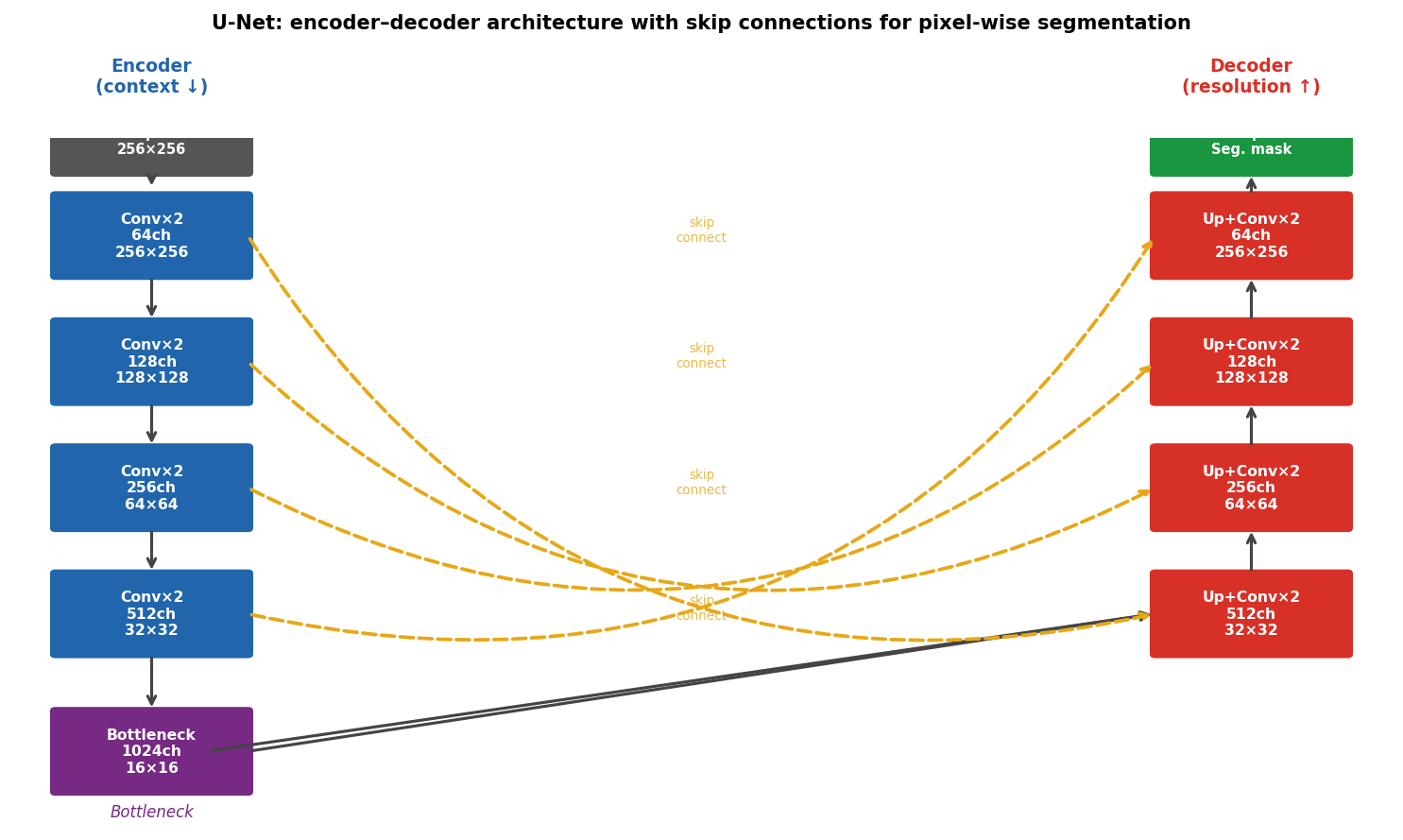
U-Net architecture. Left column (blue): encoder — successive Conv+Pool blocks extract features while halving spatial resolution and doubling channel count. Right column (red): decoder — successive upsample+Conv blocks restore spatial resolution. Yellow dashed arrows: skip connections concatenate encoder features into corresponding decoder levels.
EM case study 1: Au nanoparticle phase segmentation

U-Net applied to TEM images of Au nanoparticles on an amorphous support. Left: input TEM image (representative Au-nanoparticle-on-amorphous-support TEM segmentation task). Centre: ground-truth binary mask (crystalline=bright, amorphous=dark). Right: U-Net prediction — pixel-wise classification matching the ground truth closely.
U-Net TEM segmentation: published results

U-Net segmentation of TEM images from a published materials science application. The encoder–decoder with skip connections accurately reproduces phase boundaries, even in noisy low-dose images where the boundary is only 1–3 pixels wide.
EM case study 2: Grain boundary segmentation from synthetic training data

Grain boundary segmentation pipeline. Left: synthetic Voronoi grain image (used for CNN training). Centre: automatically generated ground-truth grain labels (free — no expert annotation). Right: U-Net predicted grain boundaries from the output mask.
Synthetic-to-real transfer: Voronoi → SEM grain maps

CNN grain segmentation applied to a real SEM polycrystal image. The network was trained only on synthetic Voronoi grain images (with perfect free labels), yet it correctly identifies grain boundaries in the real SEM image — demonstrating that the topological signature of boundaries transfers from synthetic to real data.