Data Science for Electron Microscopy
Week 7: Beating small & expensive data




The labelled-data gap: a three-order-of-magnitude problem
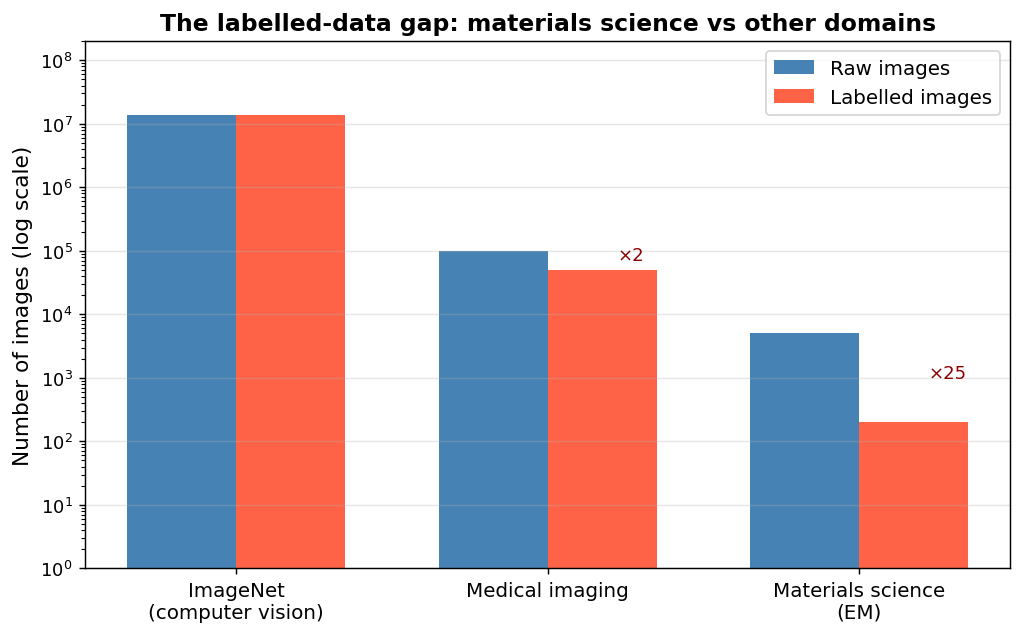
Labelled image counts across domains. ImageNet: 14 million images, crowdsourced labels in seconds. Medical imaging: tens of thousands, expert radiologists. Materials science / EM: 50–500 images, PhD microscopists spending hours per image Holm, Elizabeth A. et al., (2020); Sandfeld, Stefan et al., (2024). Three orders of magnitude separate us from where standard deep learning was designed to work.
Small data → fast overfitting
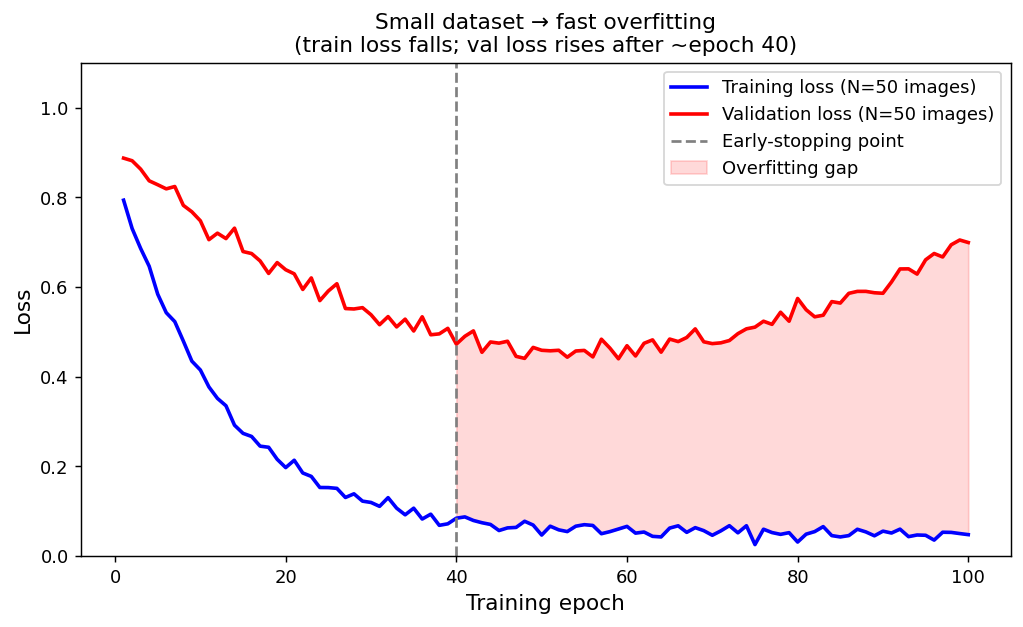
Training and validation loss for a CNN fine-tuned from scratch on 50 EM images. Training loss falls monotonically; validation loss starts rising around epoch 40 — the model is memorising the training images, not learning to generalise. The gap is the overfitting region.
Augmentation: encoding physical invariances

Six augmented views of the SAME synthetic grain microstructure. All six panels show the same Voronoi grain layout (same polygonal grains, same topology) transformed in different ways. Top row: original, 90° rotation (valid for equiaxed grains), horizontal flip (valid — no polarity). Bottom row: brightness jitter (valid — structural label), Poisson noise (simulates low dose), vertical flip (invalid — breaks a surface gradient if present). Each valid transform is a claim that the physics has a symmetry.
Physically-invalid augmentations: the materials gate
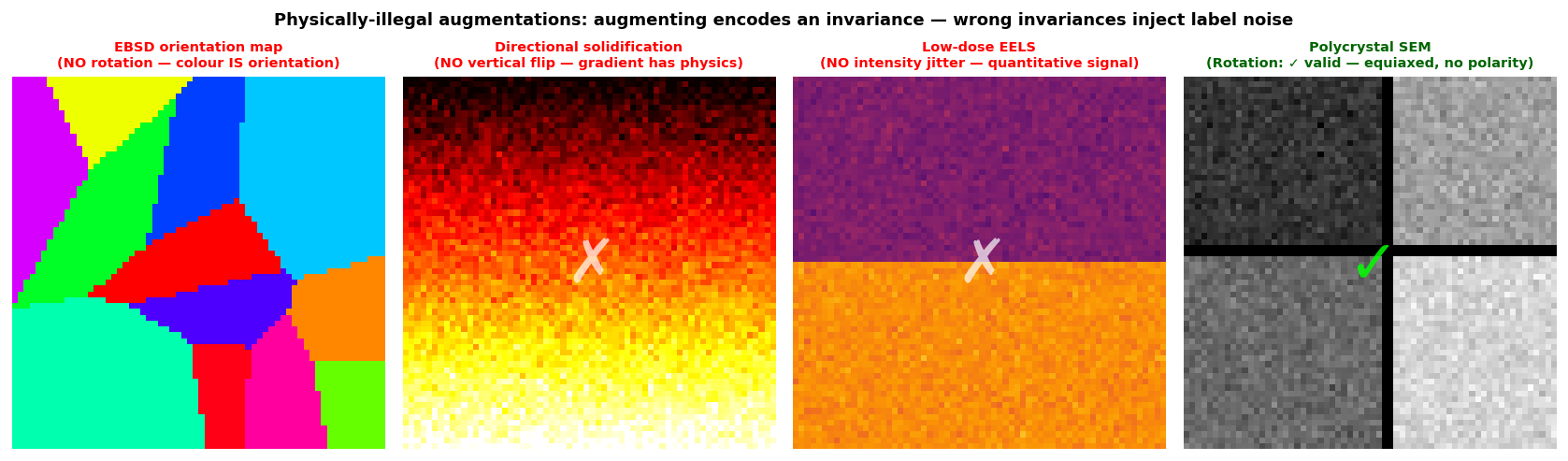
Four panels illustrating when augmentations are illegal. Panel 1 (EBSD map): rotation is illegal — the colour encodes crystallographic orientation; rotating the image without rotating the IPF colour key produces a physically impossible map. Panel 2 (directional solidification): vertical flip is illegal — the thermal gradient is physically real. Panel 3 (EELS map): intensity jitter is illegal — calibrated intensity encodes composition. Panel 4 (equiaxed polycrystal): all augmentations checked here are valid.
On-the-fly augmentation and label consistency

Label consistency: when a grain-boundary image is rotated 45°, the segmentation mask must be rotated by exactly the same 45°. Top row (left to right): original image, original mask, rotated image (45°). Bottom row: correct — rotated mask (same 45°, joint transform); wrong — un-rotated mask paired with the rotated image, producing misaligned ground truth.
- On-the-fly (preferred): sample a new random transform per batch — the network never sees exactly the same pixels twice. Near-infinite effective dataset from 50 images.
- Offline augmentation: pre-generate augmented images on disk. Faster per epoch but with a fixed set that the network will eventually memorise over many epochs. Use only when augmentation is computationally expensive (e.g. physics rendering).
- The rule: augment AFTER splitting by specimen. Augment only the training set. Never augment before the train/test split — an image and its rotation must not land on both sides of the split.
Why ImageNet features transfer to EM images
Transferability as a function of CNN depth Yosinski, Jason et al., (2014). Layer 1 (edges, gradients): ~95% transferable — universal low-level image features. Layer 2 (textures, corners): ~80% — mostly domain-general. Layer 3 (object parts): ~45% — becoming domain-specific. Layer 4+ (full objects / task-specific): ~10% — ImageNet-dog features are not EM features.
The transfer learning recipe: freeze → head → fine-tune
Three-stage transfer learning recipe. Stage 1: all backbone blocks frozen (grey); only the head (red) is trained at lr=1e-3. Stage 2: last backbone block unfrozen (orange) with low lr=1e-5; head continues at 1e-3. Stage 3: gradual unfreezing, depth-graded learning rates — early layers receive the smallest lr, late layers more, head the most.
Catastrophic forgetting and differential learning rates
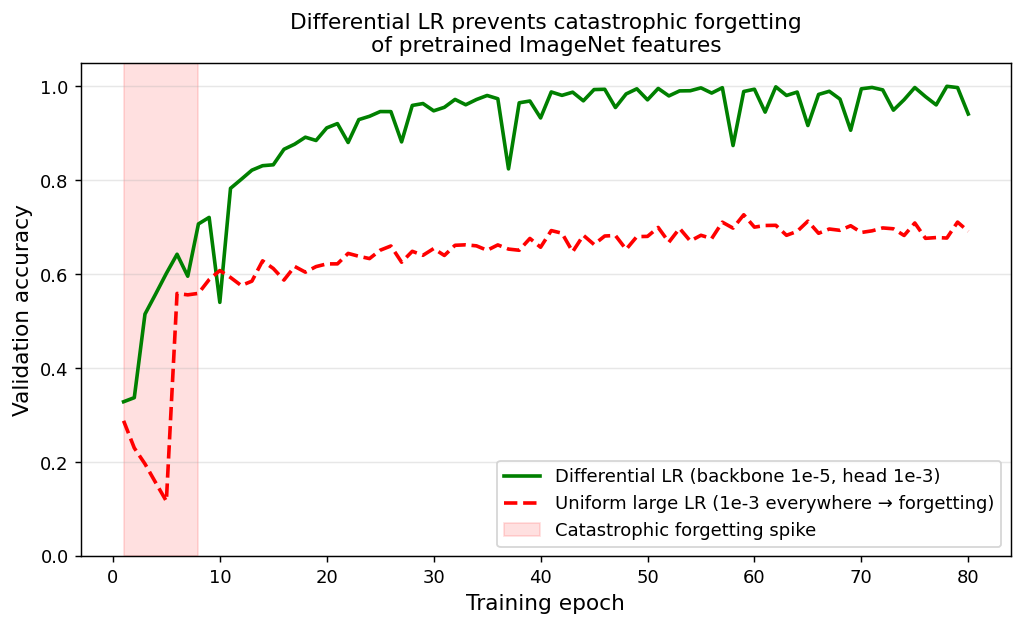
Validation accuracy during fine-tuning. Green (correct): differential LRs — backbone gets lr=1e-5, head gets lr=1e-3; accuracy climbs steadily. Red dashed (wrong): uniform large lr=1e-3 for the whole network — the first few epochs destroy pretrained ImageNet features (catastrophic forgetting spike); recovery is partial and slow.
- Catastrophic forgetting mechanism: the randomly-initialised head produces large, near-random gradients in epoch 1. Backpropagated at the normal (large) lr through the pretrained backbone, these random gradients overwrite the carefully learned ImageNet features before the head has stabilised.
- Differential learning rates: backbone lr ≈ \(10^{-5}\); head lr ≈ \(10^{-3}\) — a ratio of 100×.
- The ratio reflects the distance to the minimum: the backbone is already at a good minimum (small steps needed); the head is randomly initialised far from any minimum (large steps needed).
Voronoi synthetic microstructure pipeline
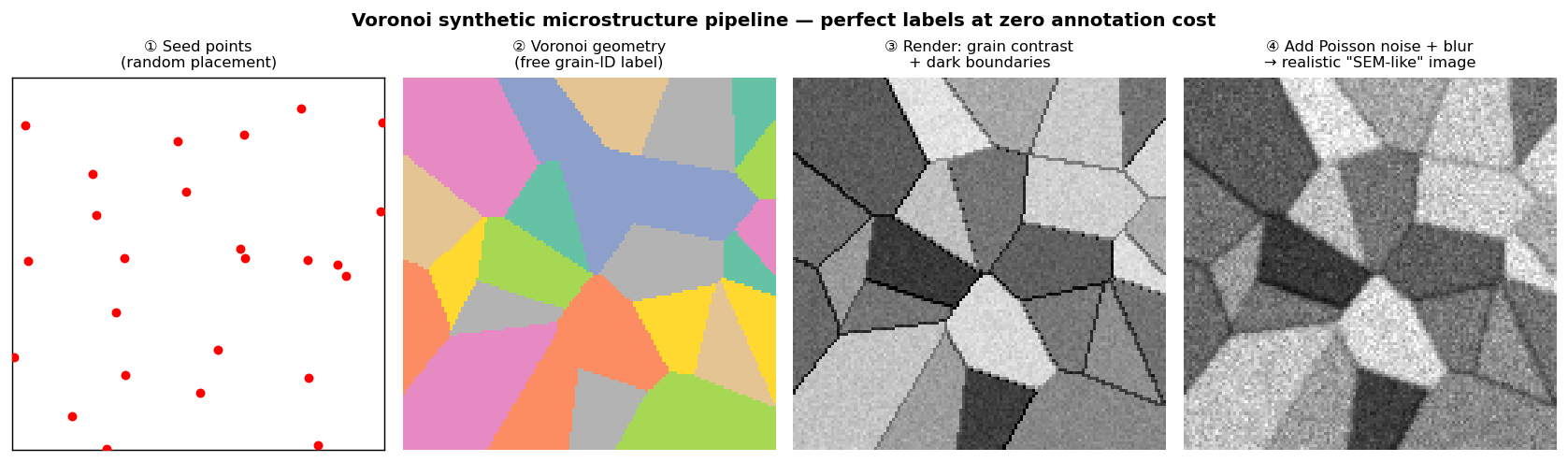
Voronoi synthetic microstructure pipeline for grain segmentation. From left: (1) random seed points placed in 2D; (2) each pixel assigned to its nearest seed — the Voronoi geometry gives perfect free grain-ID labels; (3) random intensity per grain + dark boundary strip renders a simple grain image; (4) Poisson noise + Gaussian blur makes it look like a low-magnification SEM acquisition.
The sim-to-real gap

Three panels showing the sim-to-real challenge. Left: synthetic training image (clean, regular grains, no scan artefacts). Centre: real SEM image with scan distortion, vignette, and contrast drift relative to the synthetic distribution. Right: U-Net prediction — grain topology is correctly identified despite the gap, because topology is the task-relevant invariant.
Active learning: label the most informative samples
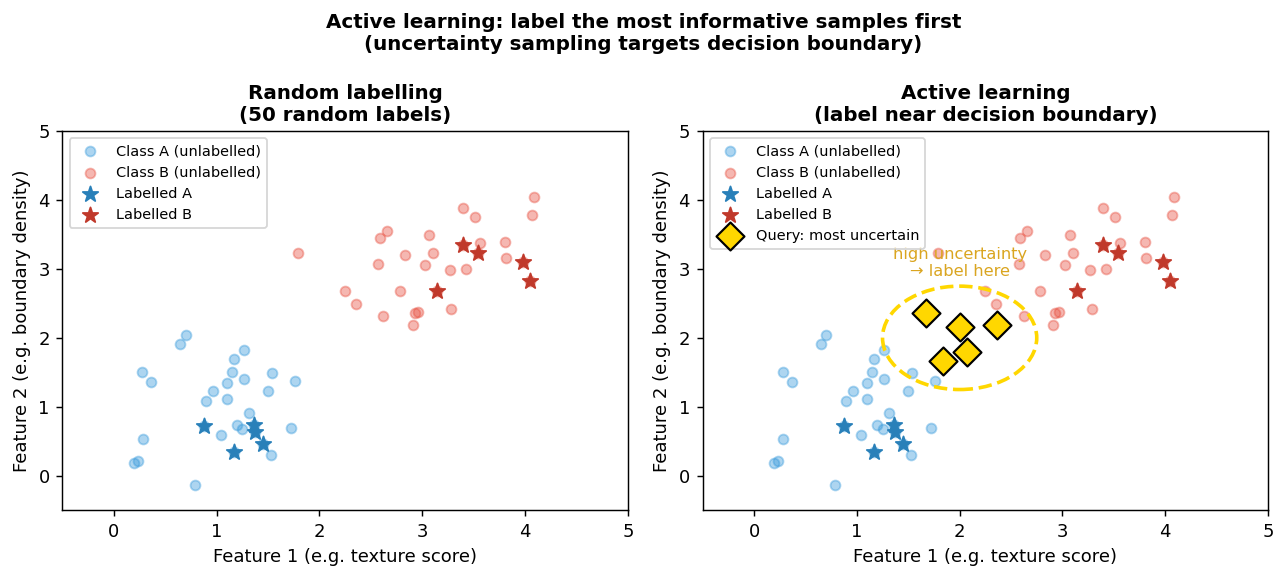
Left: random labelling strategy — 50 labels scattered uniformly across feature space. Right: active learning — labels concentrated near the decision boundary, where uncertainty is highest. With the same 50 labels, the active strategy correctly identifies the decision boundary; random labelling leaves a large uncertain region.
The complete small-data EM workflow
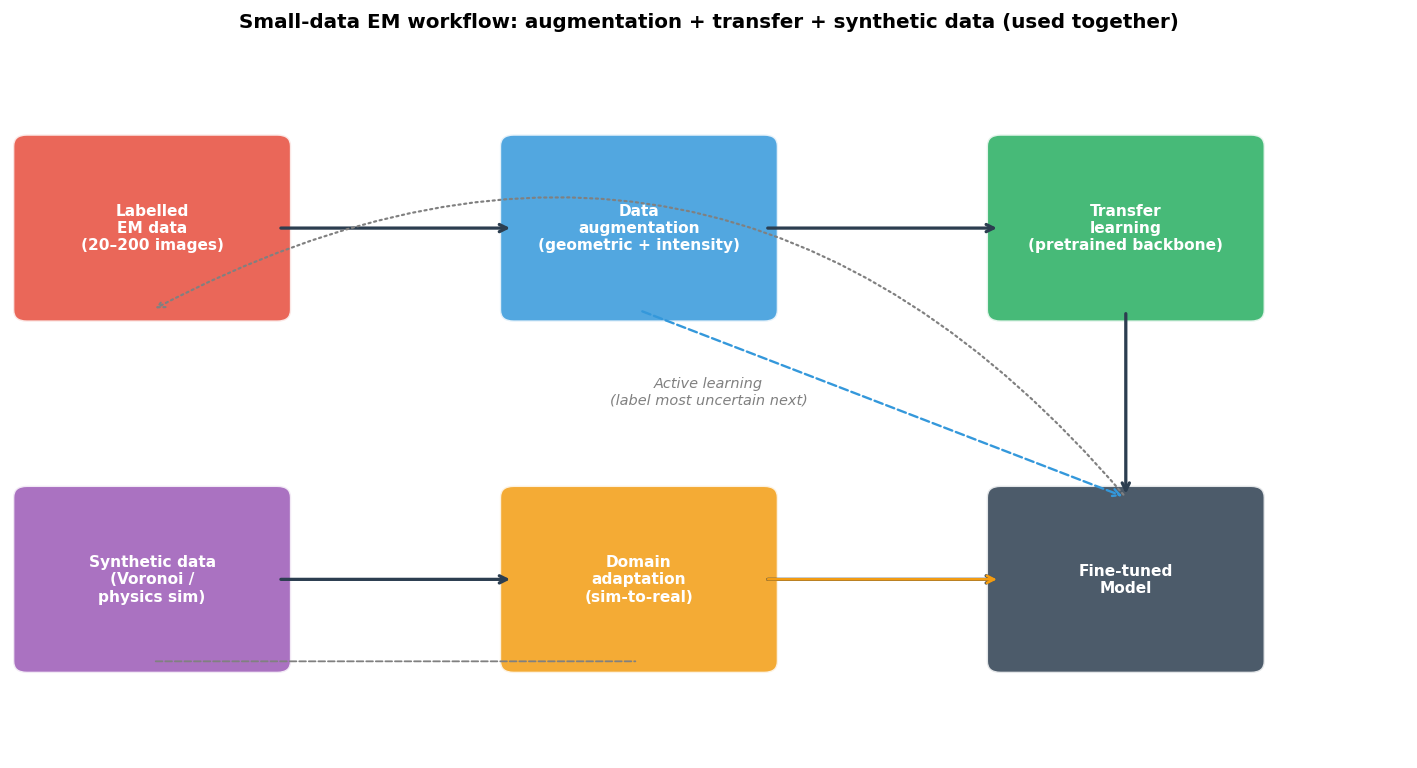
Complete small-data EM workflow diagram. The labelled EM data (20–200 images) feeds augmentation and transfer learning in parallel; synthetic data feeds domain adaptation; all three converge on a fine-tuned model. The active learning loop (dotted arrow, bottom) queries the fine-tuned model for the most uncertain unlabelled images, sends them to expert annotation, and grows the labelled pool.