graph LR
Model[Model Type] --> WB[White-box]
Model --> GB[Grey-box]
Model --> BB[Black-box]
WB --- WBdesc[Physics-based]
GB --- GBdesc[Hybrid]
BB --- BBdesc[Data-driven]
Mathematical Foundations of AI & ML
Unit 1: What Learning Means in Engineering and Materials




Books for the lecture triad



Advanced Materials Development
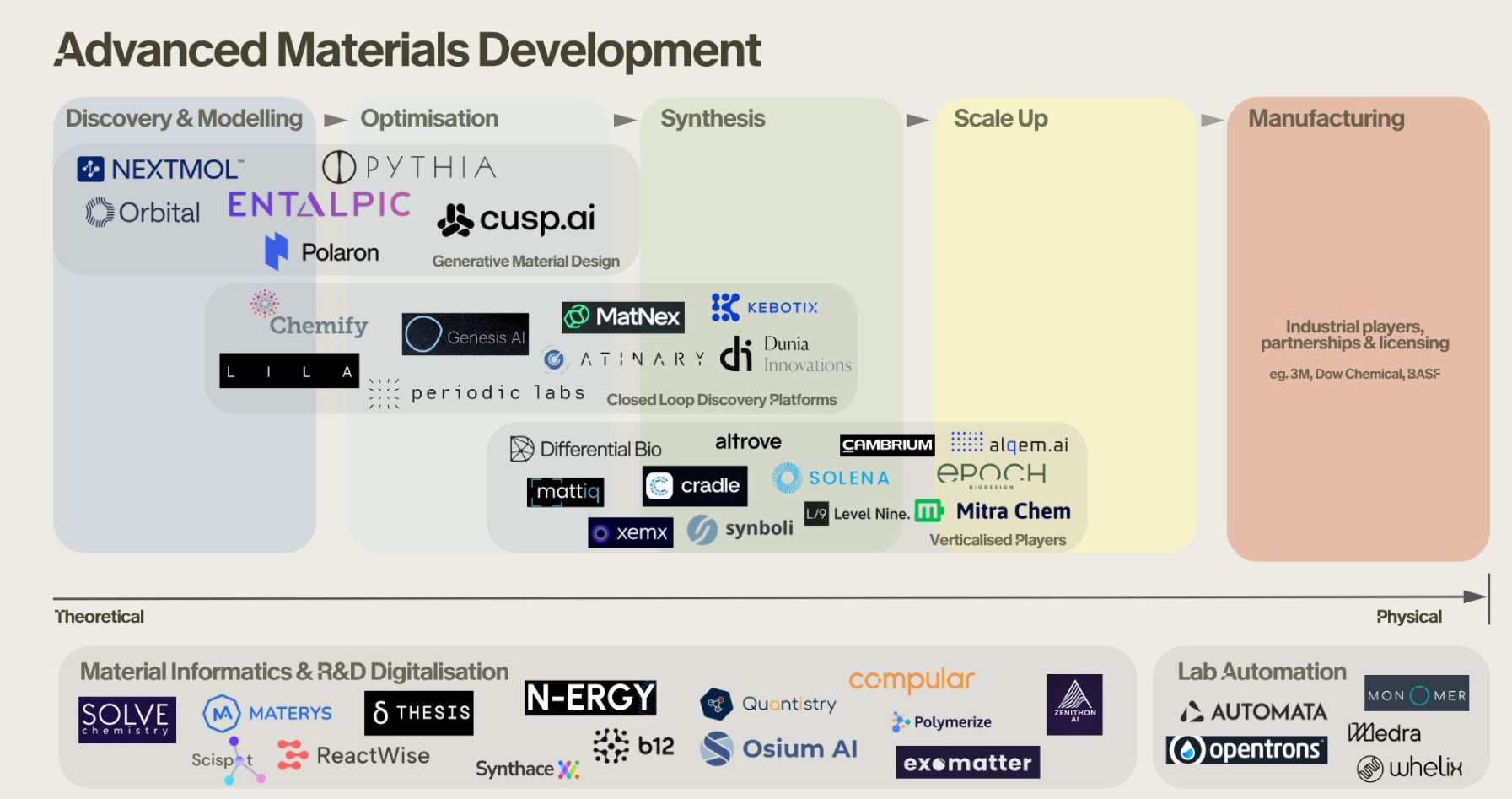
Landscape of advanced materials development companies & Startups
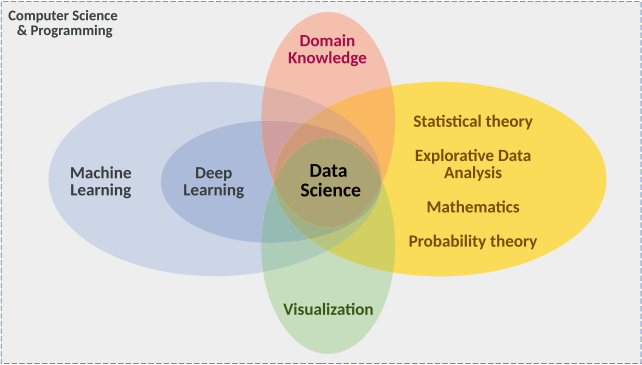
Quick map: AI vs ML vs DL vs Data Science
- AI: broad umbrella for intelligent systems.
- ML: data-driven function estimation inside AI.
- DL: model family inside ML.
- Data science: includes data engineering, diagnostics, domain interpretation, and deployment context (Sandfeld et al. 2024).
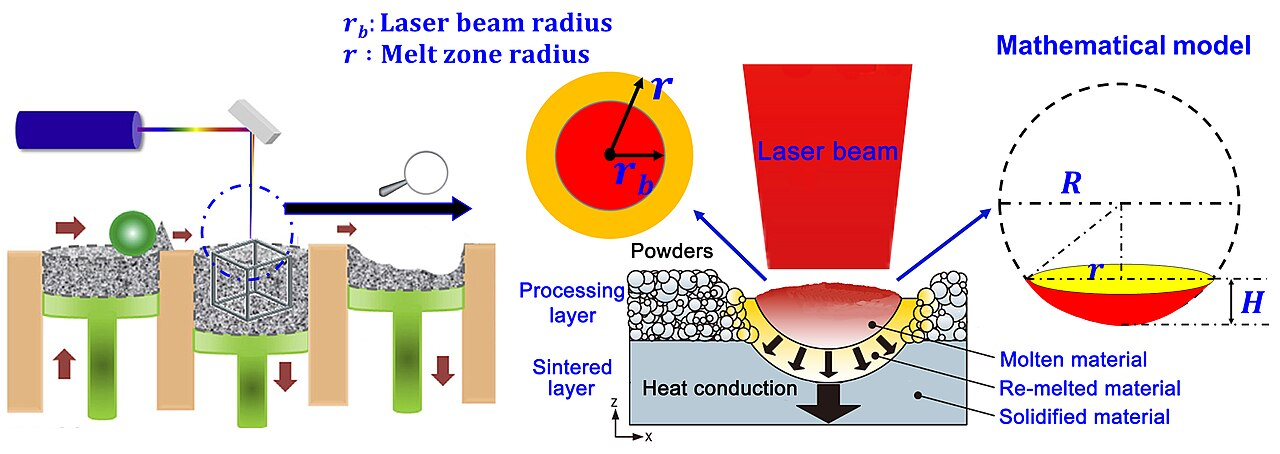
When first-principles is insufficient
- Complex process chains can be nonlinear, high-dimensional, and partially observed.
- Closed-form mechanistic models can be unavailable or too expensive.
- Hybrid strategies (physics + data) are often the engineering sweet spot.
Example — Melt-pool dynamics in additive manufacturing: We can formulate the partial differential equations (PDEs) for laser-melting metal powder, but simulating them for a whole part is computationally too expensive for real-time control. Internal defects are also physically “partially observed.” A hybrid strategy trains an ML model on high-fidelity simulations and sensor data to predict defects in real-time, bypassing the computational bottleneck of pure physics while retaining physical validity (Meng et al. 2020).
Why black-box criticism appears
- Safety, traceability, and auditability requirements in engineering settings.
- Difficulty diagnosing failure causes without behavioral probes.
- High-stakes contexts demand calibrated confidence and explainability.
Example — Automated weld inspection: A deep CNN classifies radiographic weld images as accept / reject with 97 % accuracy. When a batch of welds is rejected, the production engineer asks: “Is the defect porosity, lack of fusion, or a crack?” The model cannot answer — it was trained end-to-end on a binary label. Without an interpretable intermediate representation, the team must repeat expensive manual inspection to identify the root cause, negating the deployment benefit.

Types of learning
Supervised Learning
Learning with labeled data. Includes regression (continuous targets) and classification (discrete categories).
Example: Predicting alloy yield strength from chemical composition [Bhandari et al., 2020]. 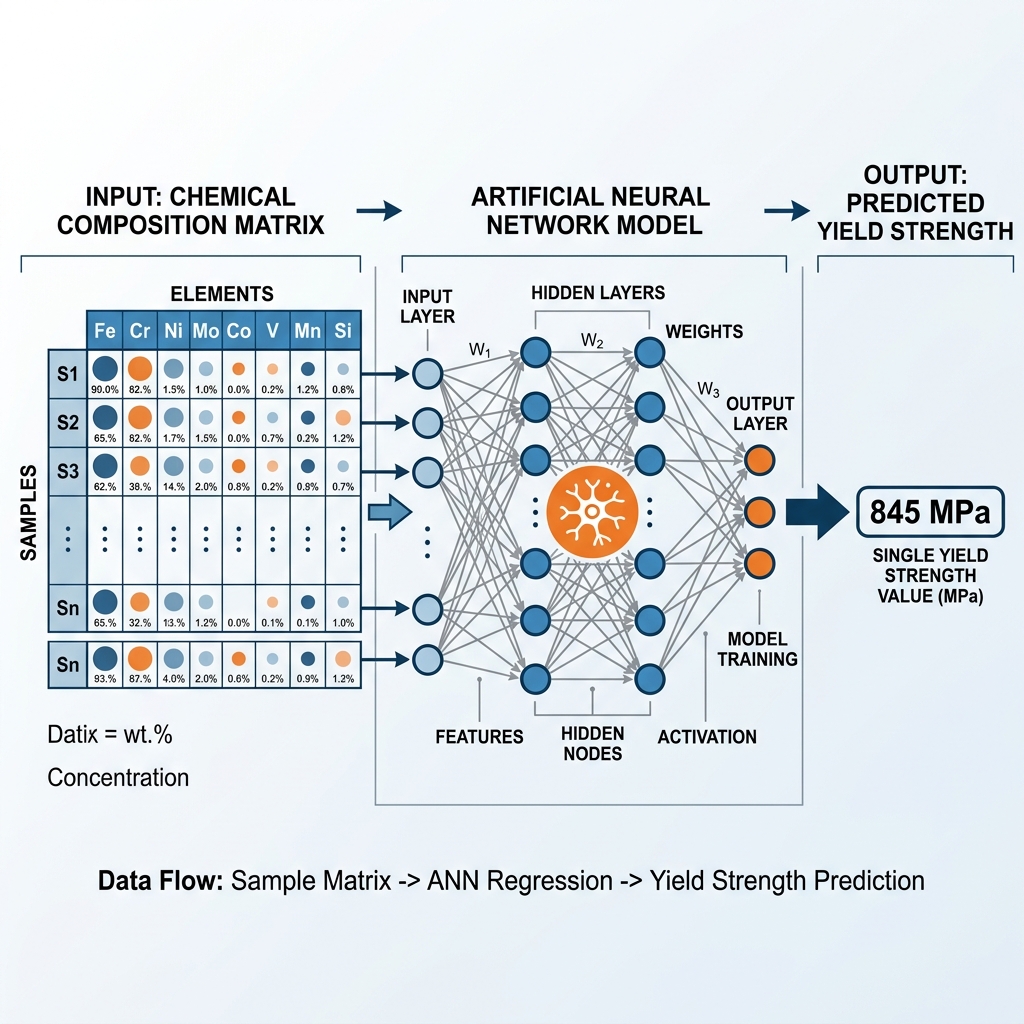
Unsupervised Learning
Finding hidden structure in unlabeled data (clustering, dimensionality reduction, embeddings).
Example: Clustering unlabelled microscopy images to discover distinct phases [Stender et al., 4D-STEM phase mapping]. 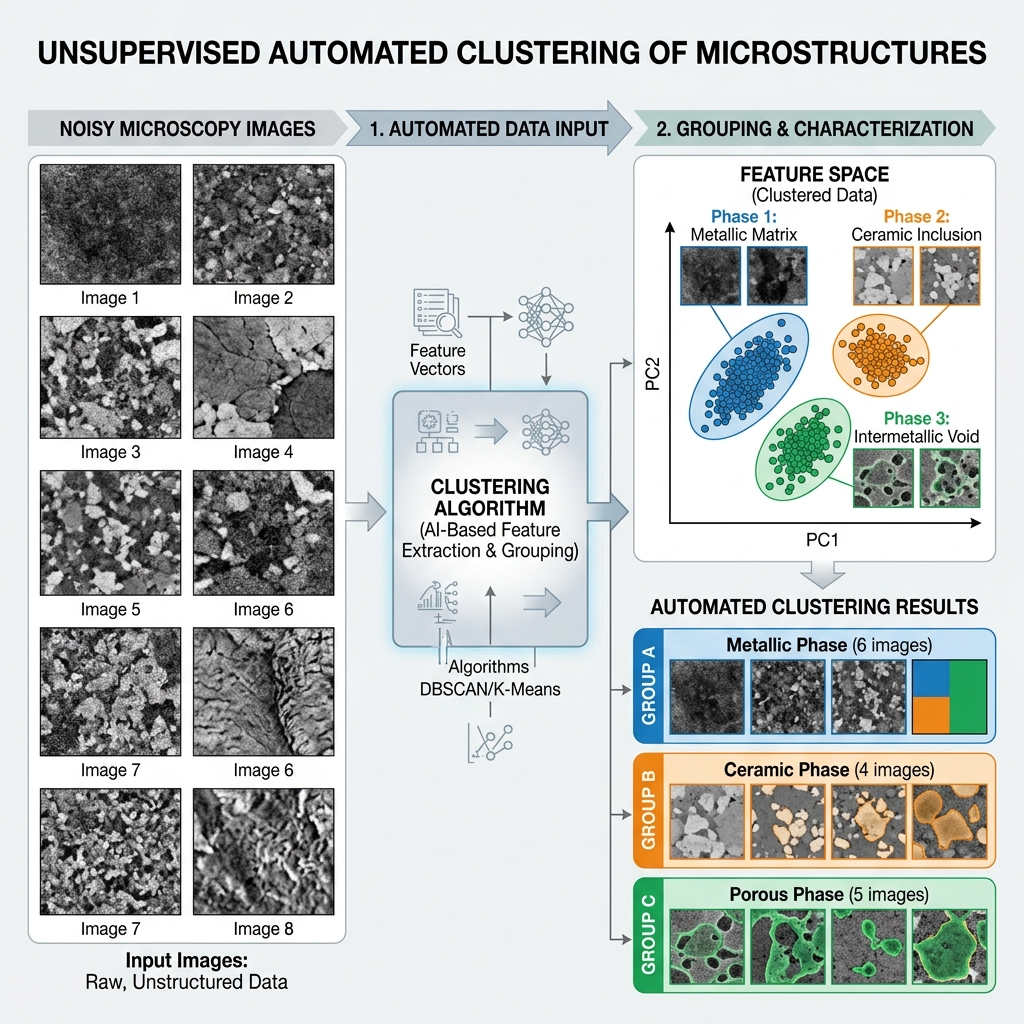
Reinforcement Learning
Learning optimal actions through trial and error to maximize a reward signal.
Example: An autonomous agent controlling a laser-melting process to minimize defects [Wang et al., 2021]. 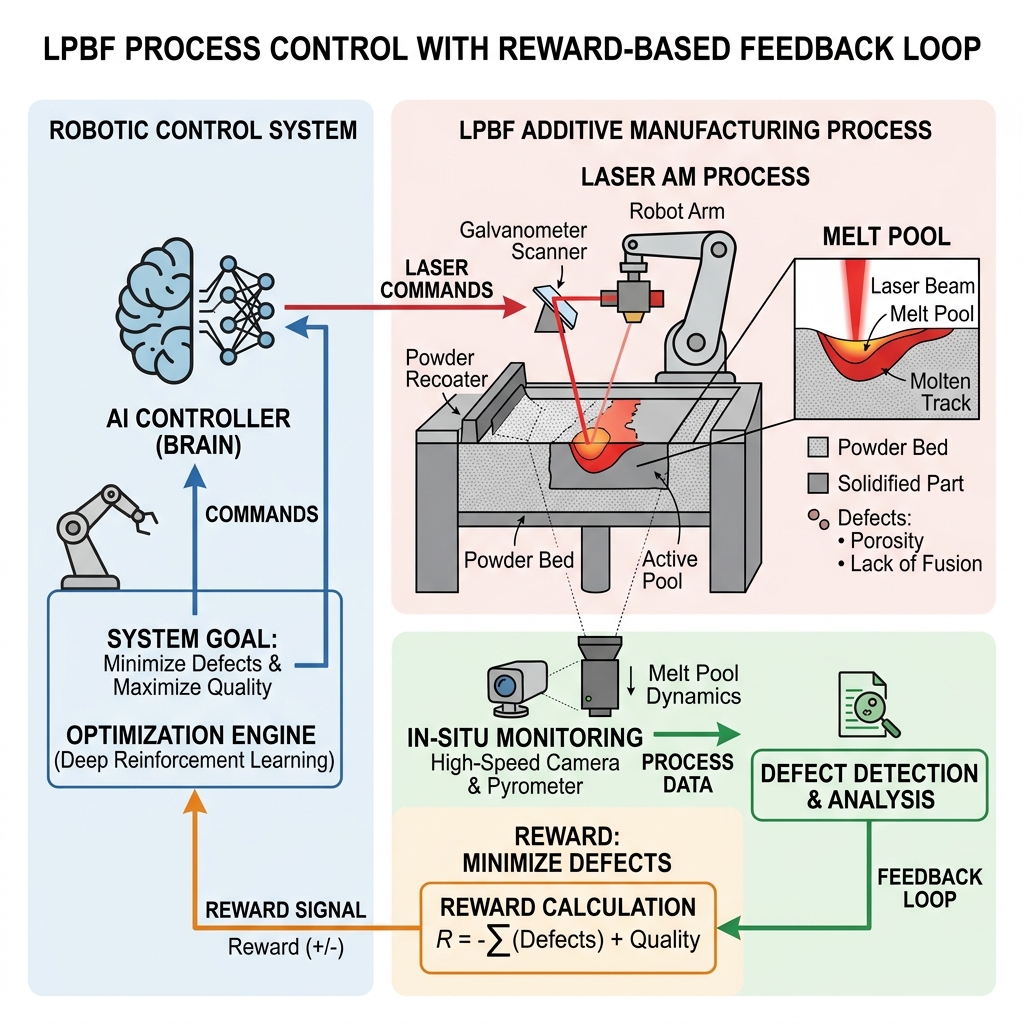
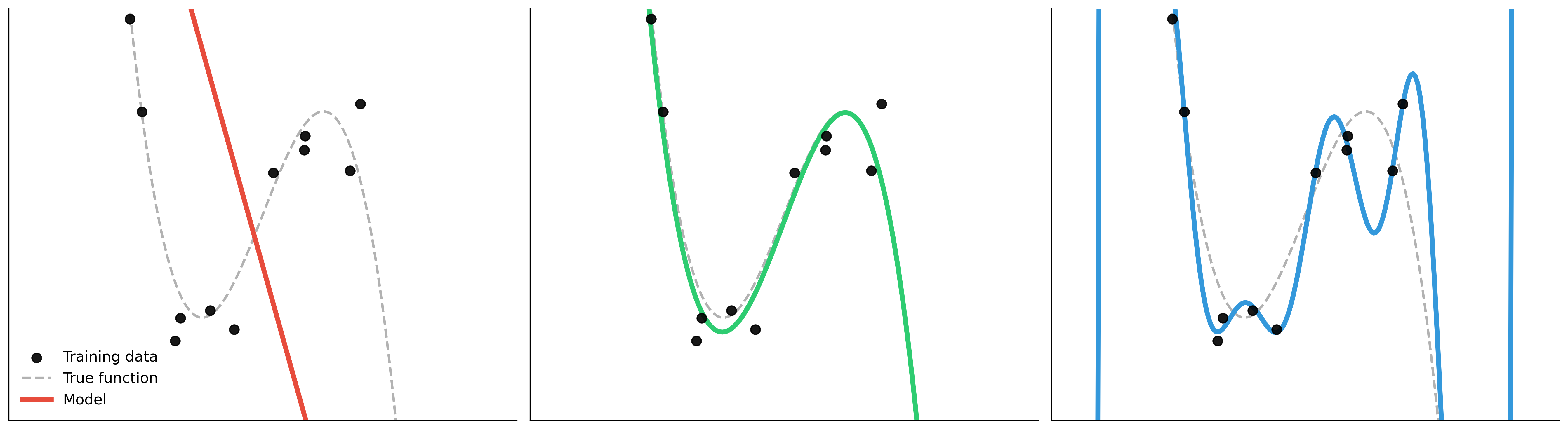
Overfitting explained visually
Underfit
- High bias
- Misses structure
Well-fit
- Captures stable signal
- Controlled complexity
Overfit
- Memorizes quirks/noise
- Weak transfer
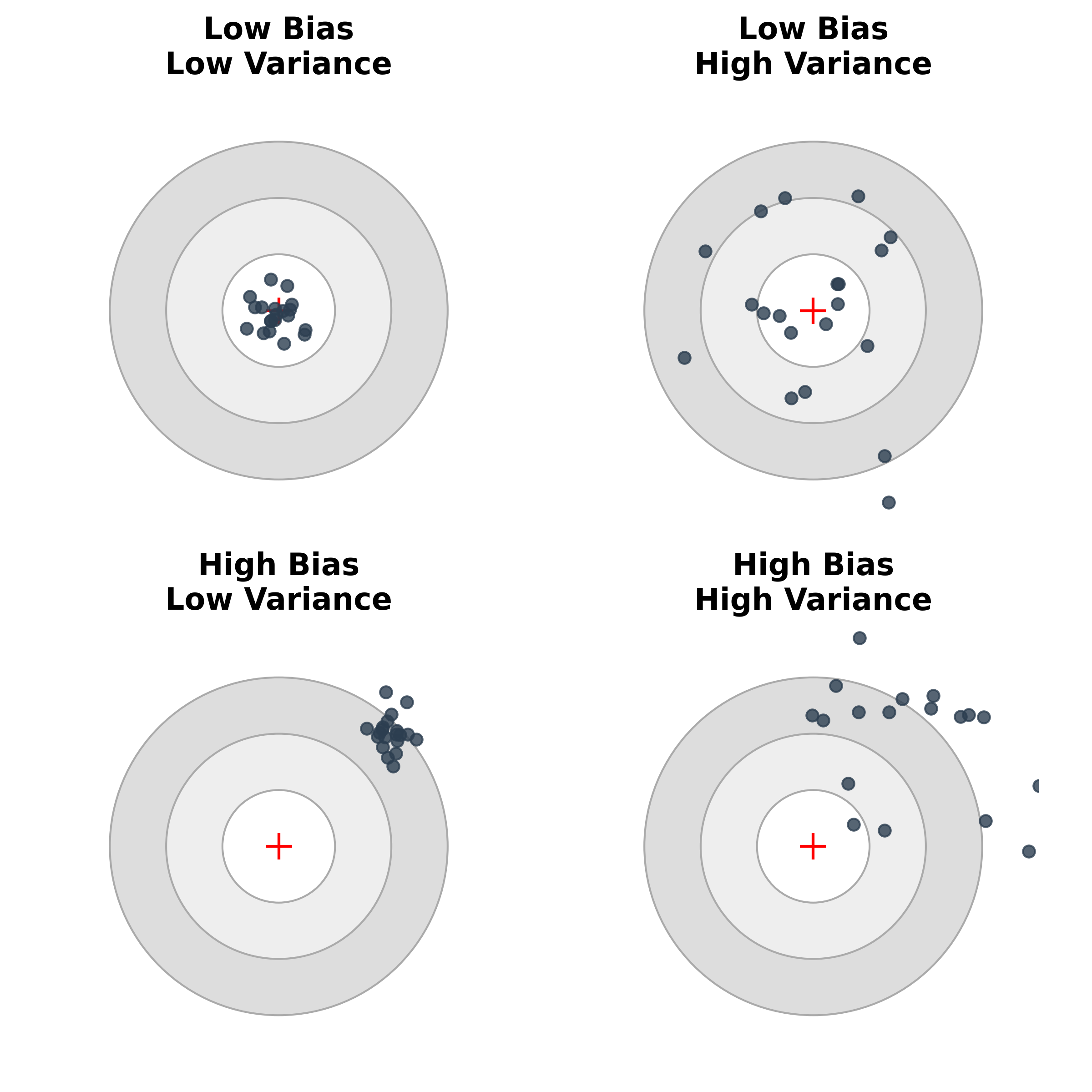
Bias–variance decomposition (Intuition)
- Truth (Bullseye): The true underlying physical mechanism.
- Darts (Predictions): Where our model lands when trained on slightly different batches of data.
- Bias: The systematic offset from the truth. (Model is fundamentally too structurally simple or constrained).
- Variance: The scatter of the darts. (Model is hypersensitive to the exact noise in the training set).
The Bias-Variance Tradeoff Curve
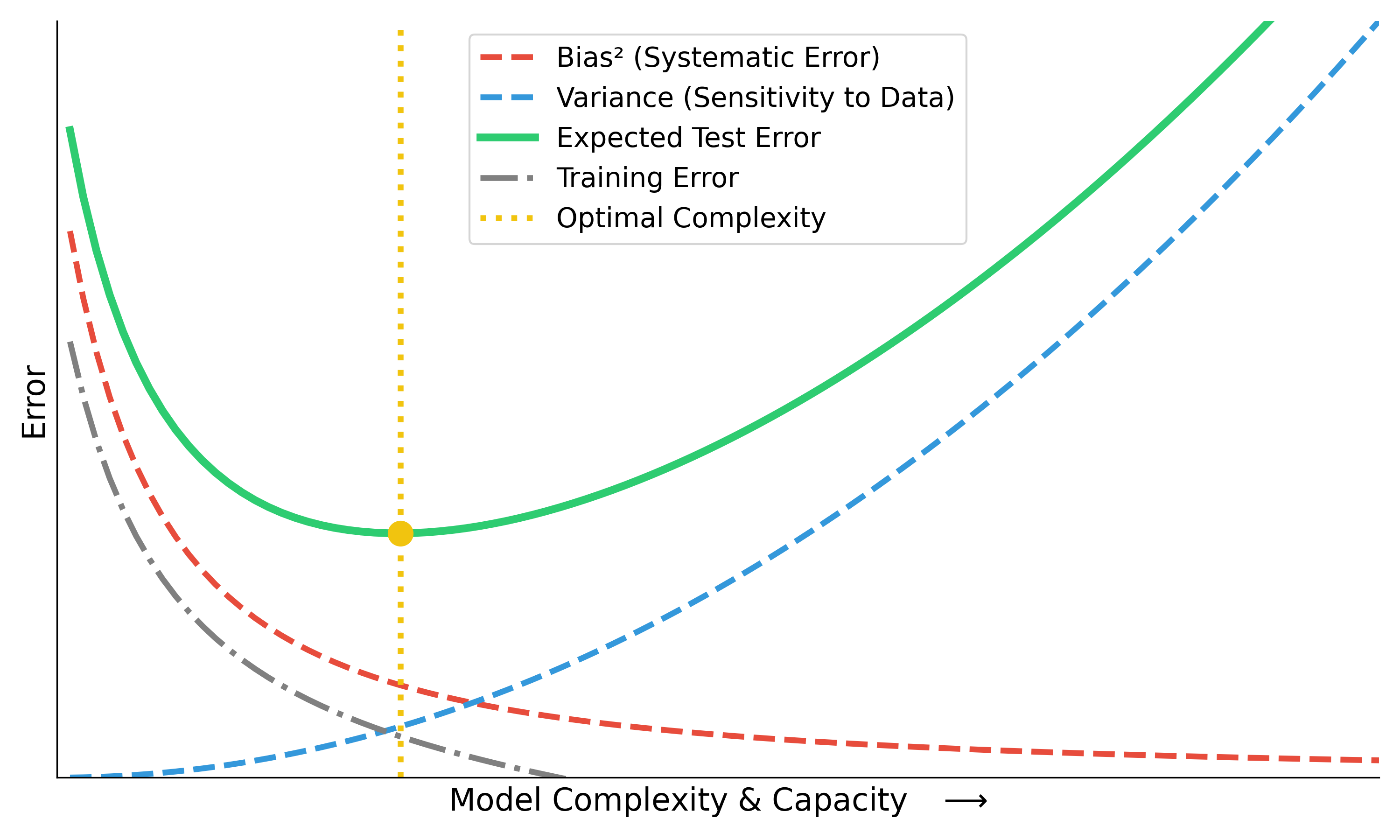
Total Expected Error = \(\text{Bias}^2\) + \(\text{Variance}\) + \(\text{Noise}\)
- Increasing model capacity drives down training error continuously.
- But expected deployment error forms a U-shape.
- Finding the sweet spot (yellow line) is the central pursuit of ML.
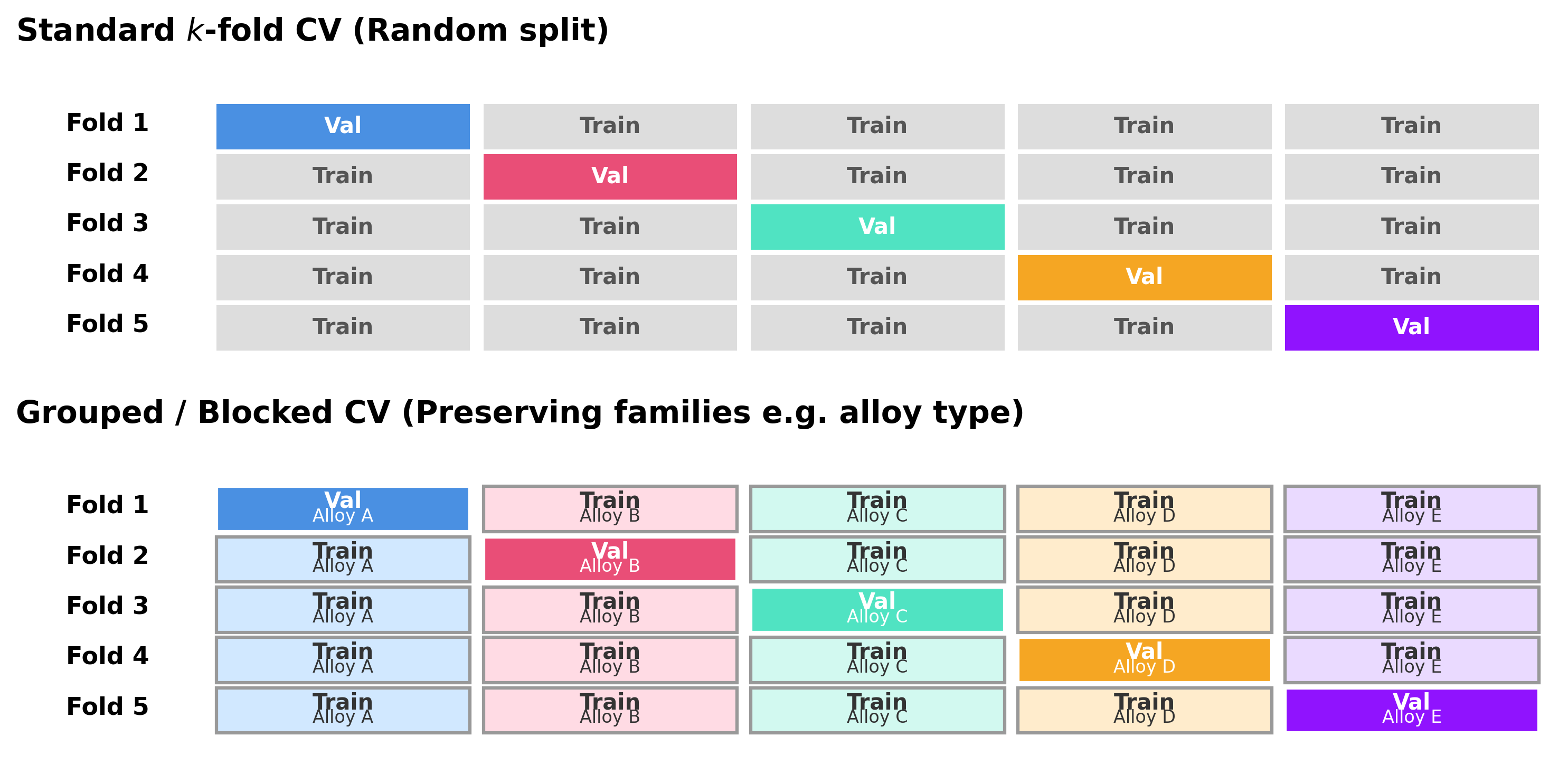
Cross-validation
- k-fold CV improves stability under limited data.
- Use grouped/blocked CV when IID assumptions break.
- Random CV can be misleading for correlated materials families (McClarren 2021).