Replace fixed features with learned representations.
Understand why dense MLPs struggle with images.
Derive convolution from locality and translation equivariance.
Build the vocabulary for modern CNN architectures.
The big leap
Unit 3 used \(f_{\mathbf{w}}(\mathbf{x}) = \mathbf{w}^T\boldsymbol\phi(\mathbf{x})\): a linear model on fixed features.
Neural networks make \(\boldsymbol\phi\)learnable by composing layers.
For tabular data, dense layers are often a reasonable first architecture.
For images, spectra, and spatial fields, dense layers ignore what we already know: nearby pixels matter, patterns can move, and features are hierarchical.
CNNs build those assumptions into the architecture.
Fixed bases we already know
Before learning features, we often choose a basis by hand:
GLM / polynomial bases: engineered non-linear coordinates for a linear model.
The limitation is not linearity alone; it is that \(\phi_j\) is fixed before seeing the task.
Example: Fourier basis on a \(16\times16\) image
Real Fourier atoms on a 16 by 16 grid
Fourier features are excellent when the signal is naturally decomposed into global frequencies. They are less natural for localized edges, defects, and spatial motifs.
Example: DWT / Haar wavelet basis
Haar wavelet atoms on a 16 by 16 grid
Wavelets add locality and scale. This is already closer to images: a feature can live in one region and at one resolution.
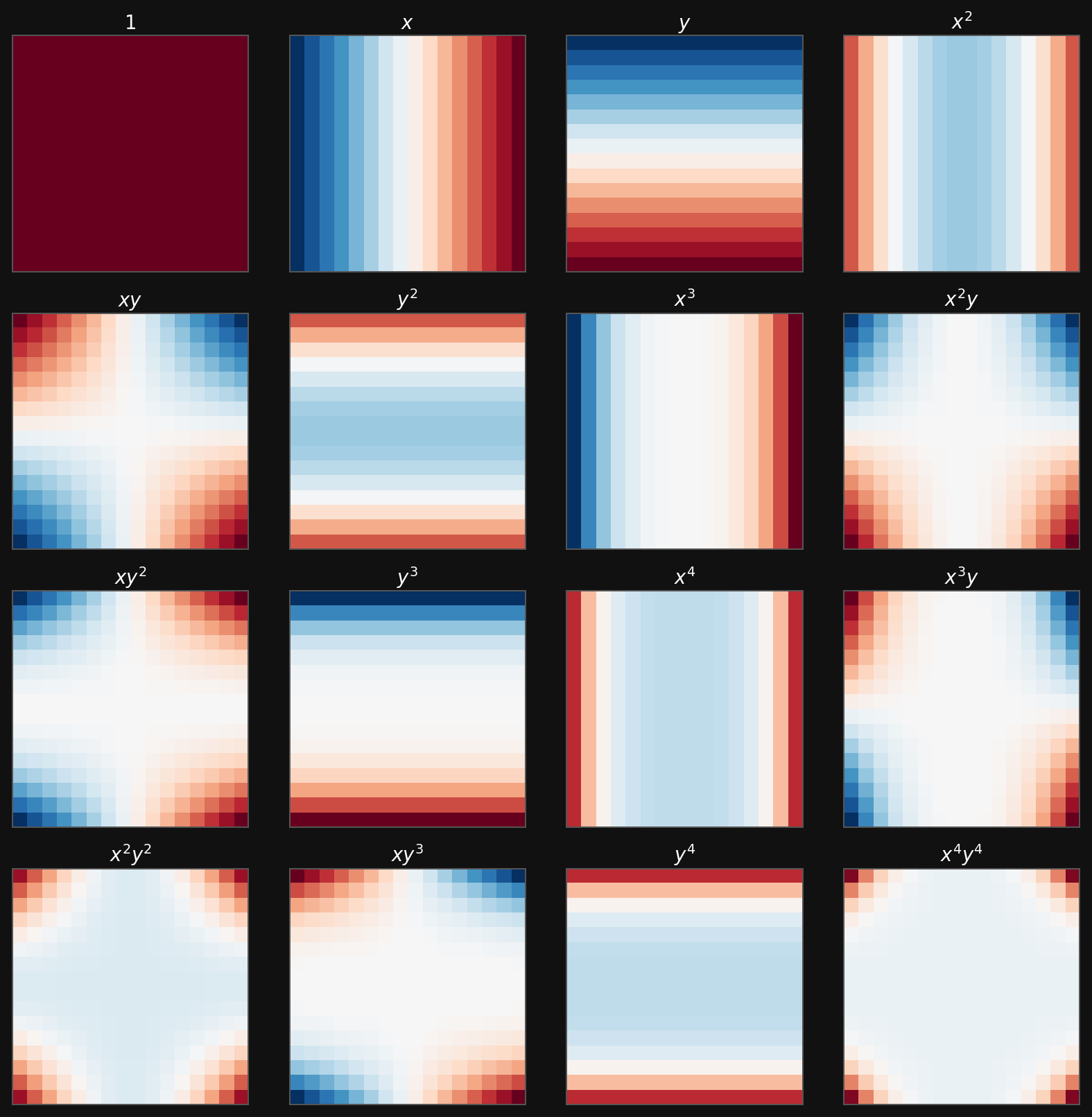
Example: polynomial basis for a GLM
Polynomial basis functions on a 16 by 16 grid
Polynomial features make a linear model non-linear in the original coordinates, but the feature map is still chosen by the engineer.
Every output location \((i,j)\) can use every input location \((k,l)\).
Parameter count scales like output pixels \(\times\) input pixels.
To impose locality, allow \(H_{i,j}\) to use only pixels near \((i,j)\): \[
H_{i,j} = U_{i,j} + \sum_a\sum_b V_{i,j,a,b}X_{i+a,j+b}.
\]
Weight sharing gives convolution
Now impose that the same local detector is used at every location:
\[
U_{i,j} = u,
\qquad
V_{i,j,a,b}=V_{a,b}.
\]
Then
\[
\boxed{
H_{i,j} = u + \sum_a\sum_b V_{a,b}X_{i+a,j+b}
}
\]
This is the convolutional layer idea: local receptive fields plus shared weights.
Parameter economy
For a single output channel from a single input channel:
Layer type
Parameters
Dense image-to-image map
\(h_{out}w_{out}h_{in}w_{in}\)
Local but unshared map
\(h_{out}w_{out}k_hk_w\)
Convolutional map
\(k_hk_w + 1\)
A \(5\times5\) convolution uses 25 weights plus one bias per output channel. The same detector is evaluated across the image.
Convolutional design principles
Locality
Early layers inspect small neighborhoods.
Larger context emerges through depth.
Weight sharing
One kernel detects the same pattern everywhere.
Reduces parameters and improves data efficiency.
Channel mixing
Many kernels run in parallel.
Each output channel is a learned feature map.
Hierarchy
Later layers compose earlier features.
Cross-correlation: the operation used in CNNs
In strict mathematics, convolution flips the kernel:
\[
(f*g)(i,j)=\sum_a\sum_b f(a,b)g(i-a,j-b).
\]
CNN libraries usually implement cross-correlation:
\[
H_{i,j}=\sum_a\sum_b K_{a,b}X_{i+a,j+b}.
\]
Because \(K\) is learned, the distinction rarely matters in neural networks. We still call the layer a convolutional layer.
Sliding-window view
Two-dimensional cross-correlation operation
A small kernel slides across the input.
At each location: multiply overlapping entries and sum.
The output is a spatial map of detector responses.
Add a bias and apply a non-linearity to get a convolutional activation map.
A hand-computable filter
A horizontal difference kernel
\[
K = \begin{bmatrix}1 & -1\end{bmatrix}
\]
responds strongly where neighboring pixels change.
If a row is constant:
\[
[1,1,1,1] \star [1,-1] = [0,0,0].
\]
If a row has an edge:
\[
[1,1,0,0] \star [1,-1] = [0,1,0].
\]
Learned CNN filters generalize this idea: they discover useful local detectors instead of receiving them by hand.
Feature maps
A kernel is a learned local detector.
A feature map is the detector response at all spatial positions.
Multiple kernels produce multiple feature maps.
Stacking feature maps gives a tensor representation with shape \[
C_{out}\times H_{out}\times W_{out}.
\]
In microscopy, feature maps may respond to edges, atomic columns, defects, texture, or phase boundaries.
Receptive fields
The receptive field of an output activation is the input region that can influence it.
One \(3\times3\) convolution: local \(3\times3\) view.
Two stacked \(3\times3\) convolutions: effective \(5\times5\) view.
Three stacked \(3\times3\) convolutions: effective \(7\times7\) view.
Why this matters:
Deep CNNs grow context gradually.
Small kernels keep parameters low.
Non-linearities between kernels make the result richer than one large linear filter.
Hierarchy of learned features
Layer 1: simple contrasts, edges, gradients, local textures.
Layer 2: motifs such as corners, grains, pores, peaks, local lattice distortions.
Layer 3+: object parts or material structures such as defects, precipitates, cracks, phase clusters.
This is why CNNs match spatial scientific data: the architecture mirrors the structure of the signal (McClarren 2021).
Multiple channels
Real image-like inputs are not just matrices:
\[
X \in \mathbb{R}^{C_{in}\times H\times W}.
\]
A convolutional layer with \(C_{out}\) output channels uses kernels
\[
K \in \mathbb{R}^{C_{out}\times C_{in}\times k_h\times k_w}.
\]
The output is
\[
H \in \mathbb{R}^{C_{out}\times H_{out}\times W_{out}}.
\]
For electron microscopy or spectroscopy, channels might be RGB-like channels, detector channels, energy windows, tilt slices, or learned feature channels.
Similar motifs appear at different spatial locations.
Multi-channel measurements are common: energy channels, detector geometry, polarization, tilt, time, or simulated fields.
The relevant features are often hierarchical: local contrast -> motif -> structure -> property.
CNNs encode this hierarchy more naturally than dense MLPs.
TODO example images here
Example architecture choices
Micrograph classification
Input: SEM or TEM image.
Use: convolutional encoder.
Head: global pooling + class logits.
Goal: one label per image.
Defect segmentation
Input: image or spectral image.
Use: U-Net-like encoder-decoder.
Head: per-pixel logits.
Goal: mask or defect probability map.
Spectral-spatial regression
Input: channels over space.
Use: CNN backbone plus regression head.
Head: linear or physically constrained output.
Goal: local property or global scalar.
What CNNs do not solve by themselves
They do not remove the need for good training data.
They do not decide the correct loss function.
They do not guarantee optimization will succeed.
They do not automatically generalize across microscopes, domains, or sample preparation protocols.
They do not replace physical reasoning; they encode useful priors into a learnable model.
CNN design checklist
Summary: the architectural decisions of a CNN
Decision
Driver
Consequence
Kernel size
local pattern scale
parameters and receptive field
Channel count
feature diversity
capacity and compute
Padding
boundary assumptions
output size and border behavior
Stride/pooling
downsampling rate
resolution vs context
Depth
hierarchy level
abstraction and trainability
Skip connections
information flow
easier deep optimization
Head type
task structure
classification, regression, segmentation
Forward links
Self-study supplement (this folder, 02_backprop_self_study.qmd): backpropagation and gradient flow through the layers defined today.
Unit 5: clustering and autoencoders — the first unsupervised representation-learning unit.
Unit 6: optimization for deep nets, including momentum, Adam, normalization, and learning-rate schedules.
Unit 8: generalization, regularization, and why parameter count alone does not predict test error.
Later ML-PC / applied units: CNNs in materials characterization, attention, Transformers, and domain-specific architectures.
End-of-unit quiz
Why does a dense layer become parameter-inefficient for a megapixel image?
Derive the convolution formula from locality and shared weights.
What is the difference between translation equivariance and translation invariance?
For input shape \(3\times64\times64\), kernel shape \(16\times3\times5\times5\), padding \(2\), and stride \(1\), what is the output shape and parameter count?
Why do two stacked \(3\times3\) convolutions differ from one \(5\times5\) convolution?
Which architecture head would you choose for image classification vs defect segmentation, and why?
This companion remains useful for the minimal MLP foundation: it builds a two-layer network from affine maps and activations. The lecture has shifted toward CNN architecture foundations; CNN training details follow in later applied units.
Backpropagation is a self-study supplement this term. See 02_backprop_self_study.qmd in this unit folder, plus Sandfeld ch. 18.3-18.4 and the two example notebooks (18.3_Backpropagation..., 18.5_Python_Implementation...). A short chain-rule warm-up is included on the next exercise sheet so the self-study has teeth. Use loss.backward() in PyTorch in the meantime — autograd handles it.
Reading for next time.Unit 5 turns from supervised to unsupervised learning: K-means and Gaussian mixtures for clustering, then autoencoders as the neural-network counterpart. Skim Neuer Ch. 5 and McClarren Ch. 4 + Ch. 8 before lecture.
Learning outcomes
By the end of this unit, students can:
Write the forward pass of a dense layer and explain why non-linear activations are required.
Estimate why fully connected layers become impractical for image-like data.
Derive a convolutional layer as a dense layer constrained by locality and shared weights.
Track tensor shapes through kernels, channels, padding, stride, and pooling.
Explain feature maps, receptive fields, and hierarchical feature learning.
Recognize common CNN design motifs: blocks, \(1\times1\) convolutions, skip/feature-reuse connections, and encoder-decoders.
Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. 2016. Deep Learning. MIT Press.
McClarren, Ryan G. 2021. Machine Learning for Engineers: Using Data to Solve Problems for Physical Systems. Springer.