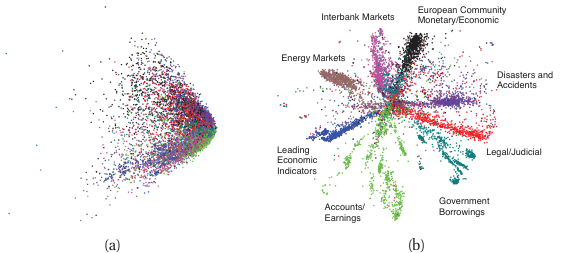
pts = [
{id: 1, x: 1, y: 1}, {id: 2, x: 1, y: 2}, {id: 3, x: 2, y: 1},
{id: 4, x: 8, y: 8}, {id: 5, x: 9, y: 8}, {id: 6, x: 8, y: 9}
];
// Precompute the steps
cents0 = [{x: 1, y: 1, c: "0"}, {x: 2, y: 2, c: "1"}];
asgn0 = pts.map(p => ({...p, c: "-1"}));
asgn1 = pts.map(p => {
let d0 = Math.hypot(p.x - cents0[0].x, p.y - cents0[0].y);
let d1 = Math.hypot(p.x - cents0[1].x, p.y - cents0[1].y);
return {...p, c: d0 < d1 ? "0" : "1"};
});
cents1 = cents0;
cents2 = [
{x: (1+1+2)/3, y: (1+2+1)/3, c: "0"},
{x: (8+9+8)/3, y: (8+8+9)/3, c: "1"}
];
asgn2 = asgn1;
asgn3 = pts.map(p => {
let d0 = Math.hypot(p.x - cents2[0].x, p.y - cents2[0].y);
let d1 = Math.hypot(p.x - cents2[1].x, p.y - cents2[1].y);
return {...p, c: d0 < d1 ? "0" : "1"};
});
cents3 = cents2;
currentAsgn = [asgn0, asgn1, asgn2, asgn3][step];
currentCents = [cents0, cents1, cents2, cents3][step];
Plot.plot({
width: 700,
height: 700,
grid: true,
x: {domain: [0, 10]},
y: {domain: [0, 10]},
marks: [
Plot.dot(currentAsgn, {x: "x", y: "y", fill: d => d.c === "-1" ? "gray" : (d.c === "0" ? "#1f77b4" : "#ff7f0e"), r: 10, stroke: "white", strokeWidth: 1}),
Plot.dot(currentCents, {x: "x", y: "y", fill: d => d.c === "0" ? "#1f77b4" : "#ff7f0e", r: 16, symbol: "star", stroke: "black", strokeWidth: 1.5})
]
})Mathematical Foundations of AI & ML
Unit 5: Clustering and Autoencoders




What counts as “structure”?
Compactness
Points within a group are close.
Separation
Groups are far from each other.
Plus: the structure must be interpretable — relate to something we care about (alloy family, defect type, processing regime). A “good” cluster on a materials dataset is one a metallurgist can explain.
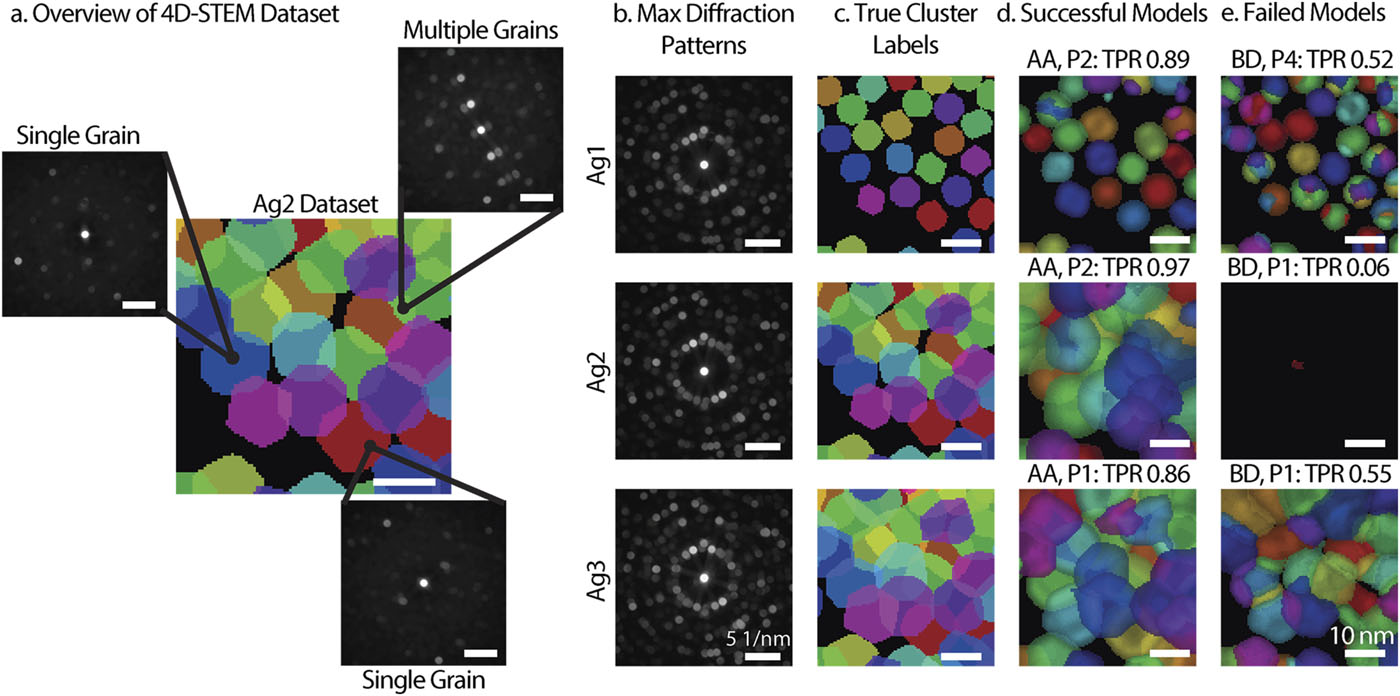
Overview of 4D-STEM with the visual representation of datasets and results. (a) Diagram of the 4D-STEM dataset. (b) Maximum diffraction patterns and (c) true cluster labels for the three simulated datasets, Ag1 (top), Ag2 (middle), and Ag3 (bottom). (d) Example of a successful model for each dataset. (e) Example of a failed model for each dataset. (Bruefach et al. 2023)
K-means: objective and Lloyd’s algorithm
Assign \(N\) points \(\{x_1, \ldots, x_N\} \subset \mathbb{R}^d\) to \(K\) groups \(C_1, \ldots, C_K\) by minimizing:
\[ J(C_1, \ldots, C_K, \mu_1, \ldots, \mu_K) = \sum_{k=1}^{K} \sum_{x_i \in C_k} \|x_i - \mu_k\|^2. \]
The objective: each point should be close to its assigned centroid. Each cluster is represented by a single point \(\mu_k\).
Lloyd’s algorithm
Alternate two steps until assignments stop changing:
- Assign: for each \(i\), set \(C_k = \{x_i : k = \arg\min_j \|x_i - \mu_j\|^2\}\).
- Update: for each \(k\), set \(\mu_k = \frac{1}{|C_k|} \sum_{x_i \in C_k} x_i\).
This is coordinate descent on \(J\): each step strictly decreases \(J\) unless we are already at a fixed point. Convergence in finitely many steps is guaranteed.
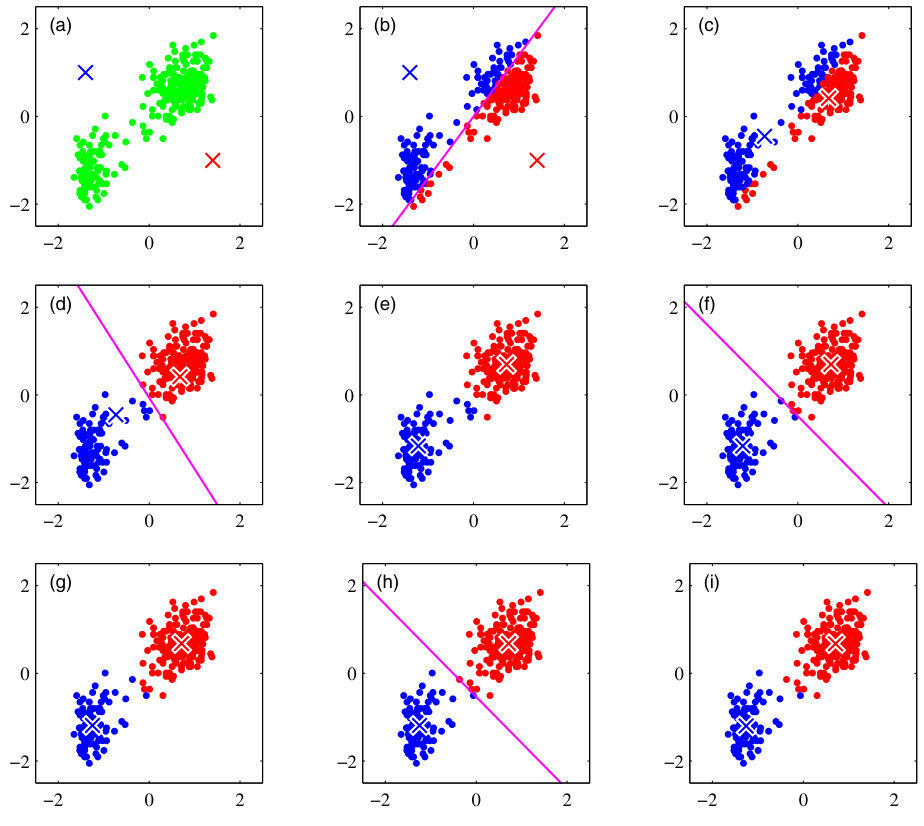
Choosing \(K\): the elbow method
- Run K-means for \(K = 1, 2, 3, \ldots, K_{\max}\).
- Plot \(J(K)\) vs \(K\).
- Look for the elbow: the point where \(J\) stops dropping fast.
- Heuristic, not principled, but widely used.
\(J(K)\) always decreases with \(K\) — at \(K = N\), every point is its own cluster and \(J = 0\).
The elbow signals diminishing returns from extra clusters.
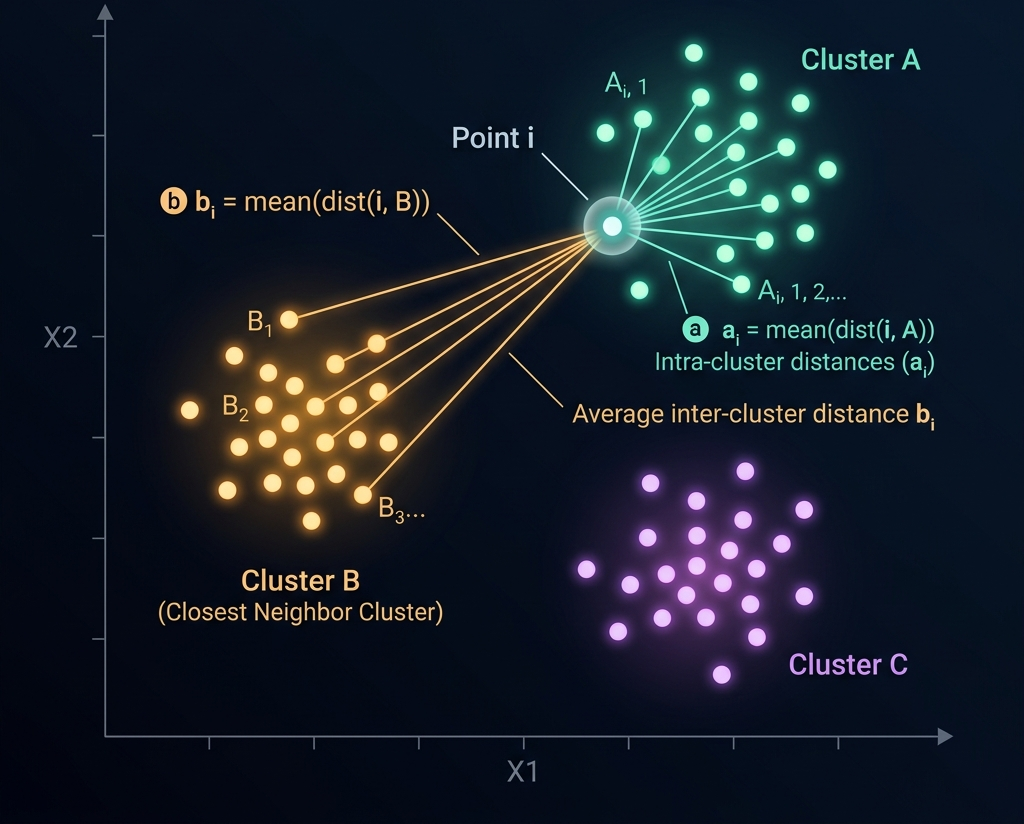
Choosing \(K\): the silhouette score
For each point \(x_i\), define:
\[ s(x_i) = \frac{b(x_i) - a(x_i)}{\max(a(x_i), b(x_i))}, \]
where \(a(x_i)\) is the average distance to other points in \(x_i\)’s cluster, and \(b(x_i)\) is the average distance to points in the nearest other cluster.
- \(s(x_i) \approx 1\): well-clustered. \(s(x_i) \approx 0\): on a boundary. \(s(x_i) < 0\): probably misclustered.
- Pick the \(K\) that maximizes the mean silhouette.
K-medoids: a robust variant
- K-means uses the mean as a centroid → sensitive to outliers.
- K-medoids restricts the centroid to be an actual data point (the medoid).
- Update step: in each cluster, pick the point that minimizes the sum of distances to others.
- Slower (no closed-form update) but robust.
Useful when: outliers contaminate the data, or distances are non-Euclidean (e.g., edit distance for SMILES strings).

Hierarchical clustering: no \(K\) in advance
- Agglomerative: start with each point as its own cluster; repeatedly merge the closest pair.
- Divisive: start with one big cluster; recursively split.
- Linkage criteria for “closest”:
- Single: nearest pair across clusters (chains).
- Complete: farthest pair (compact).
- Average: mean pair distance.
- Ward: minimize variance increase (popular default).

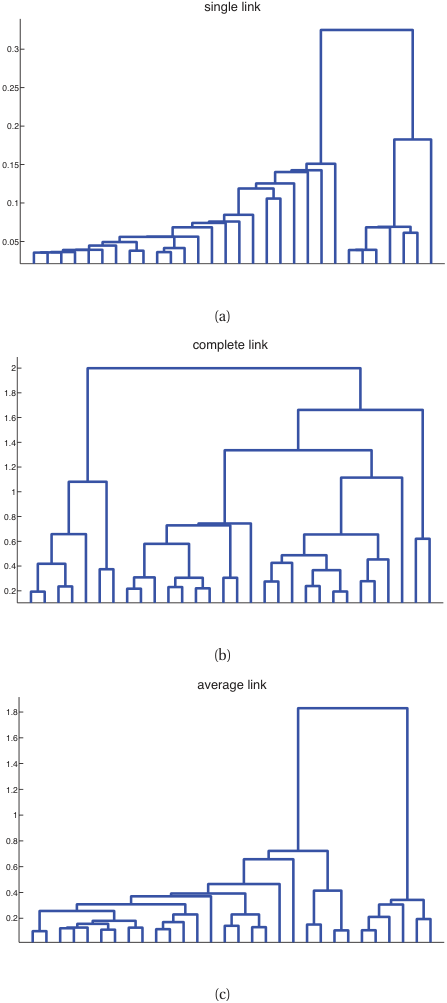
Dendrograms
- The merge sequence is a tree: leaves are points, internal nodes are merges, height = merge distance.
- Cut the dendrogram at any height to obtain a clustering.
- Materials use case: dendrograms over compositions reveal natural alloy families and the heights tell you how distinct each family is.
- Linkage choice matters: single, complete, average, or Ward produce qualitatively different trees.
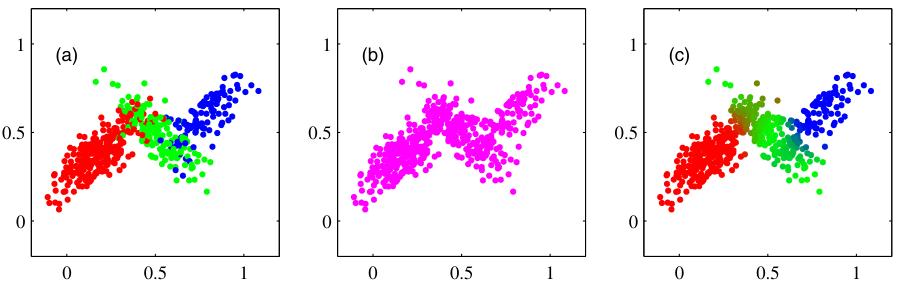
From hard to soft assignments
- K-means gives a hard assignment: each point belongs to exactly one cluster.
- Reality: a point near a boundary could plausibly belong to either neighbor.
- A soft assignment gives a probability over clusters: \(\gamma_{ik} = P(\text{cluster } k \mid x_i)\).
- Soft assignments come naturally from a probabilistic model: the Gaussian Mixture Model.
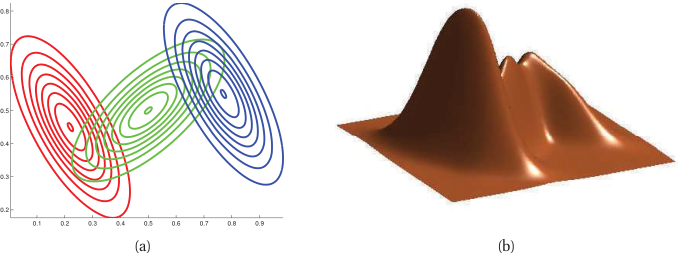
Gaussian Mixture Model (GMM)
A weighted sum of \(K\) Gaussian densities:
\[ p(x) = \sum_{k=1}^{K} \pi_k \mathcal{N}(x; \mu_k, \Sigma_k), \qquad \pi_k \geq 0, \quad \sum_k \pi_k = 1. \]
- \(\pi_k\): mixture weight (prior probability of cluster \(k\)).
- \(\mu_k\): cluster center; \(\Sigma_k\): cluster shape (covariance).
- Each \(\mathcal{N}(x; \mu_k, \Sigma_k)\) is a multivariate Gaussian — Unit 7 will derive these formally.
EM algorithm: E-step
For each point \(i\) and cluster \(k\), compute the responsibility:
\[ \gamma_{ik} = P(z_i = k \mid x_i, \theta) = \frac{\pi_k \mathcal{N}(x_i; \mu_k, \Sigma_k)}{\sum_{j} \pi_j \mathcal{N}(x_i; \mu_j, \Sigma_j)}. \]
This is the soft assignment: how strongly does the model believe point \(i\) belongs to cluster \(k\), given the current parameters?
EM algorithm: M-step
Update parameters using the responsibilities:
\[ \mu_k = \frac{\sum_i \gamma_{ik} x_i}{\sum_i \gamma_{ik}}, \qquad \Sigma_k = \frac{\sum_i \gamma_{ik} (x_i - \mu_k)(x_i - \mu_k)^T}{\sum_i \gamma_{ik}}, \qquad \pi_k = \frac{1}{N}\sum_i \gamma_{ik}. \]
Each update is a weighted average — points contribute to a cluster in proportion to their responsibility.
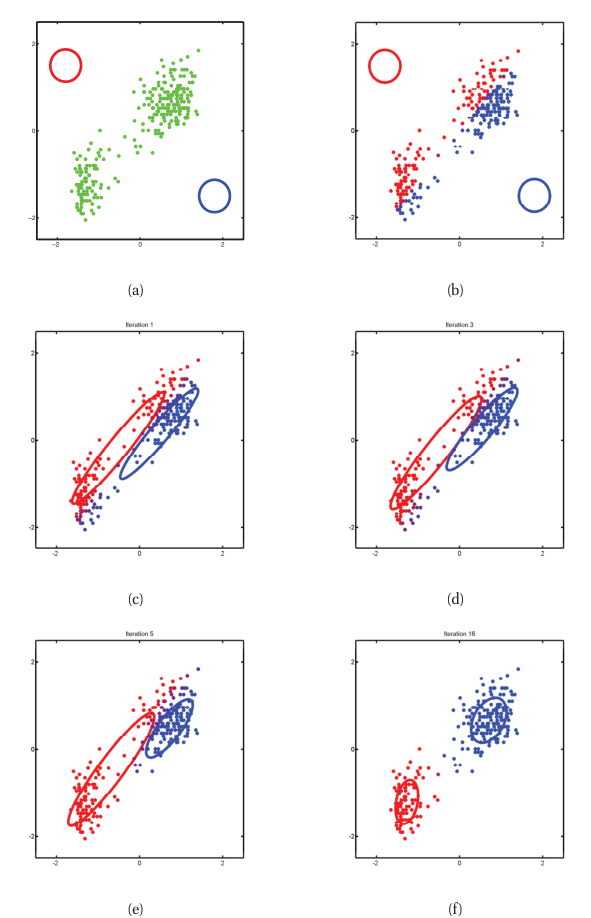
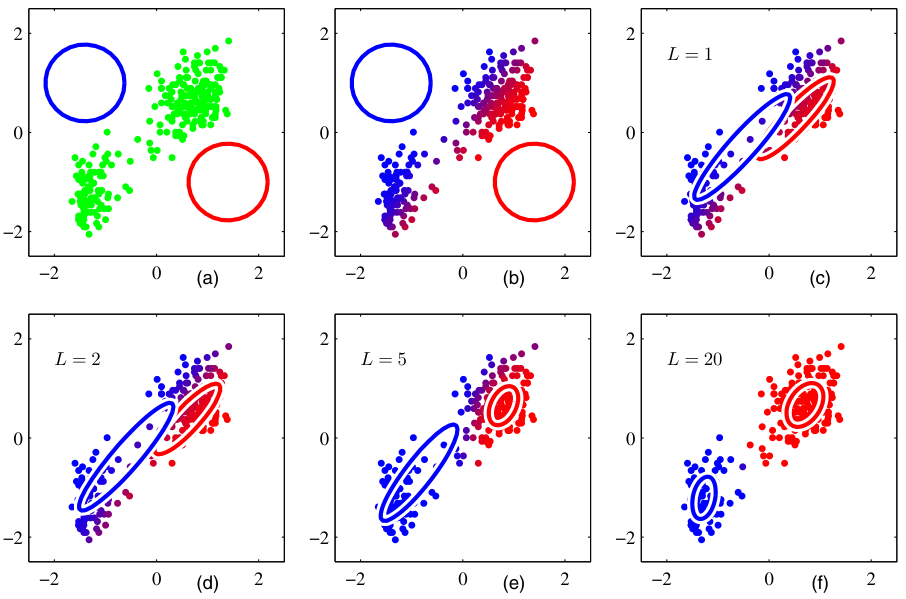
EM as alternating optimization
- Initialize \(\{\pi_k, \mu_k, \Sigma_k\}\) (e.g., from K-means output).
- E-step: compute all \(\gamma_{ik}\) given current parameters.
- M-step: update parameters given current \(\gamma_{ik}\).
- Repeat until log-likelihood converges.
Property: each EM iteration is guaranteed not to decrease the data log-likelihood \(\sum_i \log p(x_i; \theta)\). (Proof: EM optimizes a lower bound on the log-likelihood — Bishop Ch. 9 has the full derivation.)
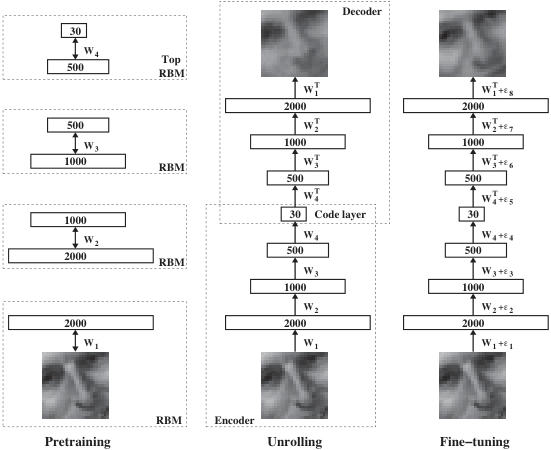
The autoencoder architecture
encoder decoder
x ──────► z (bottleneck) ──────► x̂
R^d R^k (k ≪ d) R^d- Encoder \(f_\phi: \mathbb{R}^d \to \mathbb{R}^k\): compresses input to a code \(z\).
- Bottleneck \(z \in \mathbb{R}^k\): forced low-dimensional representation.
- Decoder \(g_\theta: \mathbb{R}^k \to \mathbb{R}^d\): reconstructs input from code.
- Loss: reconstruction error, typically MSE.
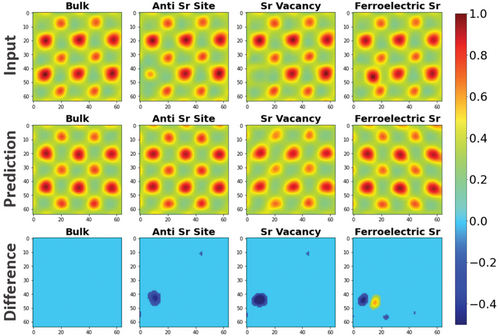
Application 1 — anomaly detection
- Train the AE only on normal data.
- At test time, compute reconstruction error per sample.
- Anomalies (defects, instrument failures, novel phases) reconstruct poorly — they’re outside the manifold the AE learned.
- Threshold: choose at, say, the 99th percentile of training reconstruction error.
Short Story: Crystal Defect Detection Prifti et al. (2023) used a Convolutional Variational Autoencoder (CVAE) on Scanning Transmission Electron Microscopy (STEM) images. Trained purely on perfect crystal lattices, the CVAE flags point defects (e.g., vacancies or anti-sites) simply because it fails to reconstruct them. It identifies anomalies without ever seeing a defect during training!
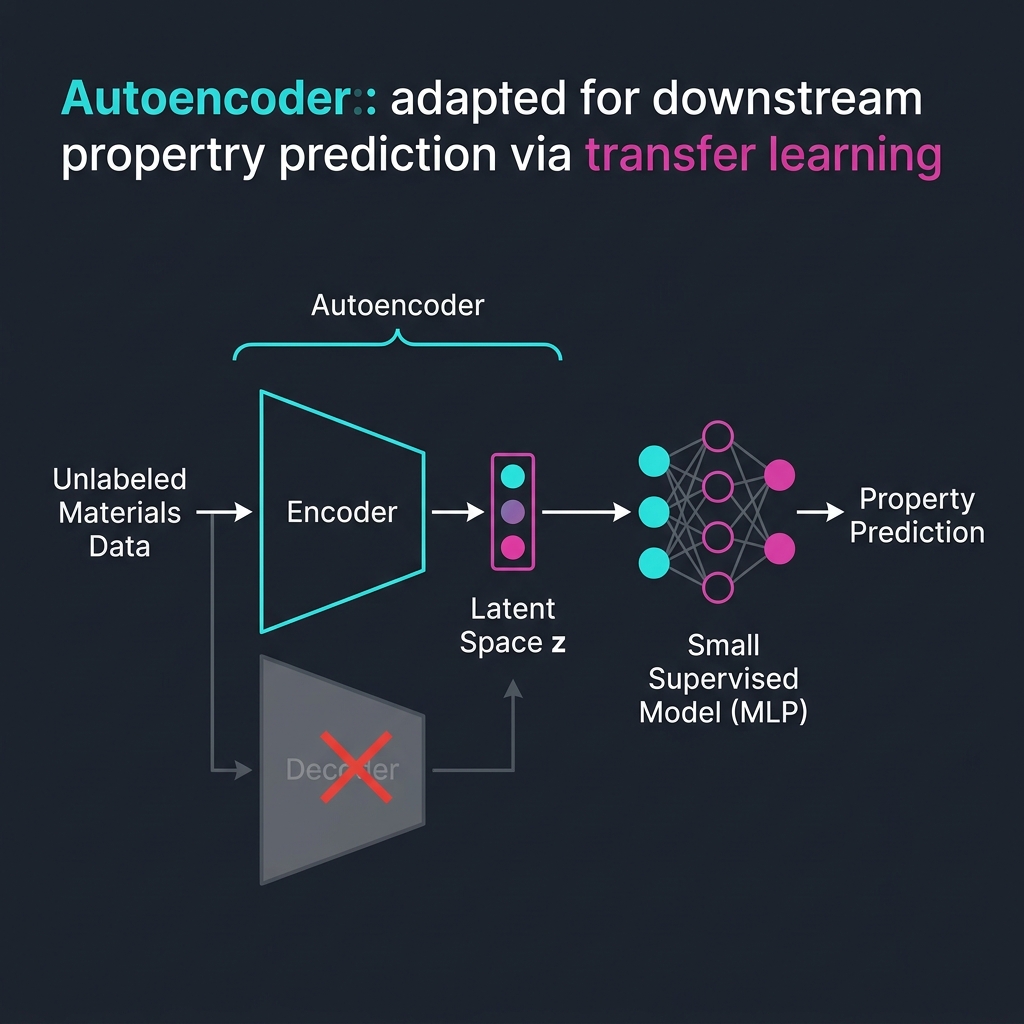
Application 2 — features for downstream tasks
- Train an AE on a large unlabeled corpus.
- Discard the decoder; use the encoder \(z = f_\phi(x)\) as a feature extractor.
- Train a small supervised model (linear regression, MLP) on \(z\) instead of \(x\).
- Works when labels are scarce and the AE has seen enough unlabeled data to learn the manifold.
This is transfer learning with self-supervision — a precursor to today’s foundation models.
The latent space is a coordinate system
- The bottleneck \(z\) is not just a compression target — it is a learned coordinate system for the data.
- Two questions about a latent space:
- Geometry: how are points arranged? Are similar samples close?
- Interpolation: does the line between \(z_A\) and \(z_B\) correspond to a smooth transition in \(x\)?