Mathematical Foundations of AI & ML
Unit 8: Generalization, Bias-Variance, and Regularization
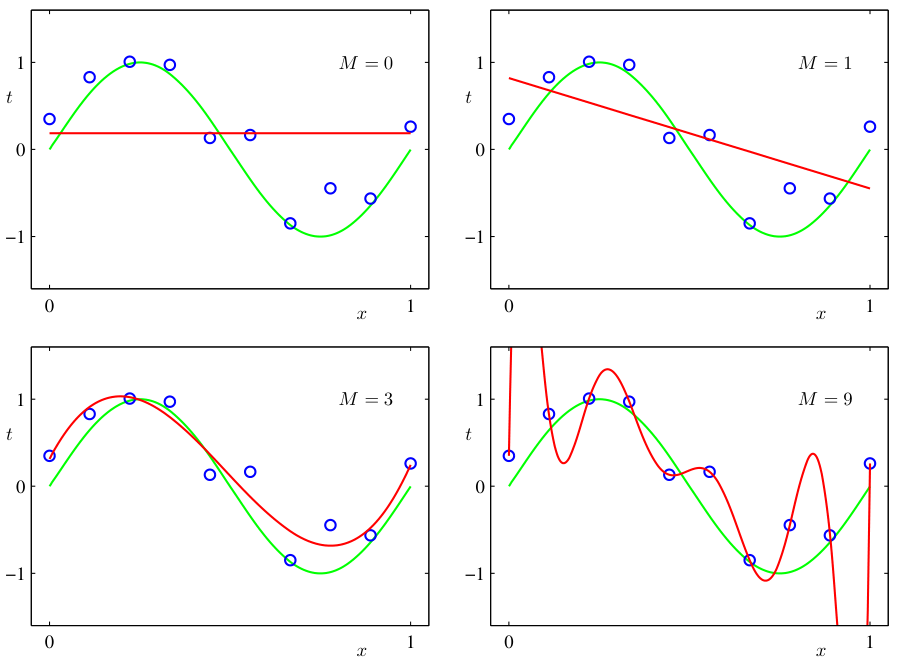
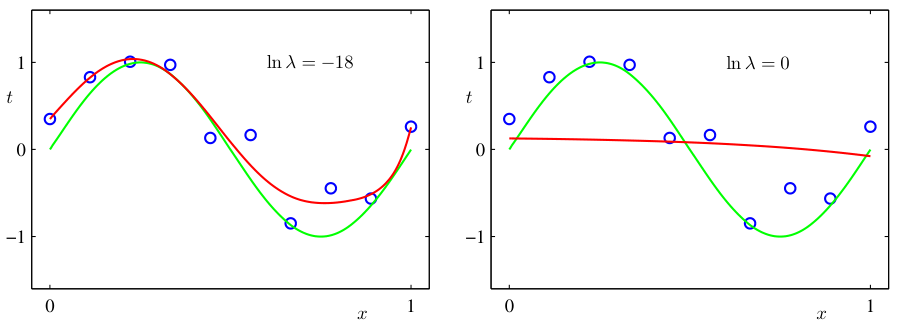
Overfitting — definition and visual example
- Overfitting: the model captures noise and idiosyncrasies of the training data instead of the underlying signal.
- Symptom: training error is very low, test error is high.
- Visual: a high-degree polynomial passes through every training point but oscillates wildly between them.
- M = 9 (bottom right) has zero training error but wild oscillations everywhere else.
Detecting overfitting in practice
- Plot training loss and validation loss over training epochs.
- Healthy: both decrease and converge.
- Overfitting: training loss continues to decrease while validation loss starts increasing.
- The divergence point suggests when to stop training (early stopping) [@neuer2024machine].

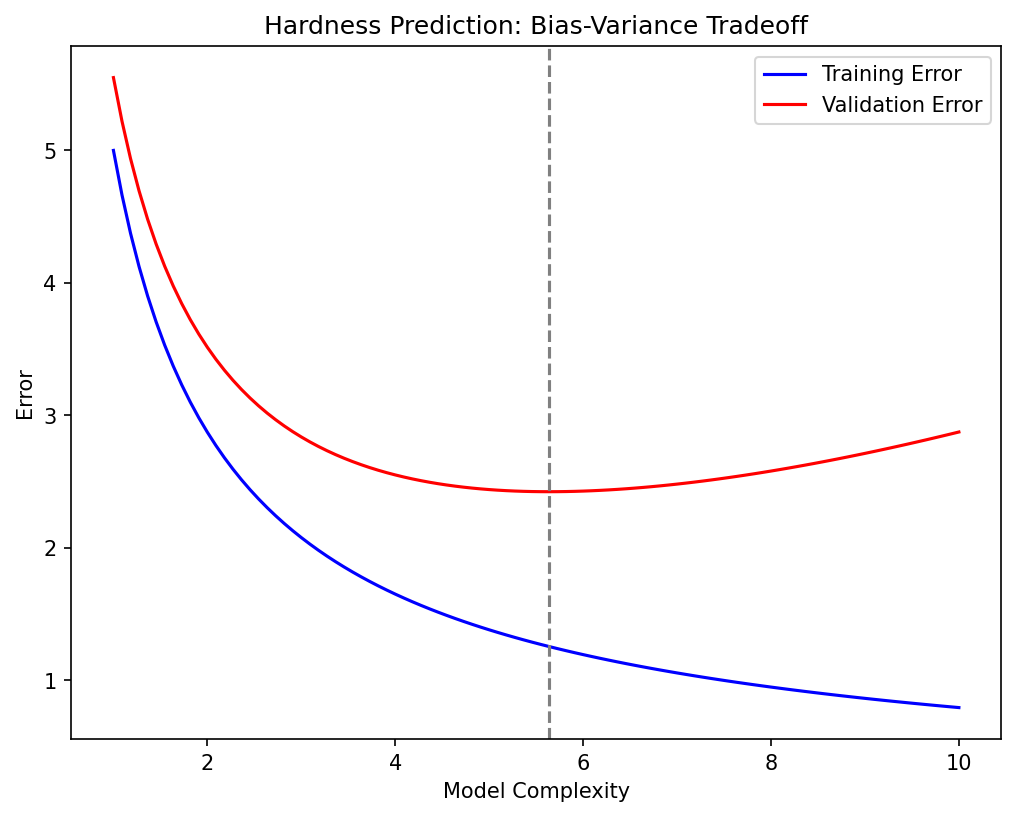
The bias-variance tradeoff
- Increasing complexity: bias decreases (model can fit more patterns), variance increases (model fits noise too).
- Decreasing complexity: variance decreases (model is stable), bias increases (model misses structure).
- Optimal complexity minimizes the sum Bias² + Variance.
- This is the most fundamental tradeoff in machine learning [@murphy2012machine].
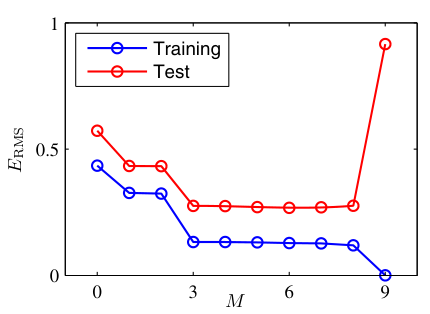
Visual: U-shaped total error curve — from data
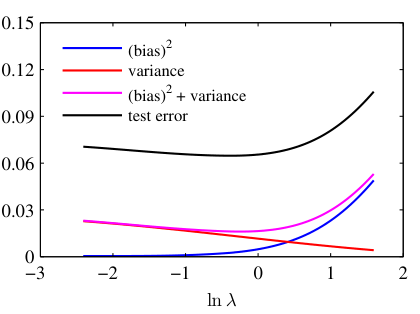
Bias², variance, and their sum vs regularization strength ln(λ). The minimum of Bias² + Variance (≈ ln λ = −0.31) closely matches the test-set error minimum — the operational sweet spot [@bishop2006pattern, Fig. 3.6].
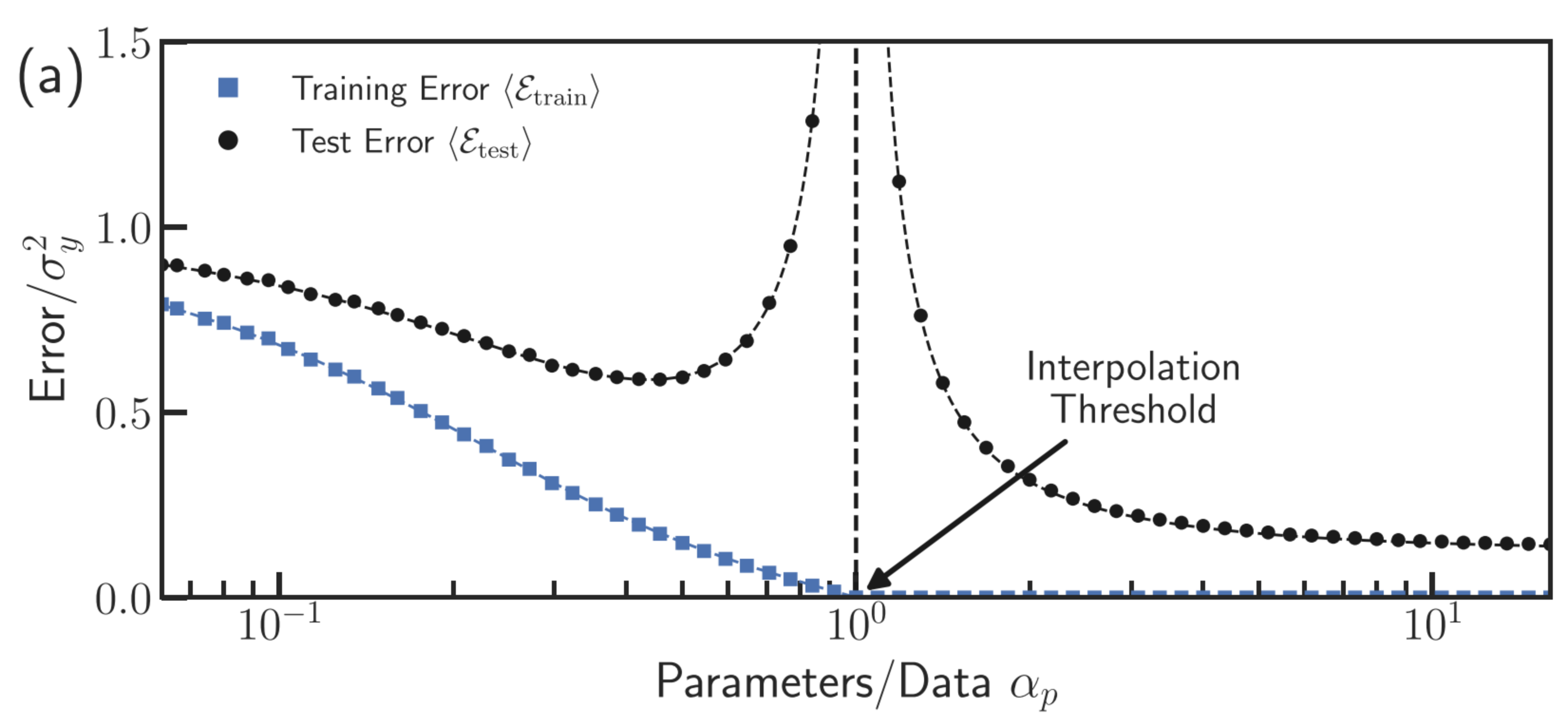
Modern view: double descent
- Classical theory predicts a U-shaped test error curve: error falls, then rises with model complexity.
- Modern overparameterized models (deep neural networks) show a second descent: beyond the interpolation threshold, test error falls again.
- The interpolation threshold occurs when the number of parameters equals the number of training points.
- Beyond the threshold, the model is expressive enough to interpolate — but the minimum-norm solution generalizes well [@belkin2019reconciling; @nakkiran2020deep].
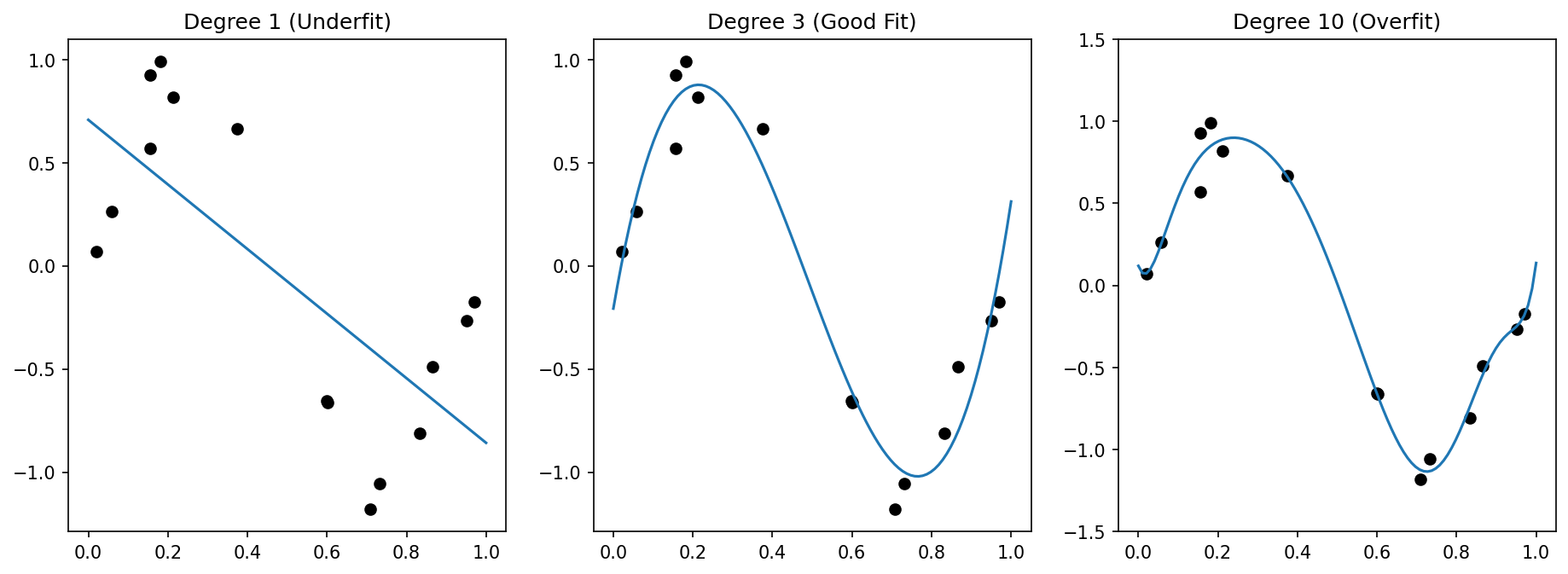
Example: polynomial regression
- Degree 1: high bias (line cannot capture curvature), low variance → underfitting.
- Degree 3–5: moderate bias and variance → good fit.
- Degree 15: low bias (passes through training points), high variance (oscillates wildly) → overfitting.
- The optimal degree depends on the data: amount of noise, sample size, true function complexity.
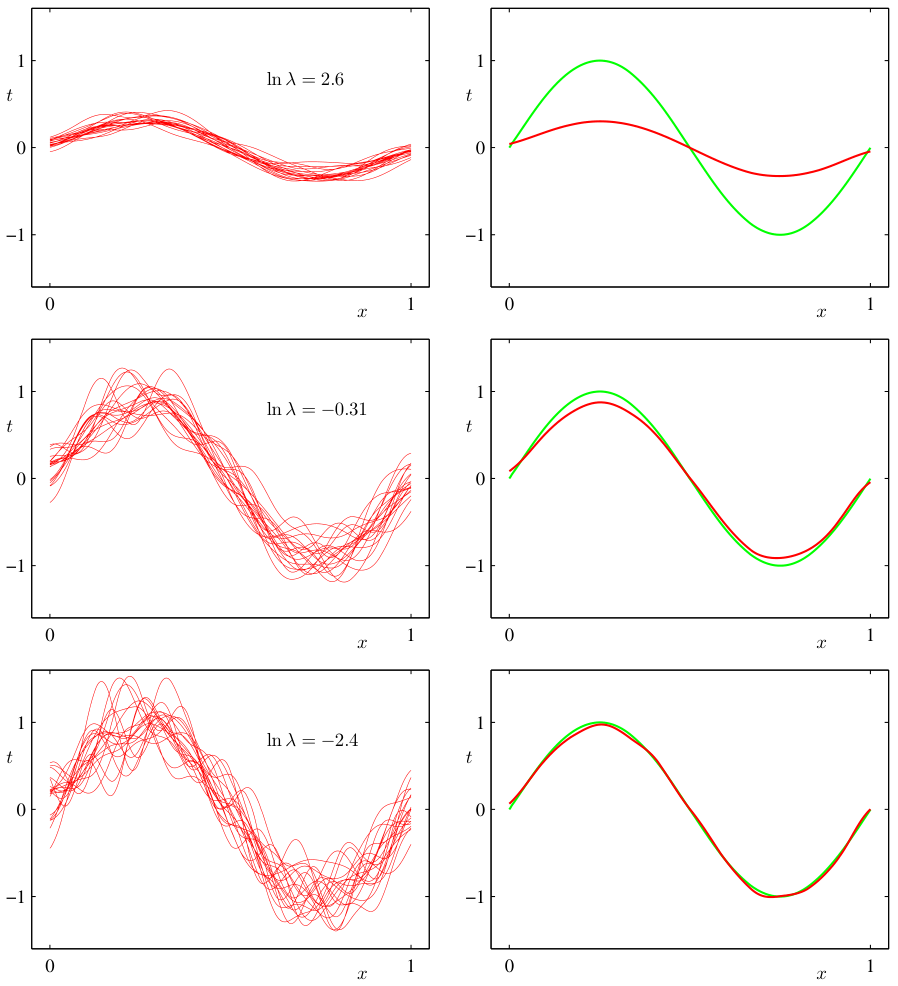
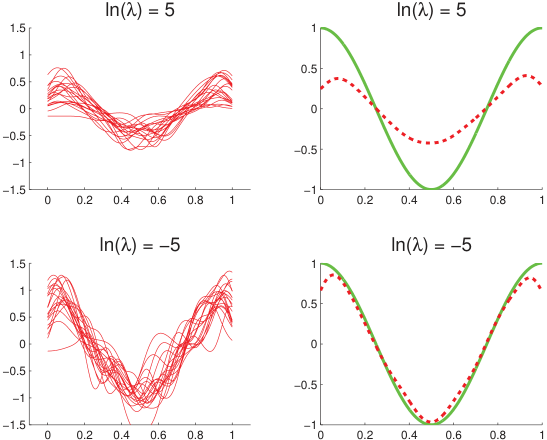
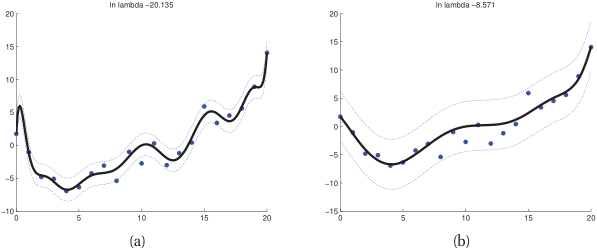
Example: Ridge regression and the tradeoff
- Ridge regression with regularization parameter \(\lambda\):
- High \(\lambda\): heavy shrinkage → high bias, low variance.
- Low \(\lambda\): minimal shrinkage → low bias, high variance.
- \(\lambda\) acts as a complexity knob that traces out the bias-variance tradeoff.
- Optimal \(\lambda\) minimizes total MSE, not training error [@murphy2012machine].
Ridge regression — closed-form solution
\[ \hat{\mathbf{w}}_{\text{ridge}} = (\mathbf{X}^\top\mathbf{X} + \lambda\mathbf{I})^{-1}\mathbf{X}^\top\mathbf{y} \]
- Adding \(\lambda\mathbf{I}\) makes the matrix always invertible (even if \(\mathbf{X}^\top\mathbf{X}\) is singular).
- This stabilizes the solution when features are correlated or \(p > N\).
- The closed form connects regularization directly to linear algebra [@mcclarren2021machine].
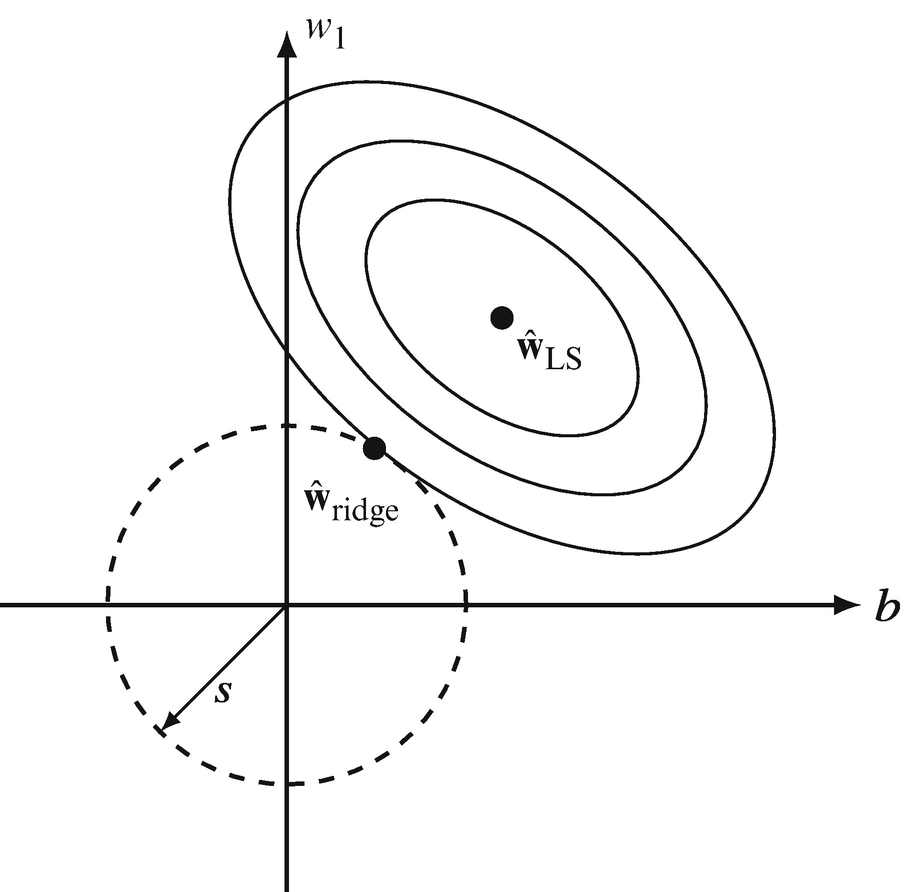
Ridge regression — geometric view
- The unconstrained optimum lies at the OLS solution.
- Ridge constrains the solution to lie within a sphere \(\|\mathbf{w}\|_2^2 \leq t\).
- The regularized solution is the point on the sphere closest to the OLS solution.
- Contour plot: elliptical loss contours intersect the circular constraint region.
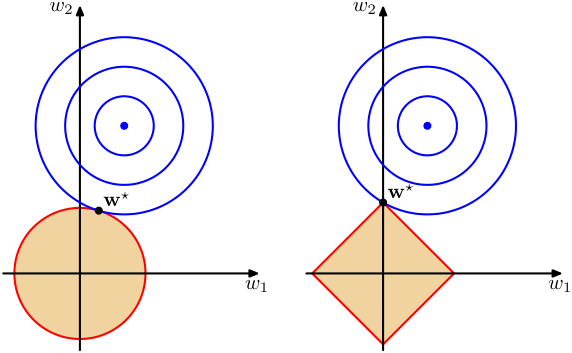
Lasso — geometric view and sparsity
- The L1 constraint region is a diamond (in 2D) or cross-polytope (in higher dimensions).
- The diamond has corners that lie on coordinate axes.
- Loss contours are more likely to intersect a corner → some coefficients become exactly zero.
- This geometric property is why L1 promotes sparsity while L2 does not [@mcclarren2021machine].
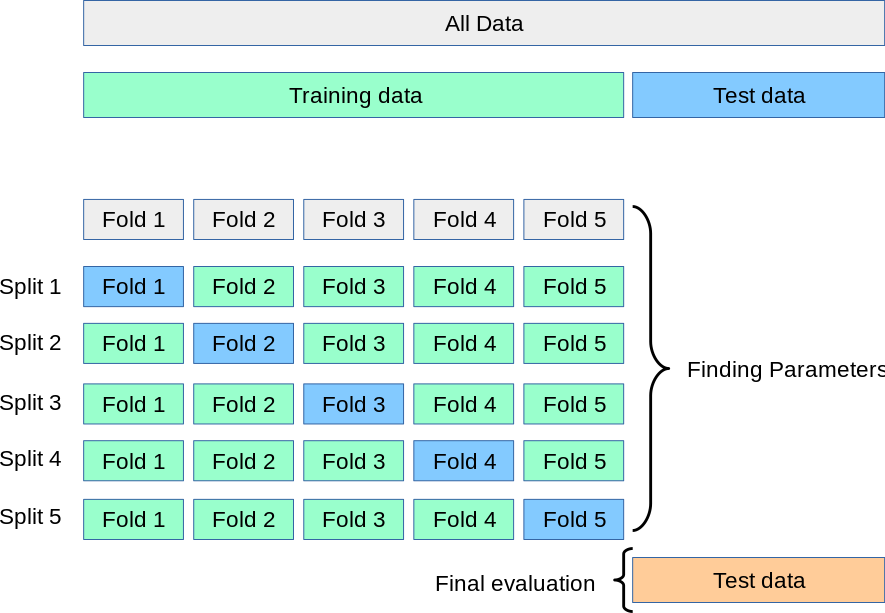
k-fold cross-validation — procedure
- Split data into \(k\) equal folds.
- For each fold \(j = 1, \dots, k\):
- Train on all folds except fold \(j\).
- Evaluate on fold \(j\).
- Average the \(k\) performance estimates:
\[ \text{CV}(k) = \frac{1}{k} \sum_{j=1}^{k} R_{\text{test}}^{(j)} \]
- Common choice: \(k = 5\) or \(k = 10\) [@neuer2024machine].
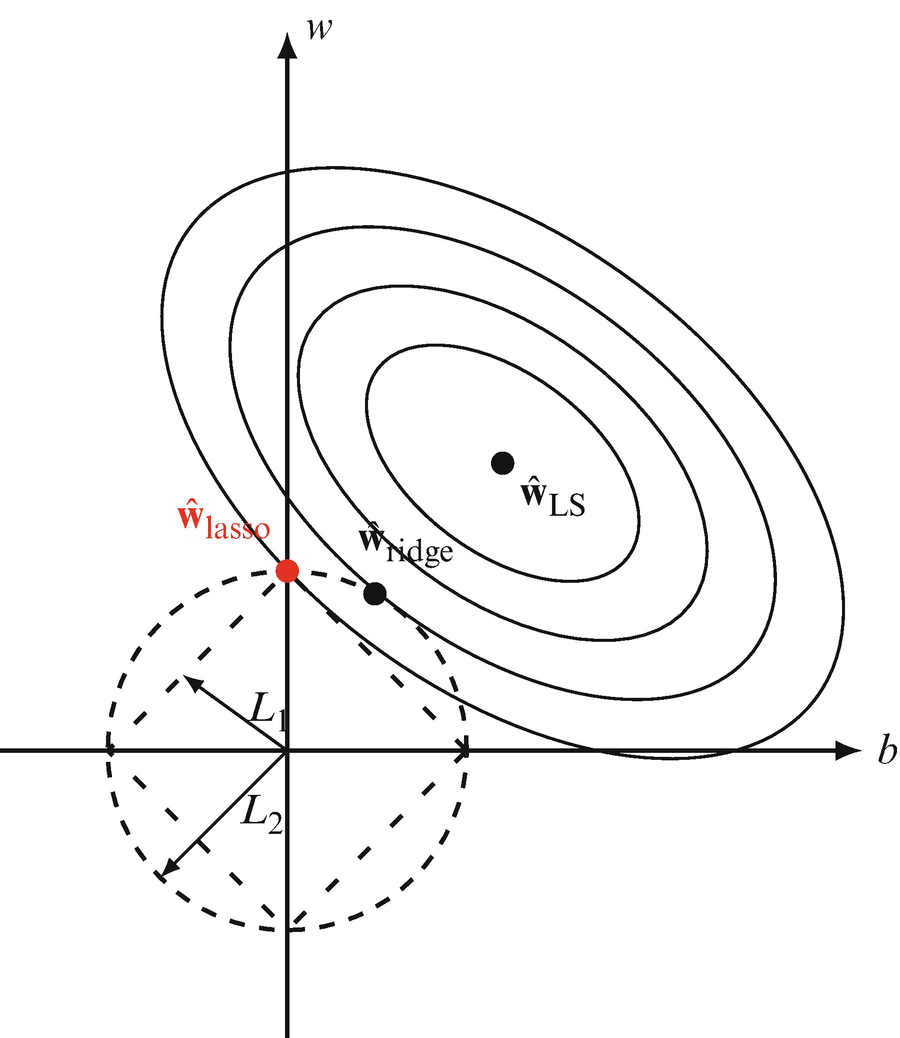
Choosing lambda via CV
- For each candidate \(\lambda\), compute the CV error \(\text{CV}(\lambda)\).
- Plot \(\text{CV}(\lambda)\) vs \(\log(\lambda)\).
- Select \(\lambda^*\) at the minimum of the CV curve.
- The one-standard-error rule: pick the simplest model within one SE of the minimum [@murphy2012machine].
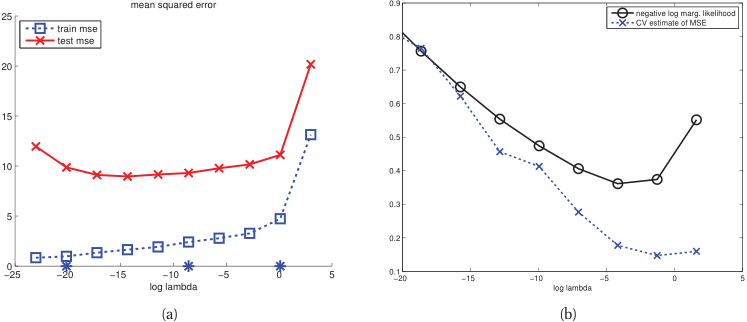
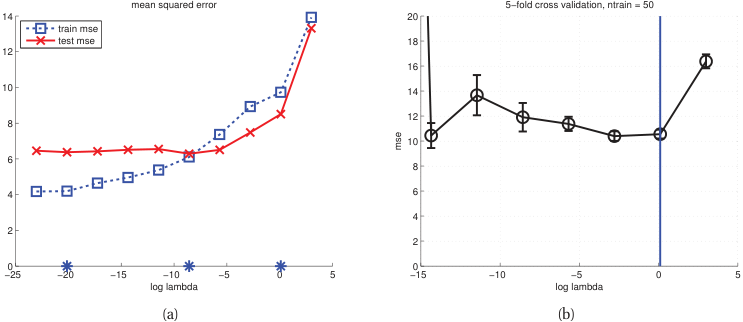
Materials example: overfitting in alloy property prediction
- Setting: predicting hardness from 50 compositional features using only 200 samples.
- Without regularization: the model memorizes training data and predicts poorly on new alloys.
- With Ridge regularization (\(\lambda\) selected via 5-fold CV): test error drops by 40%.
- Lesson: when \(p/N\) is large, regularization is not optional — it is essential.
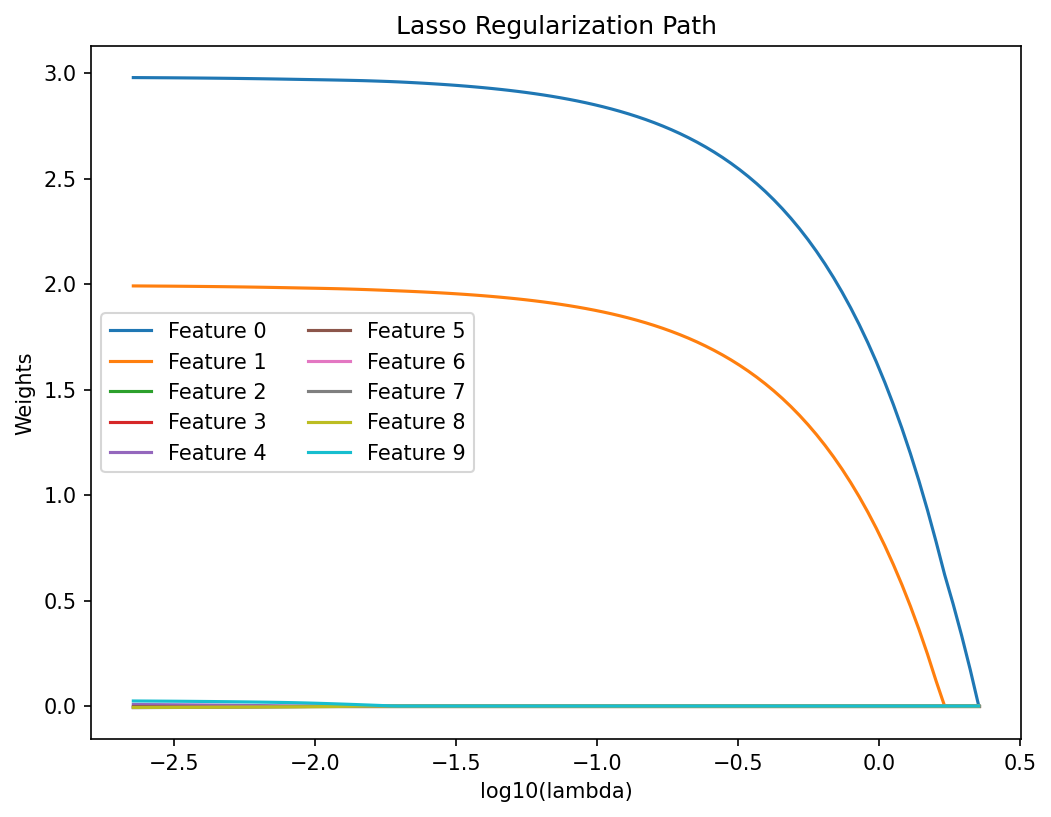
Materials example: Lasso for identifying governing features
- Starting from 100 candidate features (composition, processing, microstructure).
- Lasso with increasing \(\lambda\) progressively zeros out irrelevant features.
- The surviving features align with known physical mechanisms (grain size, carbon content, cooling rate).
- Lasso provides both prediction and interpretability.
Materials example: polynomial models for process-property curves
- A high-degree polynomial captures batch-to-batch noise in sintering temperature vs density data.
- A low-degree polynomial misses the genuine nonlinearity (plateau near full density).
- Cross-validation identifies degree 3 as the sweet spot for this dataset.
- This is the bias-variance tradeoff in action on real engineering data.
Example Notebook
Week 8: Overfitting & Regularization — IsingDataset (16×16)