Mathematical Foundations of AI & ML
Unit 9: Latent Spaces & Advanced Representation Learning




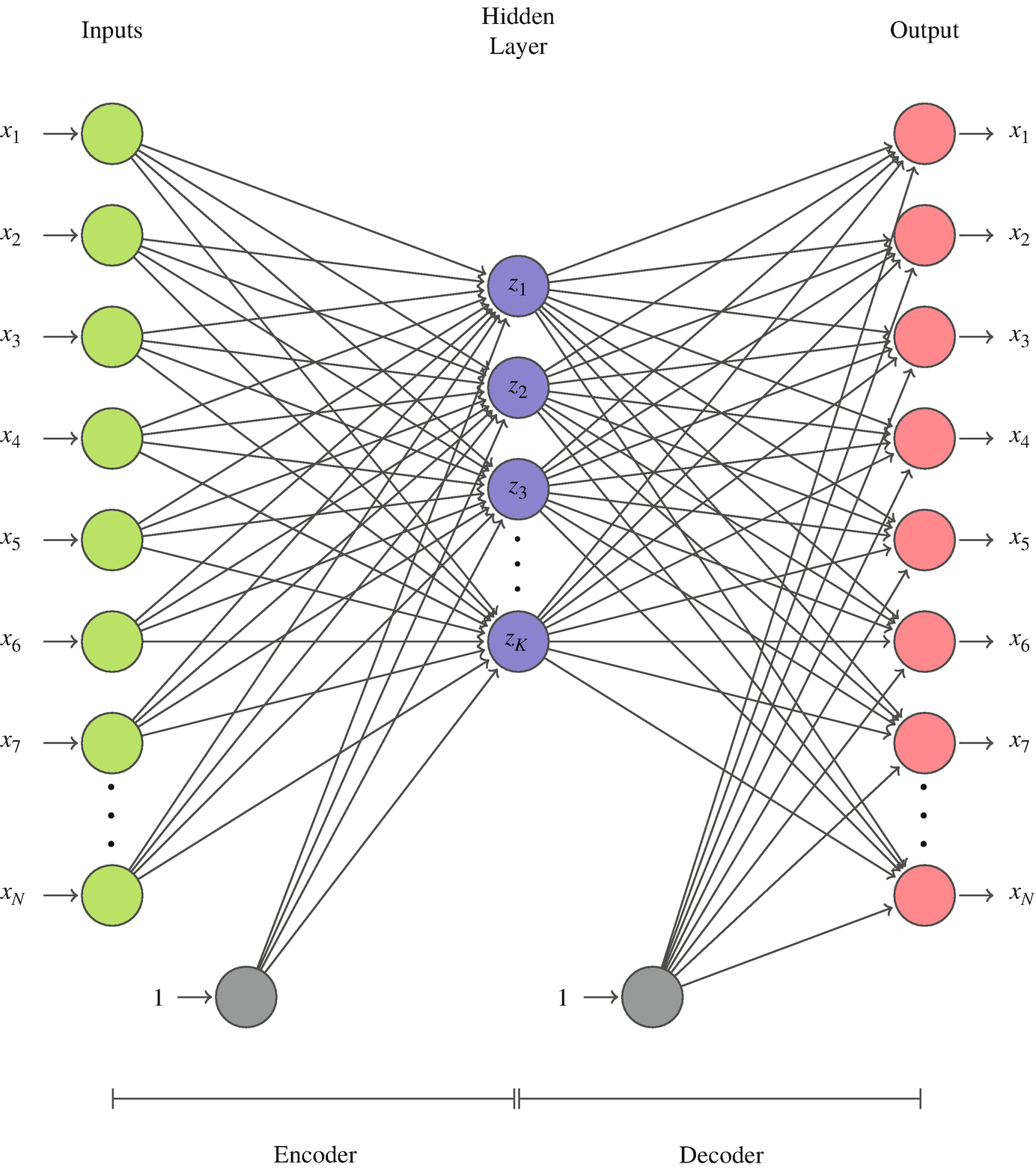
Recap: the autoencoder latent
- Encoder \(f_\phi: \mathbb{R}^d \to \mathbb{R}^k\) compresses.
- Decoder \(g_\theta: \mathbb{R}^k \to \mathbb{R}^d\) reconstructs.
- Loss: MSE reconstruction.
- The bottleneck \(z = f_\phi(x)\) is what we keep.
The reconstruction loss says only one thing: encode enough information to undo. It says nothing about whether similar inputs end up close, whether categories cluster, or whether interpolation is meaningful.
What is a “good” latent space?
Four desiderata, with examples that fail each:
- Compactness within concept: same-class samples are close. (Fails: AE trained on noisy spectra spreads each phase across the latent.)
- Separation across concepts: different-class samples are far. (Fails: AE pushes variance budget into reconstruction detail, not class separation.)
- Smooth interpolation: the line \(z_A \to z_B\) gives a smooth transition in \(x\)-space. (Fails: vanilla AE has “holes” that decode to nonsense.)
- Transferability: a small head on \(z\) for task A also works for task B. (Fails: AE features overfit to reconstruction artifacts.)
t-SNE: the goal
We have \(N\) high-dimensional points \(\{x_1, \ldots, x_N\} \subset \mathbb{R}^d\). We want low-dimensional points \(\{y_1, \ldots, y_N\} \subset \mathbb{R}^2\) such that:
points that are close in \(\mathbb{R}^d\) stay close in \(\mathbb{R}^2\).
This is harder than it sounds — distances in \(\mathbb{R}^d\) generally cannot all be preserved in \(\mathbb{R}^2\). t-SNE makes a specific trade-off: preserve local structure, sacrifice global structure.
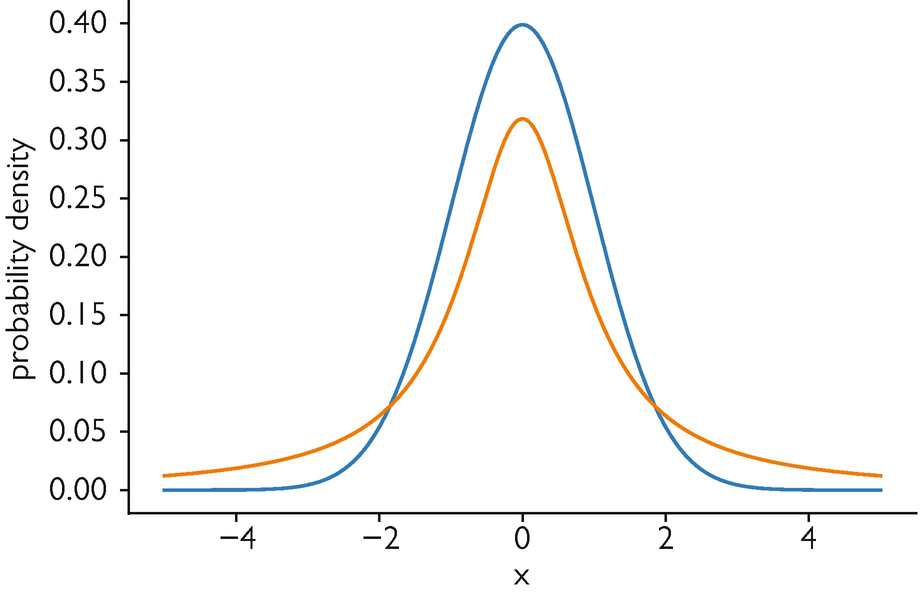
The crowding problem and the Student-t fix
A naive low-dim Gaussian \(q_{ij}^{\text{Gauss}} \propto \exp(-\|y_i - y_j\|^2)\) matched to \(P\) via \(\mathrm{KL}(P\|Q)\) breaks: in \(\mathbb{R}^2\) there is no room for the many moderate-distance neighbors that a high-dim shell affords (only ~6 fit at the same distance). The Gaussian’s tail forces an attractive collapse.
Fix: a heavy-tailed Student-t (1 d.o.f. = Cauchy) in low-dim,
\[ q_{ij} = \frac{(1 + \|y_i - y_j\|^2)^{-1}}{\sum_{k \neq l} (1 + \|y_k - y_l\|^2)^{-1}}. \]
Moderate distances stay possible without infinite force — the “t” in t-SNE.
Common t-SNE misinterpretations
- “These two clusters are 5× further apart than those two.” — between-cluster distance in t-SNE is not metric.
- “This cluster is bigger, so this class has more variance.” — cluster size and density are algorithm artifacts, not data properties.
- “Run looks different from yesterday’s run.” — yes; t-SNE is stochastic. Set a seed.
- “Same data, different perplexity, different structure.” — yes; perplexity changes the question being asked.
- Preserved: local neighborhoods. Not preserved: cluster sizes, between-cluster distances, density.
Read t-SNE plots qualitatively. Never quantitatively.

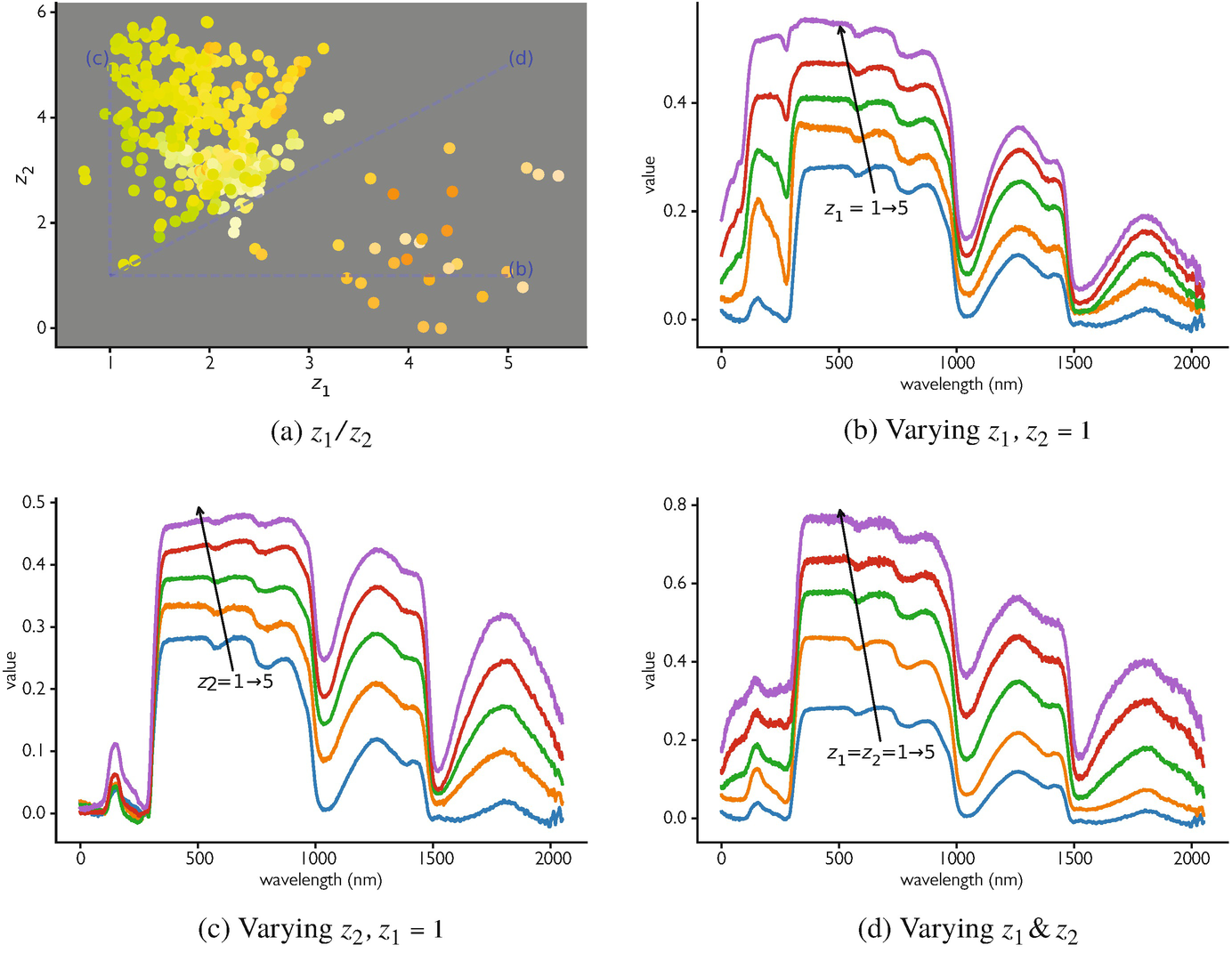
t-SNE on a materials dataset
Analogous benchmark: Fashion MNIST (10 clothing classes, 6000 images, 784 dims → 2 dims, perplexity 40)
- Useful: phase families / clothing classes form islands; outliers visible at the boundary.
- Not useful: don’t measure the gap between islands — that distance is meaningless.
- Note: t-shirts (cyan) and shirts (pink) overlap — their pixel structure is genuinely similar.
For materials: same logic applies to alloy-composition or spectral data.

UMAP — key hyperparameters and example
n_neighbors(analog of perplexity): local vs global trade-off. Low → local; high → global.min_dist: how tight clusters can be in the output.metric: cosine for normalised embeddings, Euclidean for raw features.- Both knobs are forgiving in practice; defaults (
n_neighbors=15,min_dist=0.1) usually work.
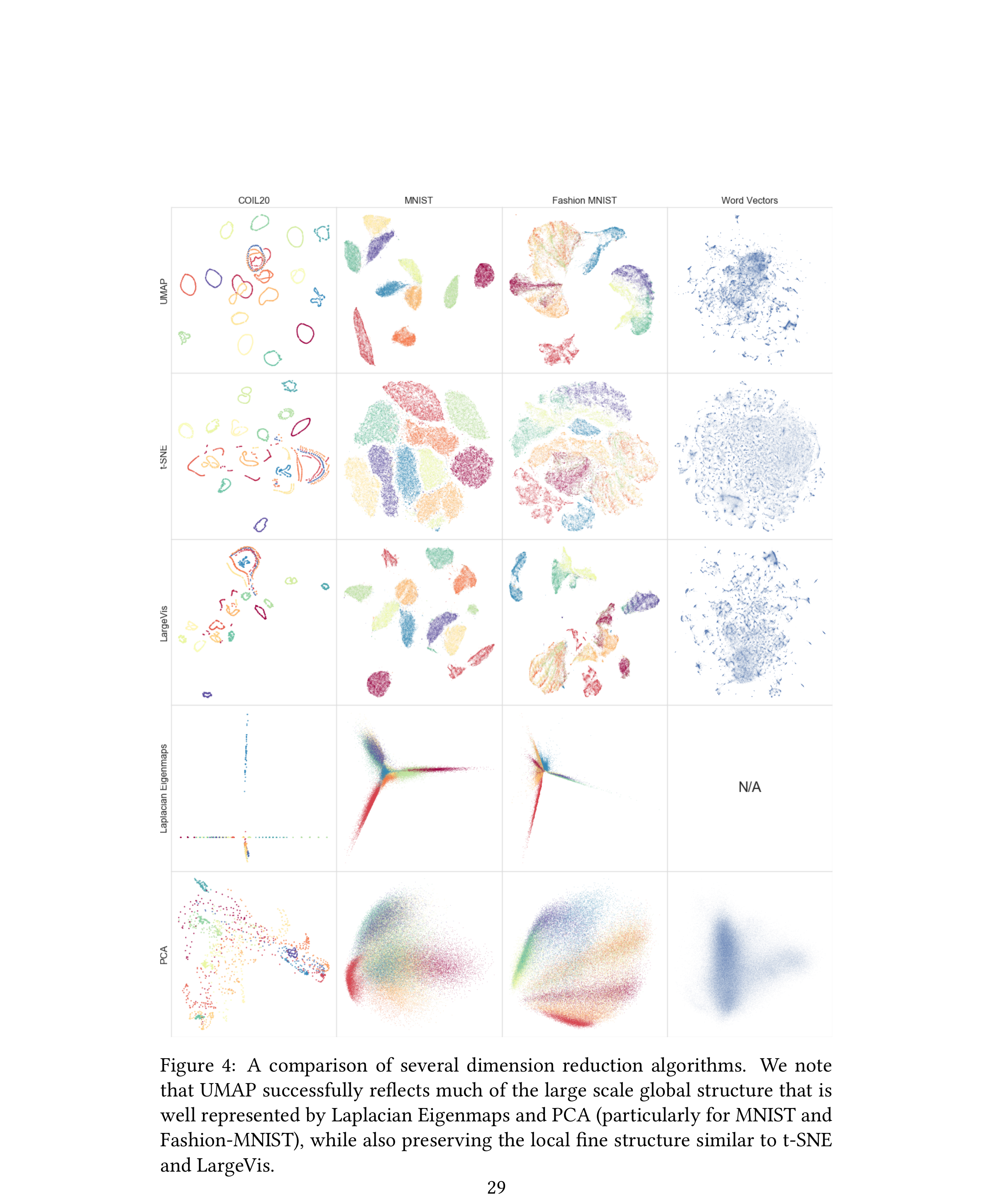
UMAP on a materials dataset
Setup. 1,800 steel-surface-defect micrographs (NEU-DET); DINOv2 (ViT-S/14) embeddings \(\in \mathbb{R}^{384}\); UMAP to \(\mathbb{R}^2\) with n_neighbors=30, min_dist=0.05, cosine metric.
- Steel defects (crazing, inclusion, patches, pitted, rolled-in scale, scratches) form distinct, visually coherent clusters.
- DINOv2 foundation embeddings encode rich semantic features: the model has never seen steel surface defects during training, yet naturally groups them by defect type.
- This zero-shot capability is what makes foundation models the modern starting point for materials microscopy.

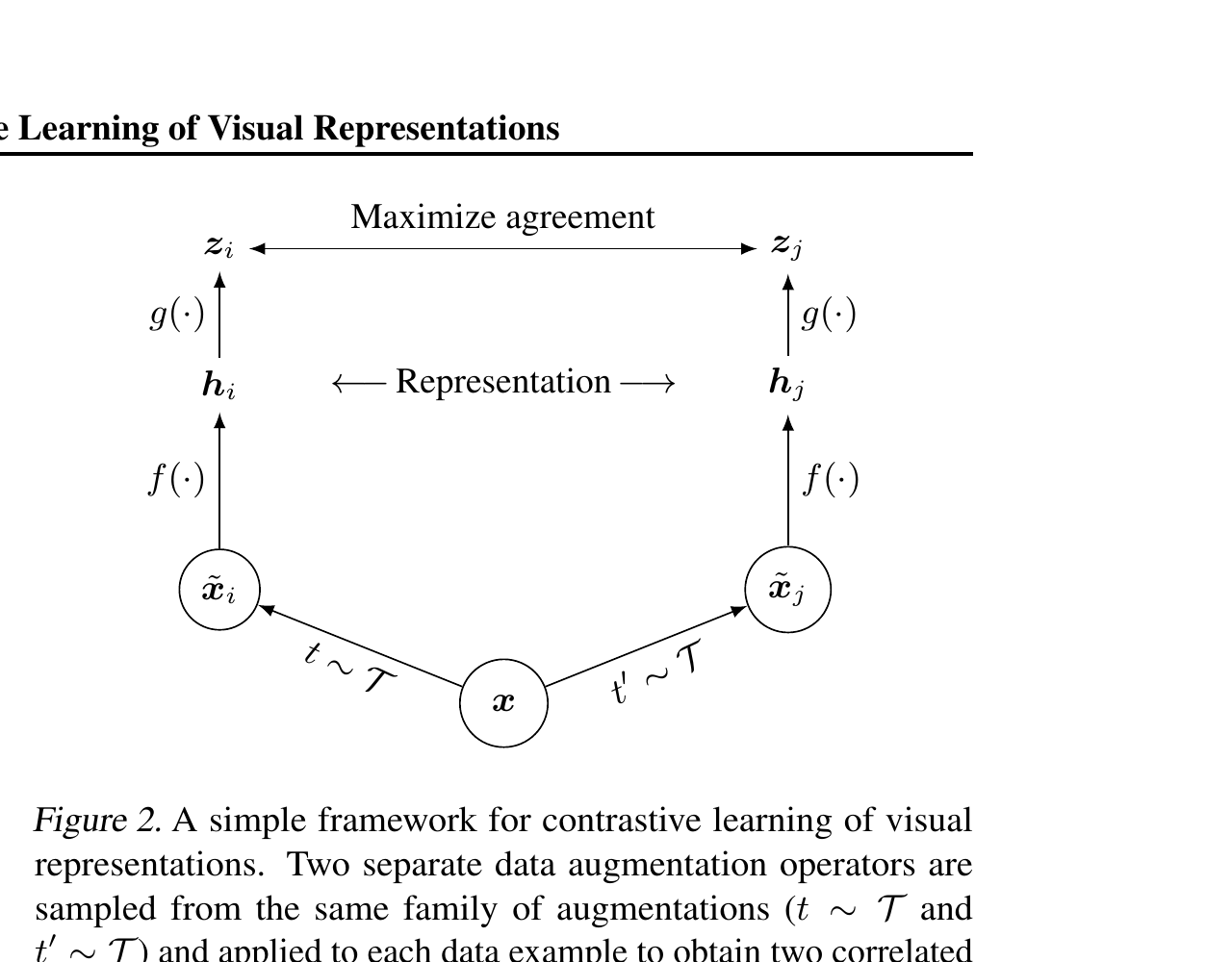
SimCLR: the canonical recipe
- Sample a batch of \(N\) inputs.
- Apply two random augmentations to each → \(2N\) samples.
- Pass through encoder \(f\) → projector \(g\) → embedding \(z_i\).
- For each \(z_i\), the matched-augmentation \(z_j\) is the positive; the other \(2N - 2\) are negatives.
- Loss: NT-Xent (a softmax-style normalized temperature-scaled cross-entropy).
Why foundation embeddings transfer
- Pre-training data: orders of magnitude more diverse than any single downstream task’s data.
- Self-supervised objective: forces the model to encode broadly useful features.
- The result: embeddings capture general structure of the input modality (images, text, etc.).
- For a downstream task: the relevant variation is usually present in the pre-trained embedding; you just need to select it (linear probe) or recombine it (fine-tuning).
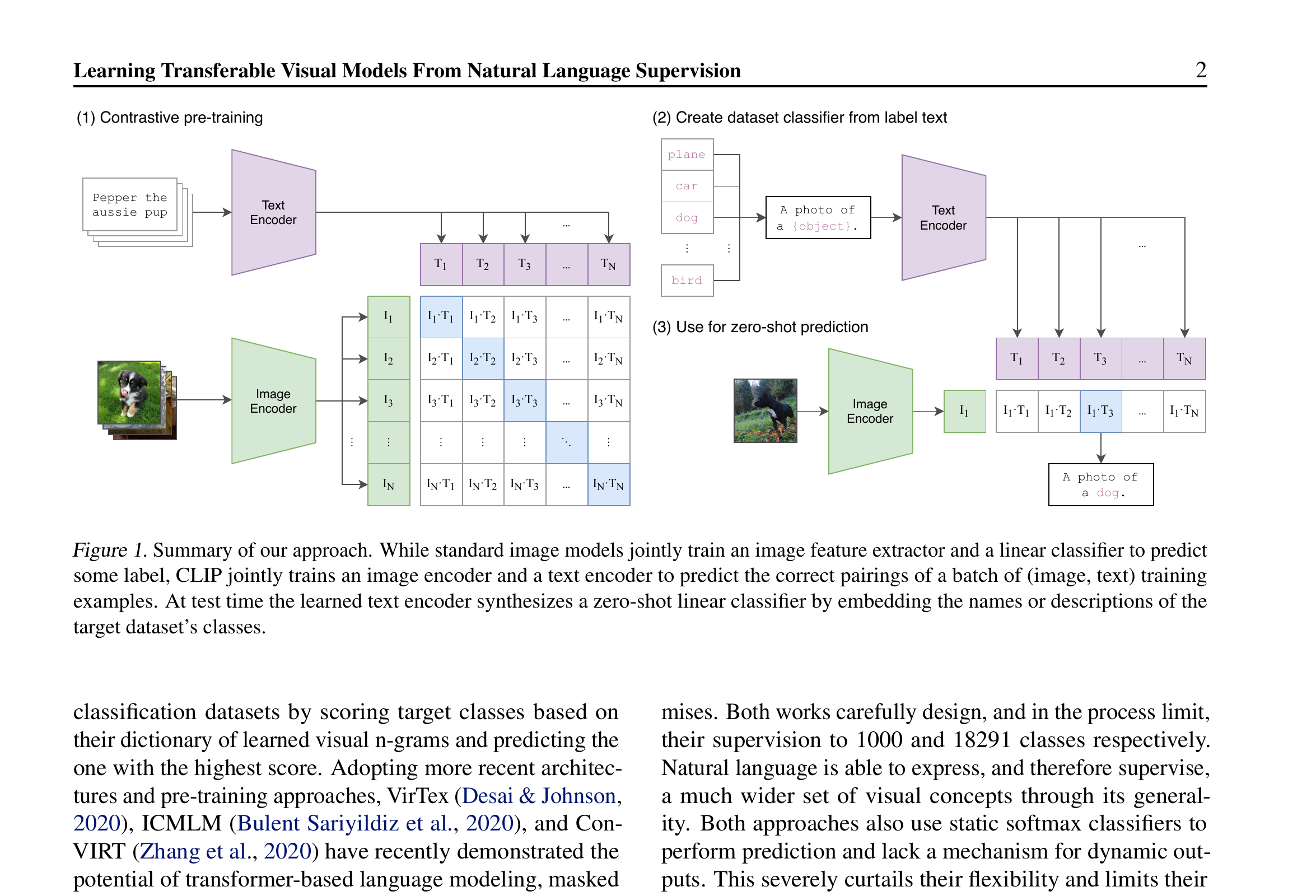
CLIP-style multimodal embeddings
Setup: pre-train on (image, caption) pairs.
- Image encoder \(f_I\), text encoder \(f_T\).
- Loss: contrastive — matching pairs nearby, mismatched far.
Result: a shared embedding space where text and images are comparable.
- Zero-shot classification: encode “a photo of a cat” and a candidate image; nearest text wins.
- Cross-modal retrieval: text → images, images → text.
Three ways to shape a latent
- Reconstruction (Unit 5 AE): “encode enough to undo.”
- Visualization optimization (t-SNE, UMAP): “preserve neighborhoods in 2-D.”
- Contrastive (SimCLR, foundation models): “encode invariances; pull positives, push negatives.”
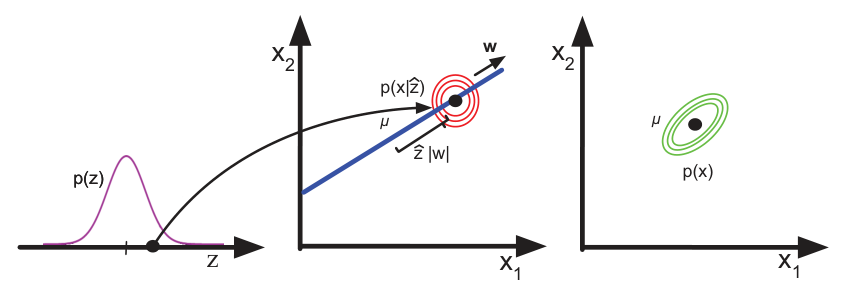
Missing from all three: an explicit, controllable distribution over \(z\) — necessary for sampling new data.
Latent space arithmetic — promise and limits
- In some learned latents, vector arithmetic is meaningful: \(z_{\text{property A}} - z_{\text{baseline}} + z_{\text{property B baseline}} \approx z_{\text{property B with A}}\).
- This works empirically in well-shaped latents; it is not guaranteed by the AE/contrastive objective.
- VAEs (Unit 11) shape the latent to be approximately Gaussian — making interpolation reliable and arithmetic principled.
