Mathematical Foundations of AI & ML
Unit 8: Tree Ensembles for Tabular Learning




First, the intuition: name that tree
You are a farmer with a new plot of land. For each tree you can measure only two things — the trunk’s diameter and its height — and you must decide: Apple, Cherry, or Oak?
- No equations yet. Just look at the scatter and ask: where would you draw lines to separate the colours?
- This is the whole idea of a decision tree: split the space with simple questions until each region is (almost) one kind of tree.
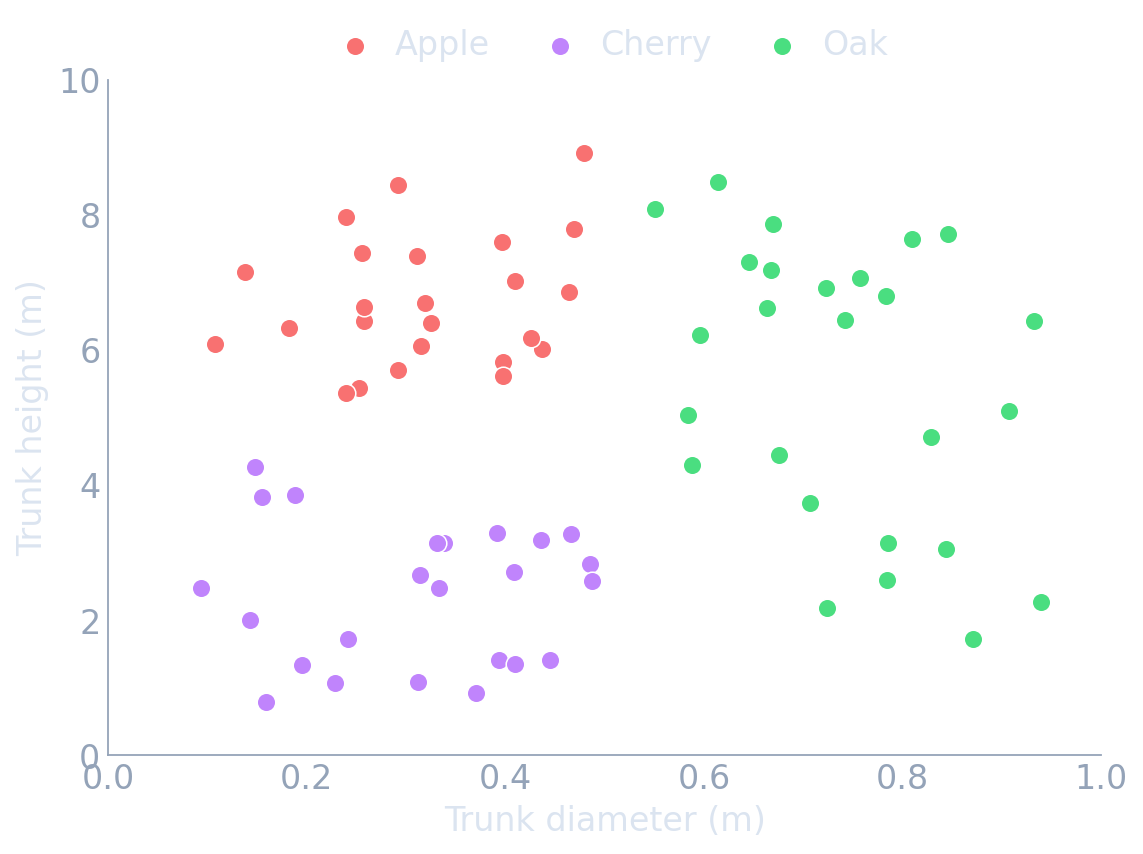
Carve the space with yes/no questions
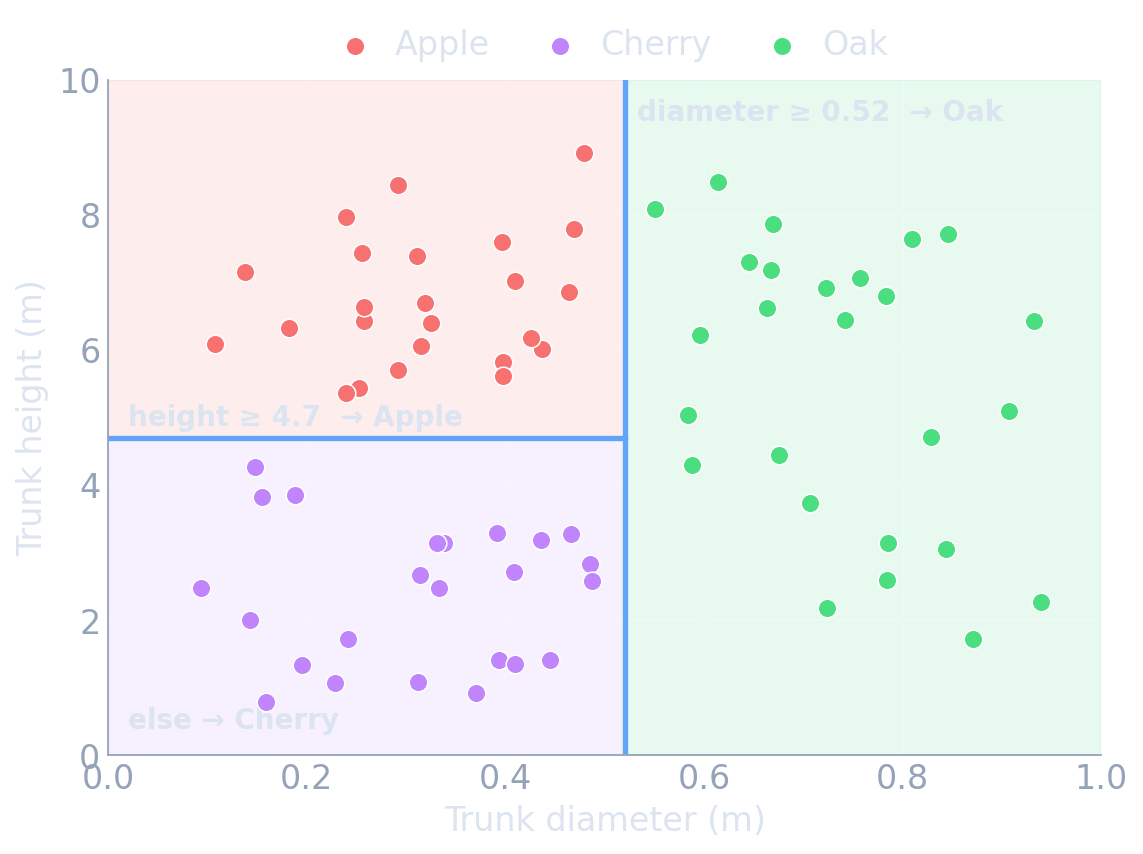
- First cut: diameter ≥ 0.52? → everything to the right is Oak.
- Second cut (left part only): height ≥ 4.7? → tall ones are Apple, short ones are Cherry.
- Each cut is a vertical or horizontal line — a question about one feature at a time.
- A new tree? Measure it, see which box it lands in, predict that box’s majority species.
…and that is literally a decision tree
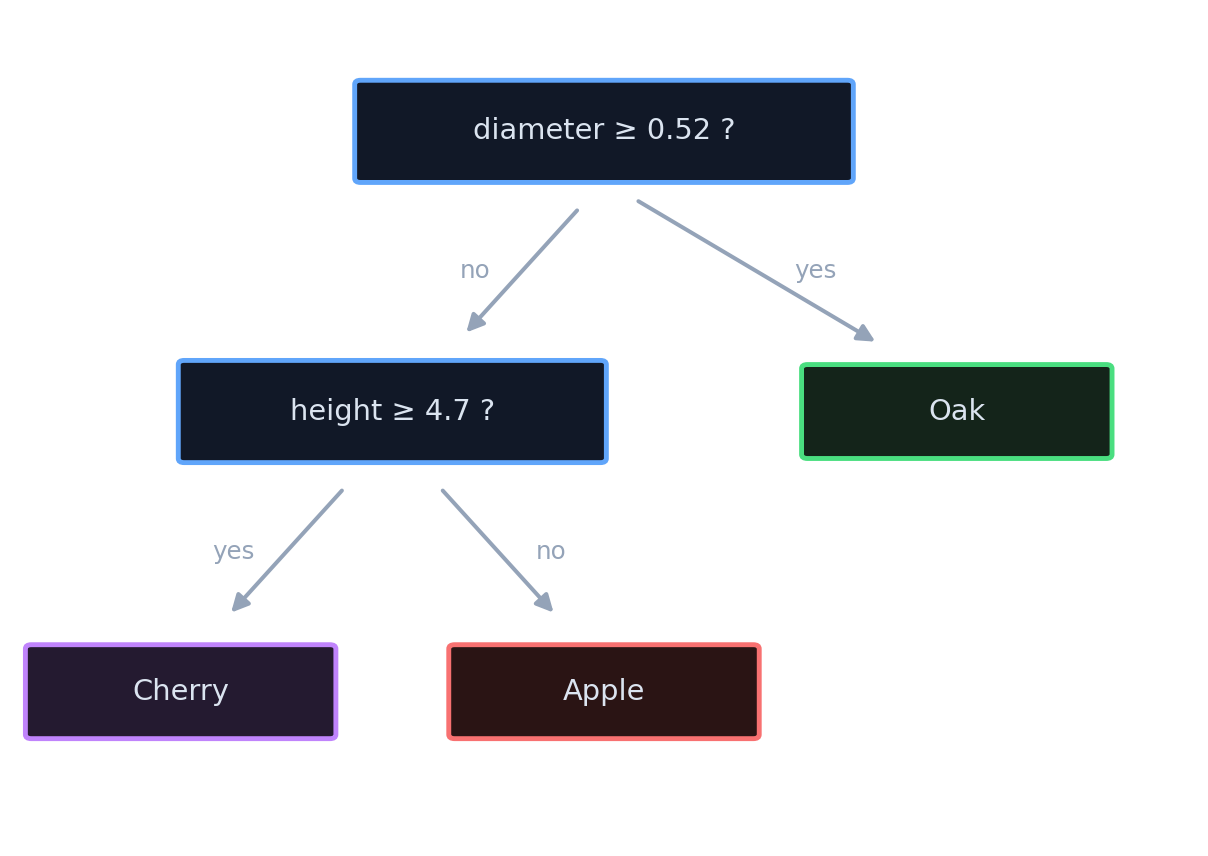
- Boxes on the previous slide ⇔ leaves here. Same model, two pictures.
- Internal node = a yes/no question on one feature.
- Leaf = a prediction (the majority class of the points that reach it).
- To classify a new tree, start at the top and follow the yes/no arrows down to a leaf.
Which question is best? Measure “purity”

A node is pure if it holds one class, impure if it is a mix. Entropy (also Gini) puts a number on it: 0 = pure, larger = more mixed.
- A good question makes the resulting regions more pure than the parent.
- We will measure impurity with entropy \(-\sum_c p_c \log p_c\) or Gini \(\sum_c p_c(1-p_c)\) — formalised in a moment.
Pick the split with the biggest payoff
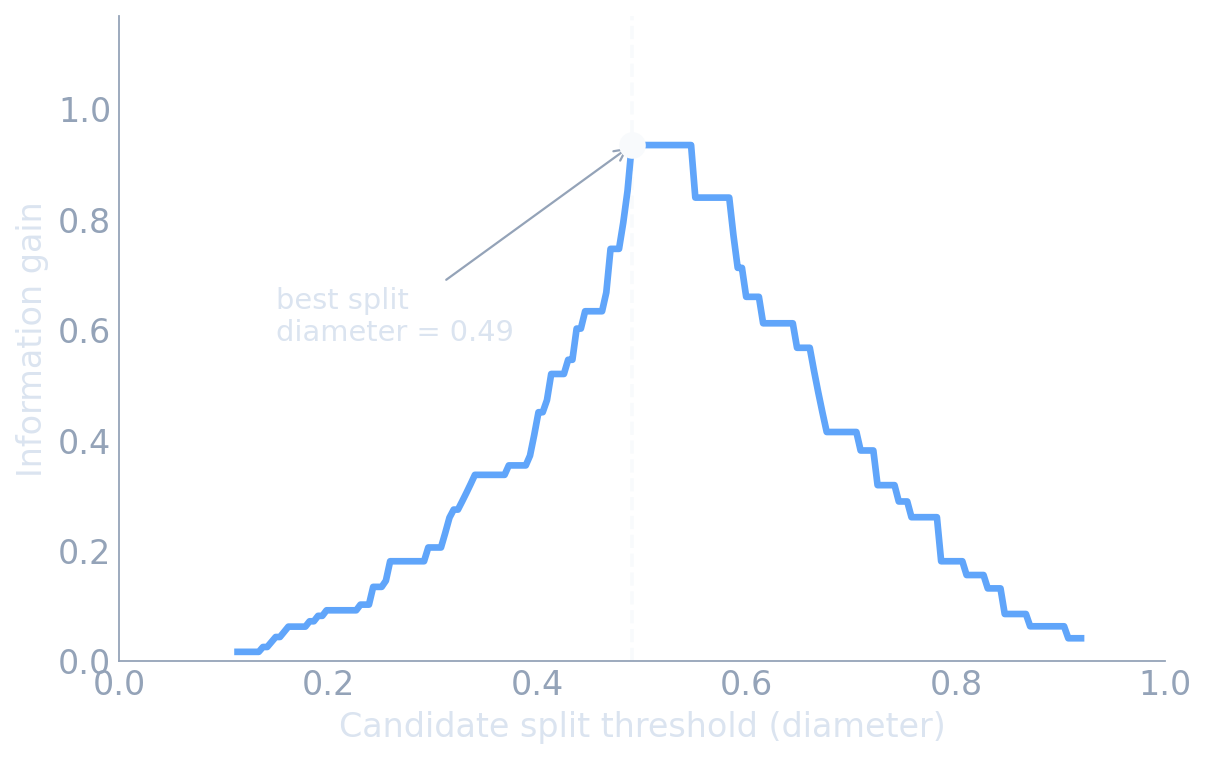
- Try every feature and every threshold; score each by the impurity it removes.
- Keep the single best split, then recurse on each child region.
- Greedy: best question now, no looking back — fast, but not globally optimal.
- The eye-balled “diameter ≈ 0.5” cut is the algorithm’s peak. The intuition was the math.
One tree is powerful — but fragile
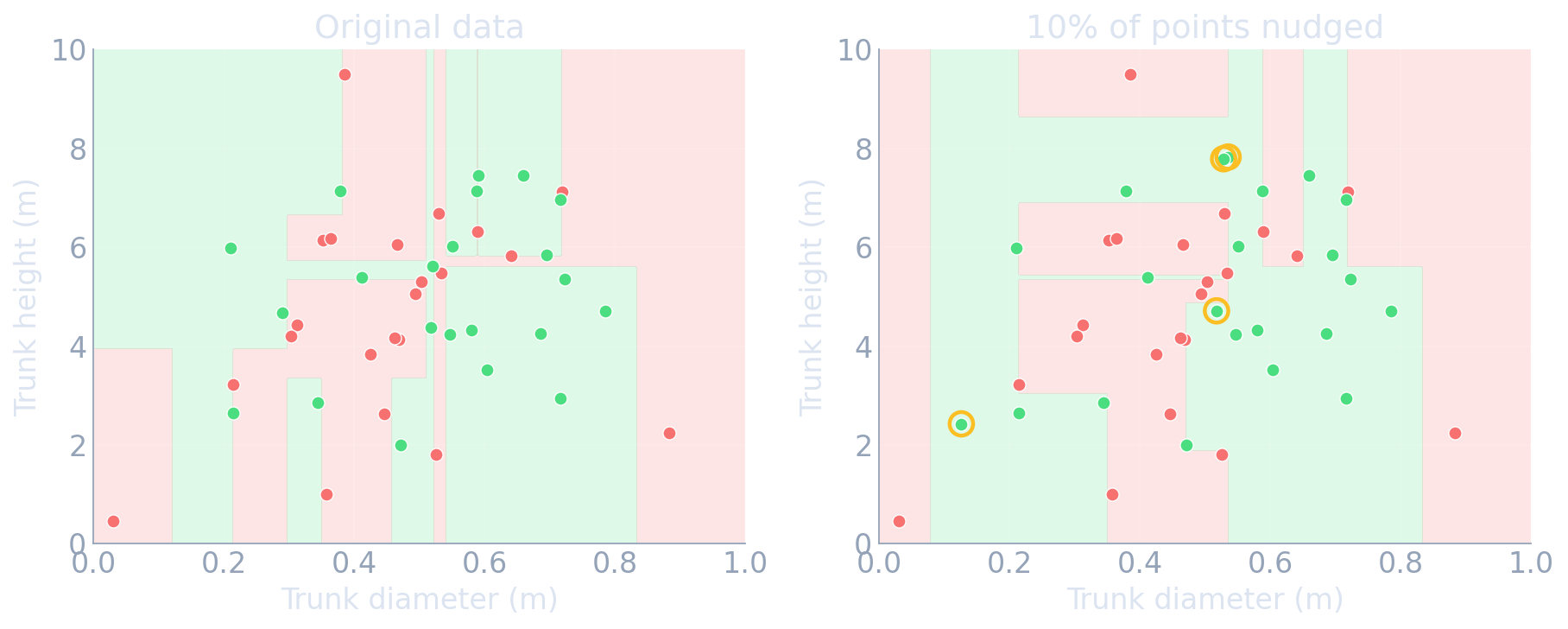
- A single deep tree can fit anything — including the noise (high variance).
- Small data changes → very different tree → the variance arrow on the board.
- The fix, the rest of this unit: average many trees (bagging / forests) and stack corrective trees (boosting).
- Hold onto this picture — it is why ensembles exist.
Impurity measures: variance, Gini, entropy
Regression
- \(I_{\text{var}} = \frac{1}{N}\sum_i (y_i - \bar y)^2\).
- Maximizing variance reduction = minimizing within-leaf SSE = fitting leaf means by least squares.
Classification
- Gini: \(\sum_c p_c(1-p_c)\) — expected misclassification rate of random labeling.
- Entropy: \(-\sum_c p_c\log p_c\) — information content.
- Both are maximized at uniform \(p_c\), zero at a pure node.
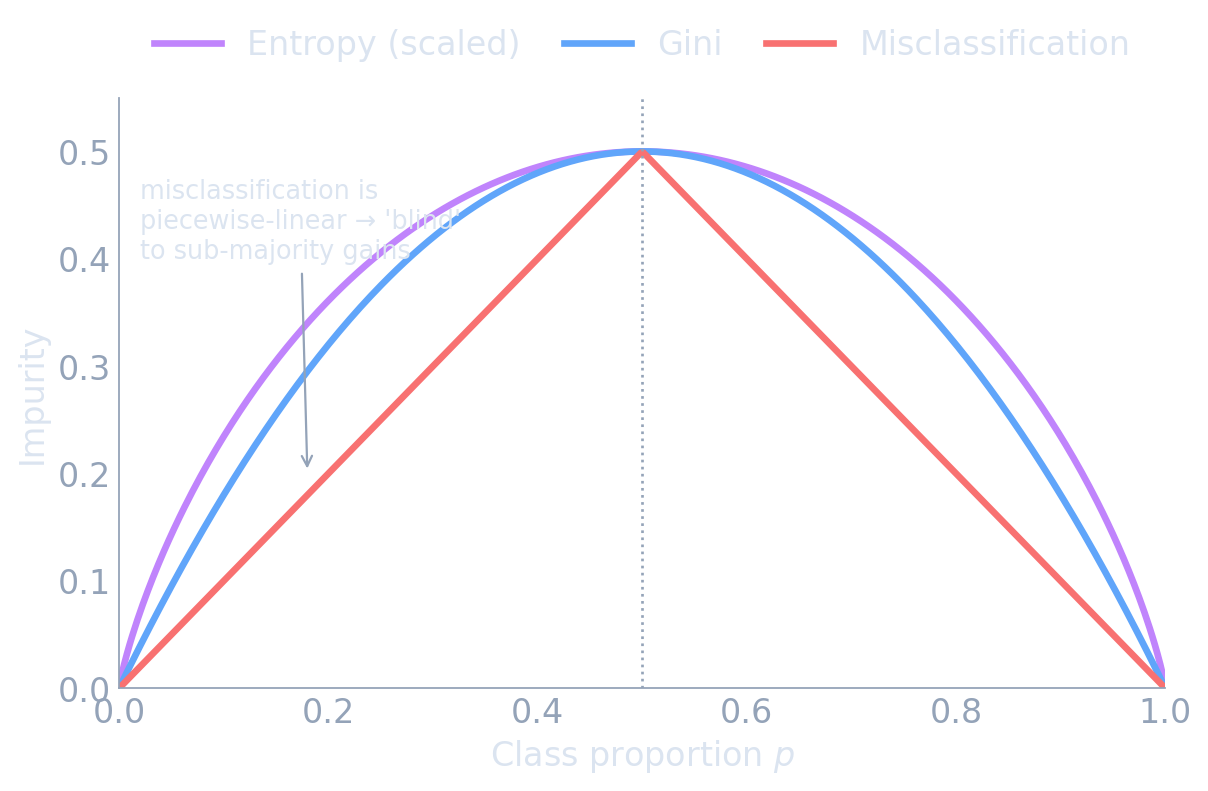
All three peak at \(p=0.5\) and vanish at pure nodes — but misclassification error is piecewise-linear, so it cannot reward a split that purifies a child without flipping its majority. Gini/entropy are strictly concave and can.
- Gini and entropy give very similar trees in practice; Gini is slightly cheaper (no log) and is the scikit-learn default.
- Misclassification error is not used for growing — it is insensitive to changes that don’t flip the majority class.
See it: averaging smooths the boundary
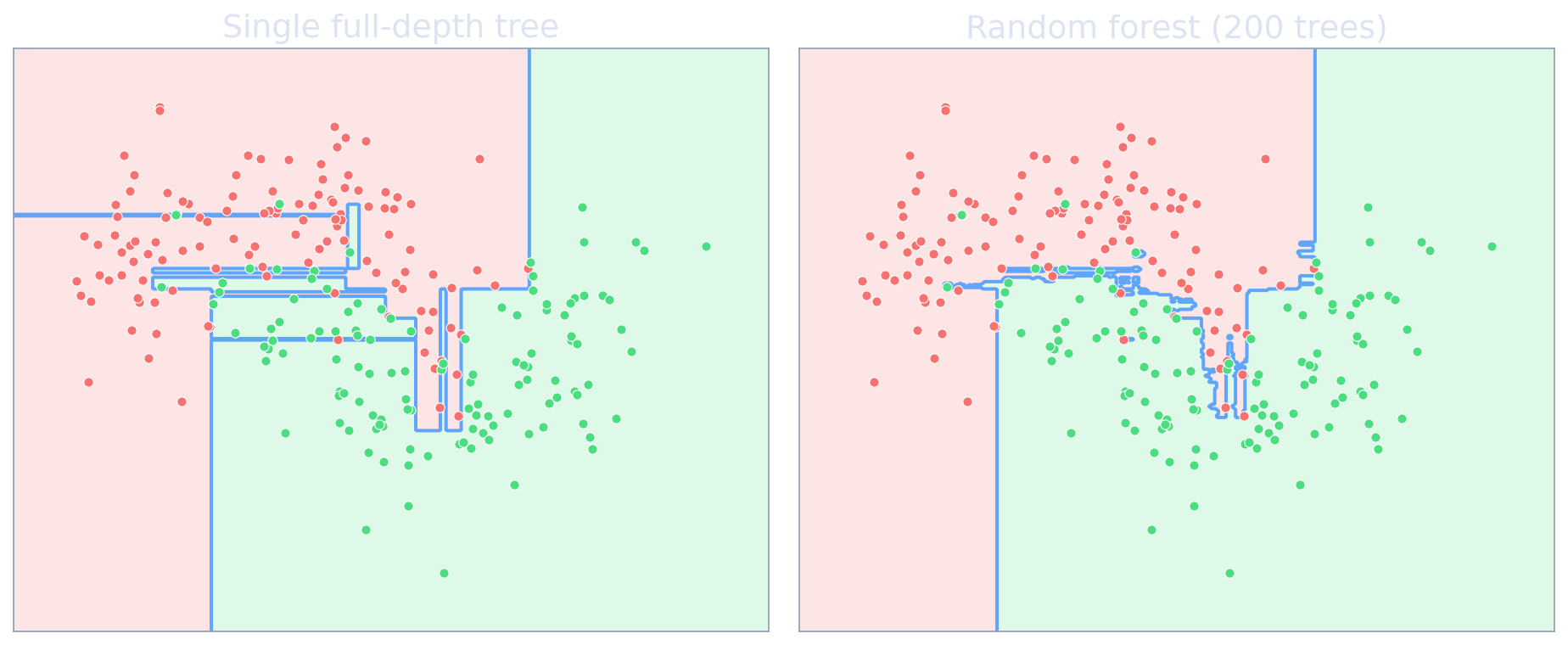
- Left = high variance: every noisy point gets its own box.
- Right = the same trees, averaged → the staircase washes out.
- The decision boundary barely moves if you resample the data — exactly the variance reduction the \(\rho\sigma^2\) formula promised.
- Bias is untouched; only the jitter is gone.
Example: impurity importance is fooled by noise

- Left (MDI): the random descriptor ranks alongside real Mo fraction — a red flag you would never catch from the bar chart alone.
- Right (permutation): the noise and the genuinely-useless Mo both drop to ≈ 0.
- Both panels agree the real driver is Phase, then anneal temp, then C.
- Lesson: never publish raw MDI as evidence that a feature “matters.”
See it: the ensemble builds up tree by tree
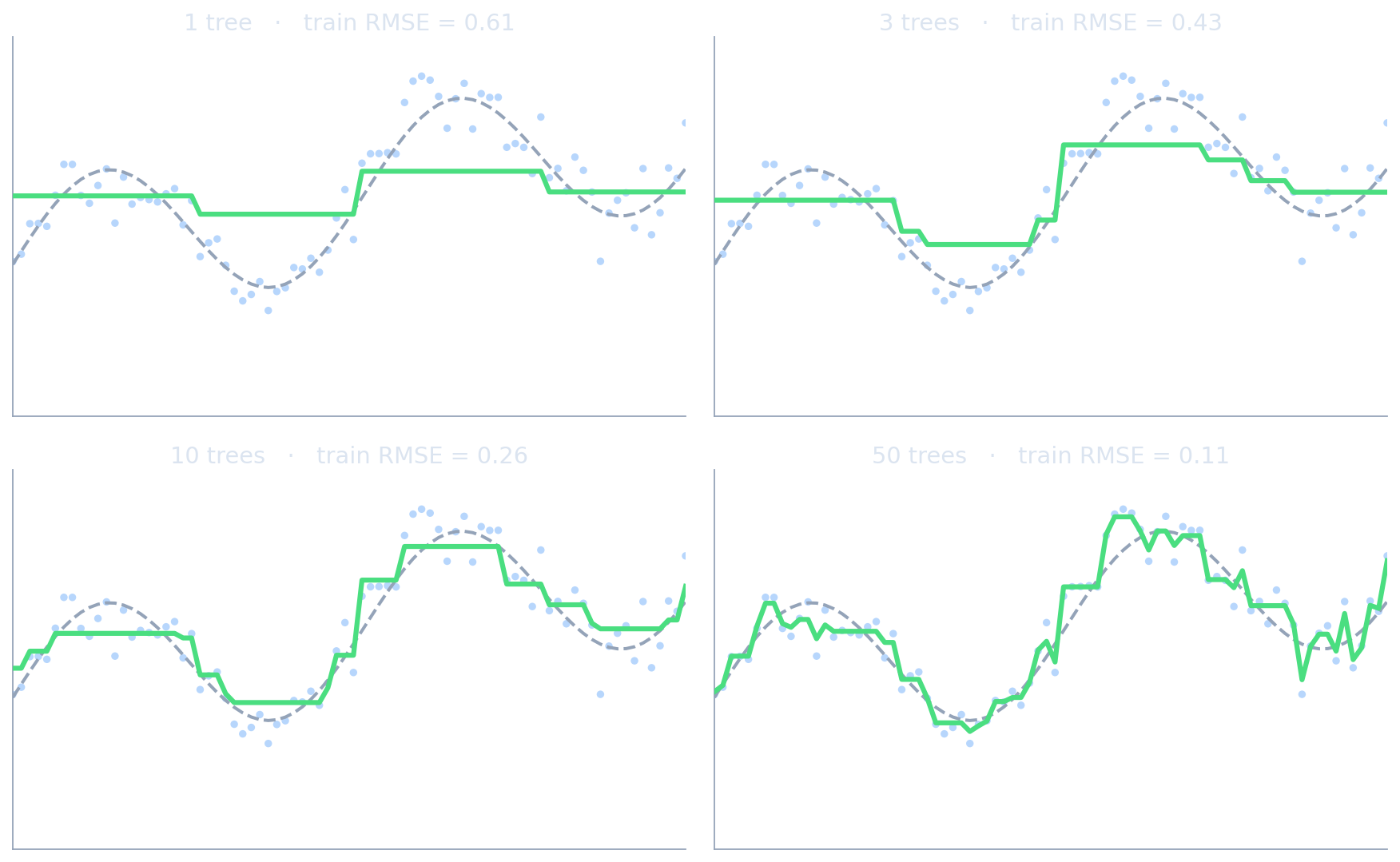
- 1 tree: one step — pure bias, just like a stump.
- 3–10 trees: the shape emerges as each tree fits the leftover residual.
- 50 trees: near-perfect on train — and beginning to wiggle on noise (variance creeping in).
- Bias falls monotonically; early stopping decides when to quit.
See it: why rotation matters
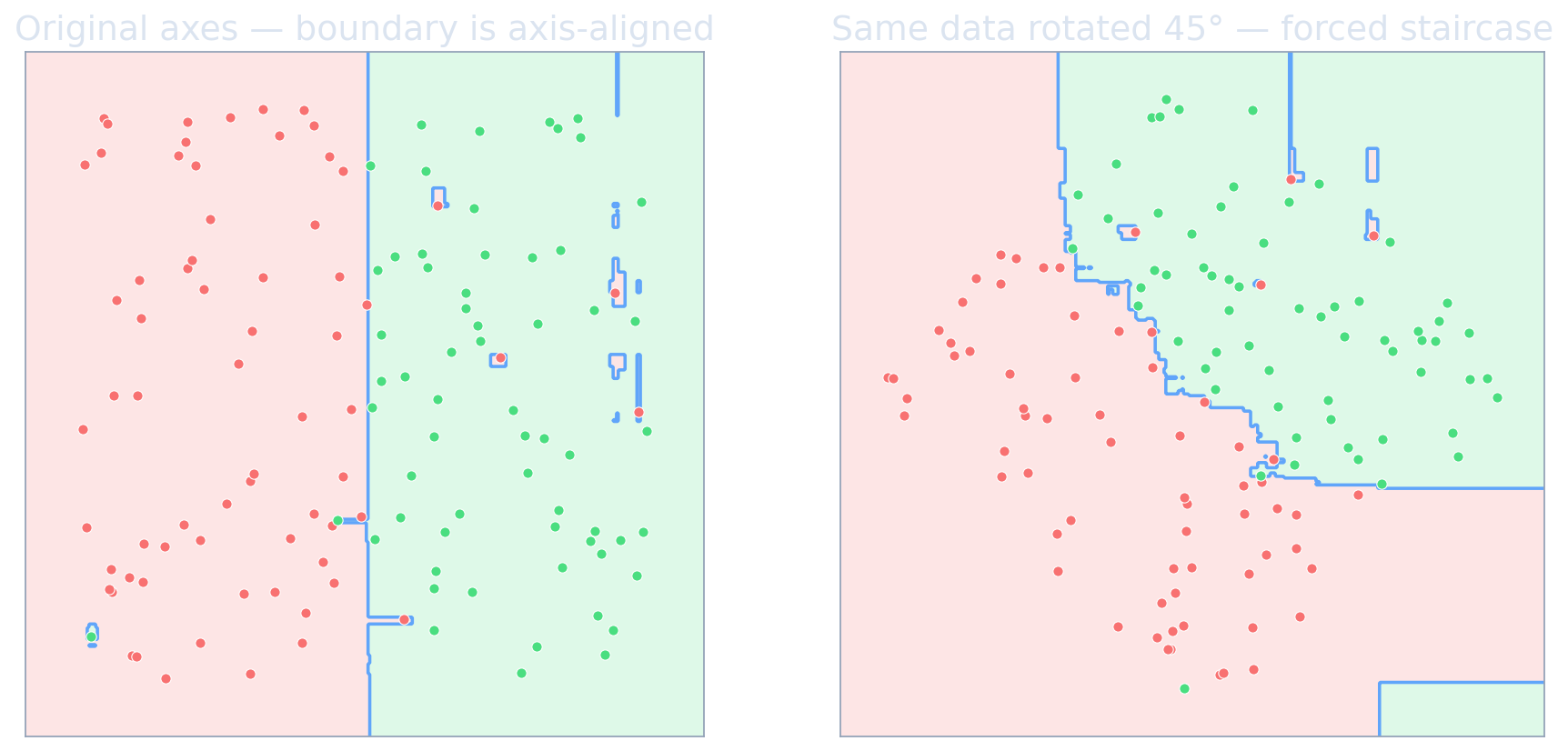
- Each column here is a physical quantity (at% Cr, anneal °C) — the informative cuts are axis-aligned.
- Trees exploit that for free; a rotation destroys it.
- A neural net is rotation-invariant — great for pixels, a liability when axes are meaningful.
- This is why “rotation non-invariance is a feature” for tabular data.
Materials example — alloy property prediction
- Dataset: 5000 alloys, 12 elemental fractions + 4 processing parameters → predict yield strength.
- Linear regression (quadratic features): \(R^2 = 0.62\) on held-out alloys.
- Random Forest (500 trees, \(\sqrt d\) features/split): \(R^2 = 0.84\).
- XGBoost (\(300\) trees, \(\eta=0.05\), depth 6): \(R^2 = 0.88\).
- Top SHAP features: Cr fraction, anneal temperature, C fraction, Mo fraction.
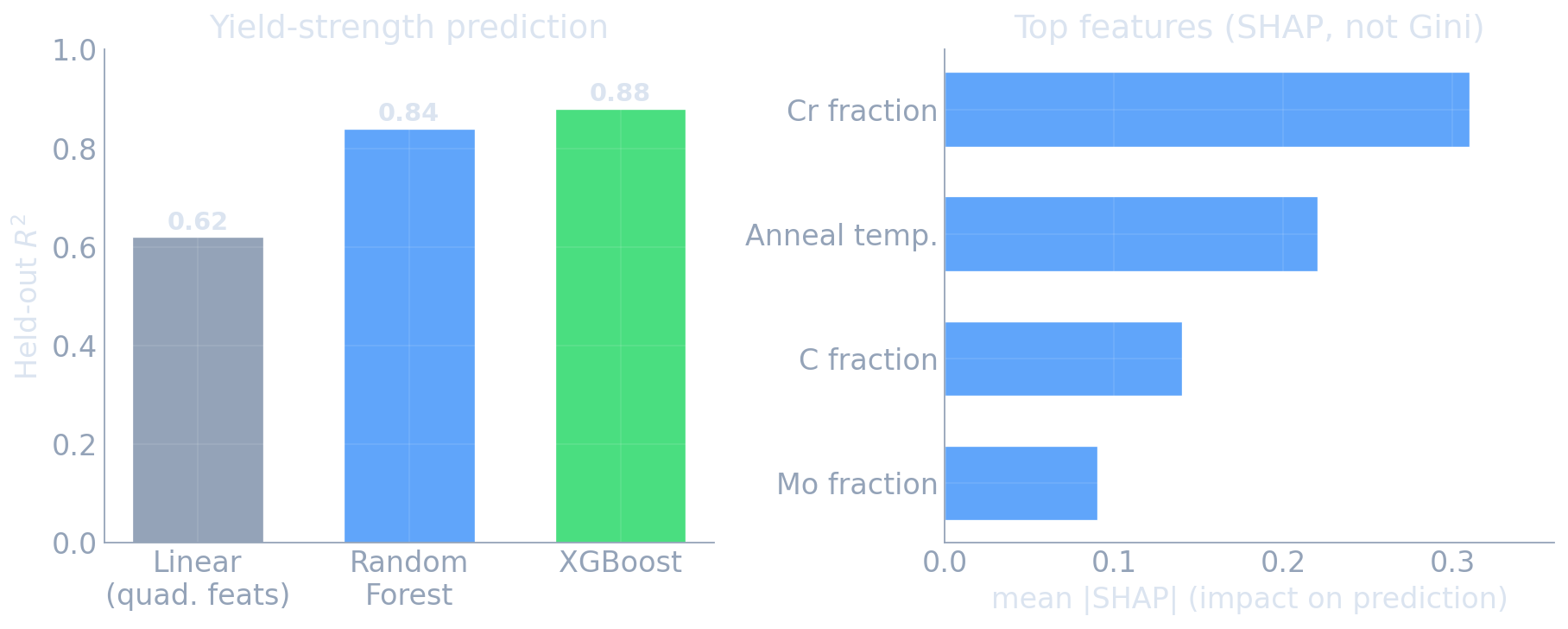
Typical pattern: tree ensembles add 10–20 points of \(R^2\) over linear models at essentially no engineering cost.
Example Notebook
Companion notebook: overfitting, bias–variance & CV (Ising model)