Mathematical Foundations of AI & ML
Unit 14: Explainability, Limits, and Trust




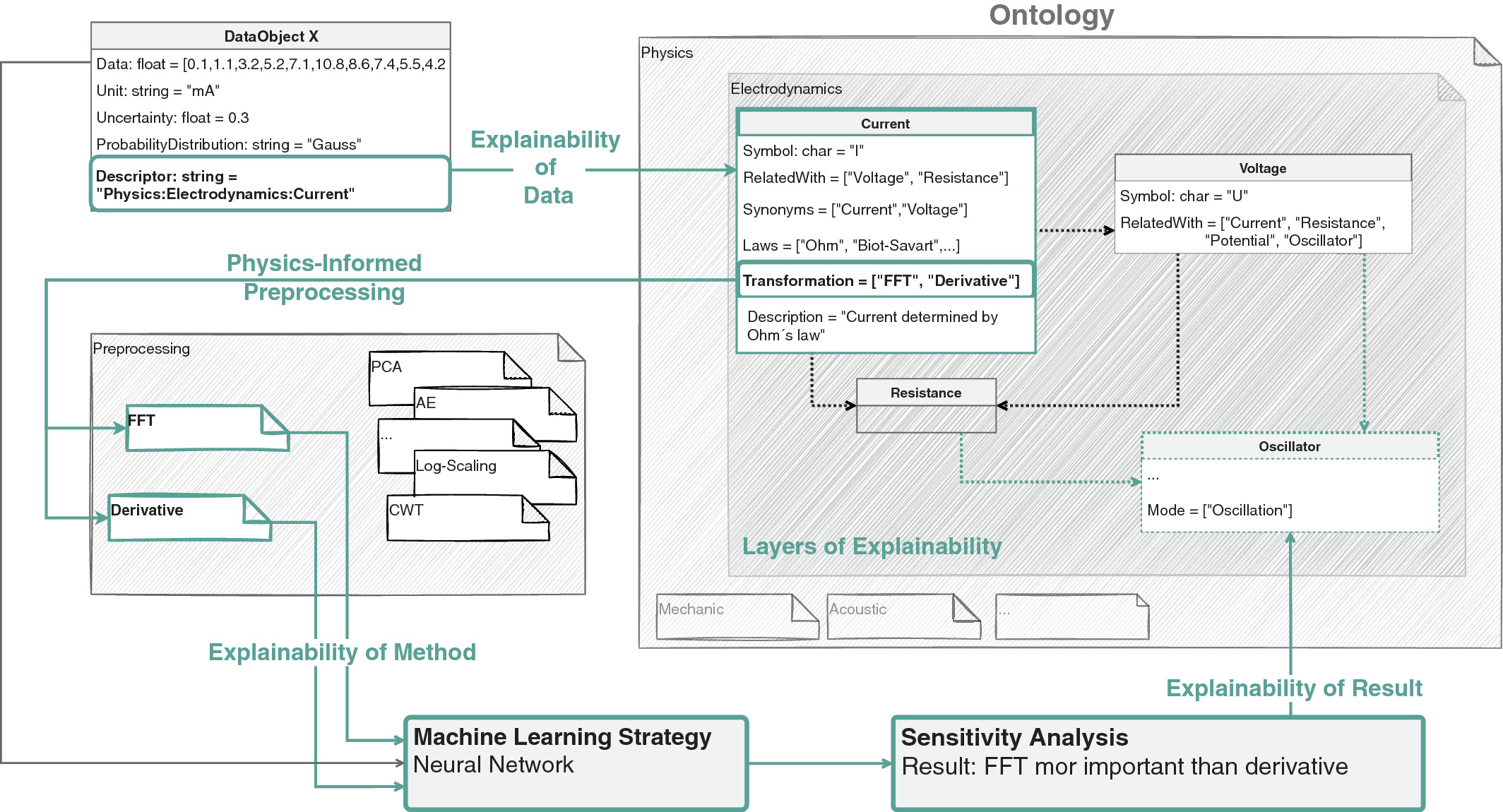
Explainability vs interpretability
Interpretability
- The model itself is transparent and understandable.
- Examples: linear regression, decision trees, small rule sets.
Explainability
- Post-hoc methods that reveal the reasoning of complex models.
- Examples: SHAP values, sensitivity analysis, attention visualization.
- Trade-off: interpretable models may be less accurate; explainability adds complexity to accurate models.
Synonyms and controlled vocabularies
- Different terms for the same concept: “yield strength” = “elastic limit” = “\(R_e\)”.
- Controlled vocabulary: a standardized list of terms with defined meanings.
- Without synonym resolution, models may treat the same property as two separate features.
- First step in any data integration pipeline.

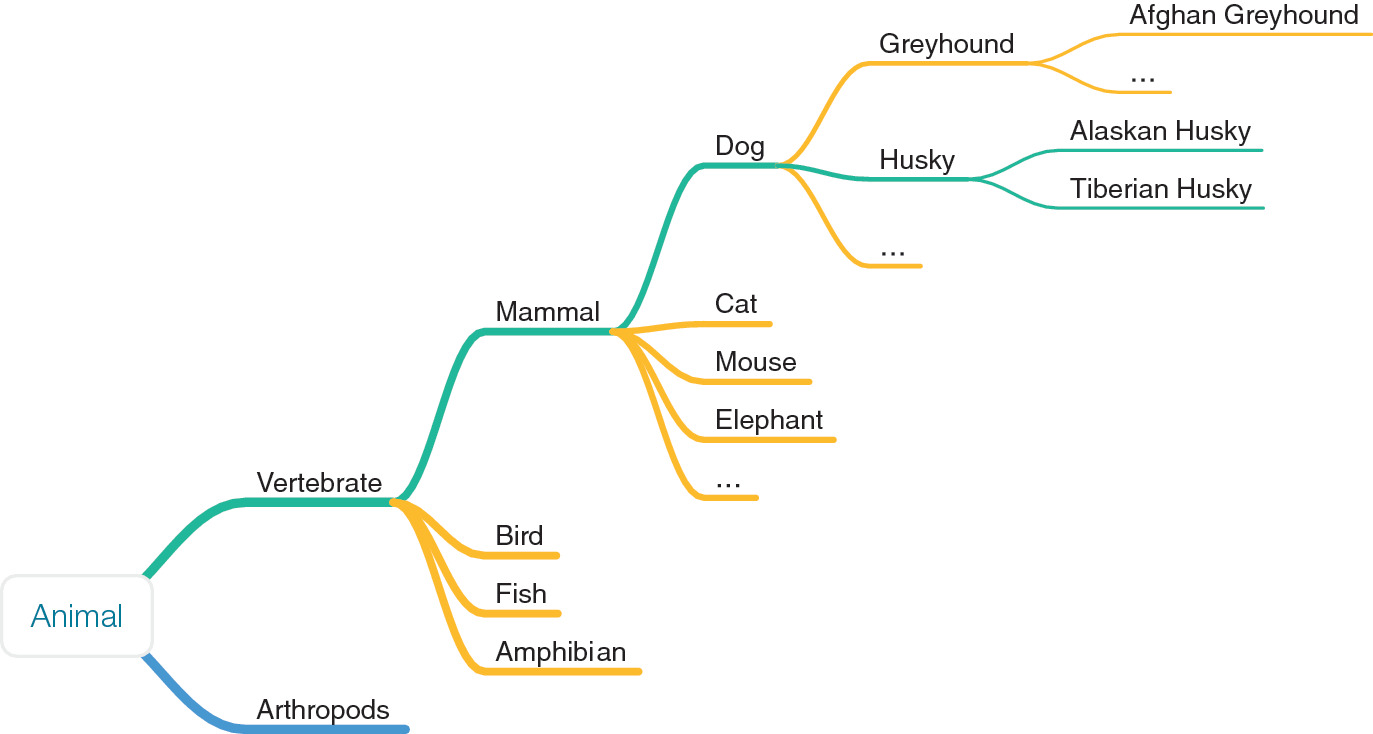
Taxonomies: hierarchical classification
- Organize concepts in parent-child hierarchies:
- Material > Metal > Steel > Stainless Steel > 316L.
- Taxonomies enable inheritance: properties of “Metal” apply to all sub-categories.
- They structure domain knowledge and guide feature selection.
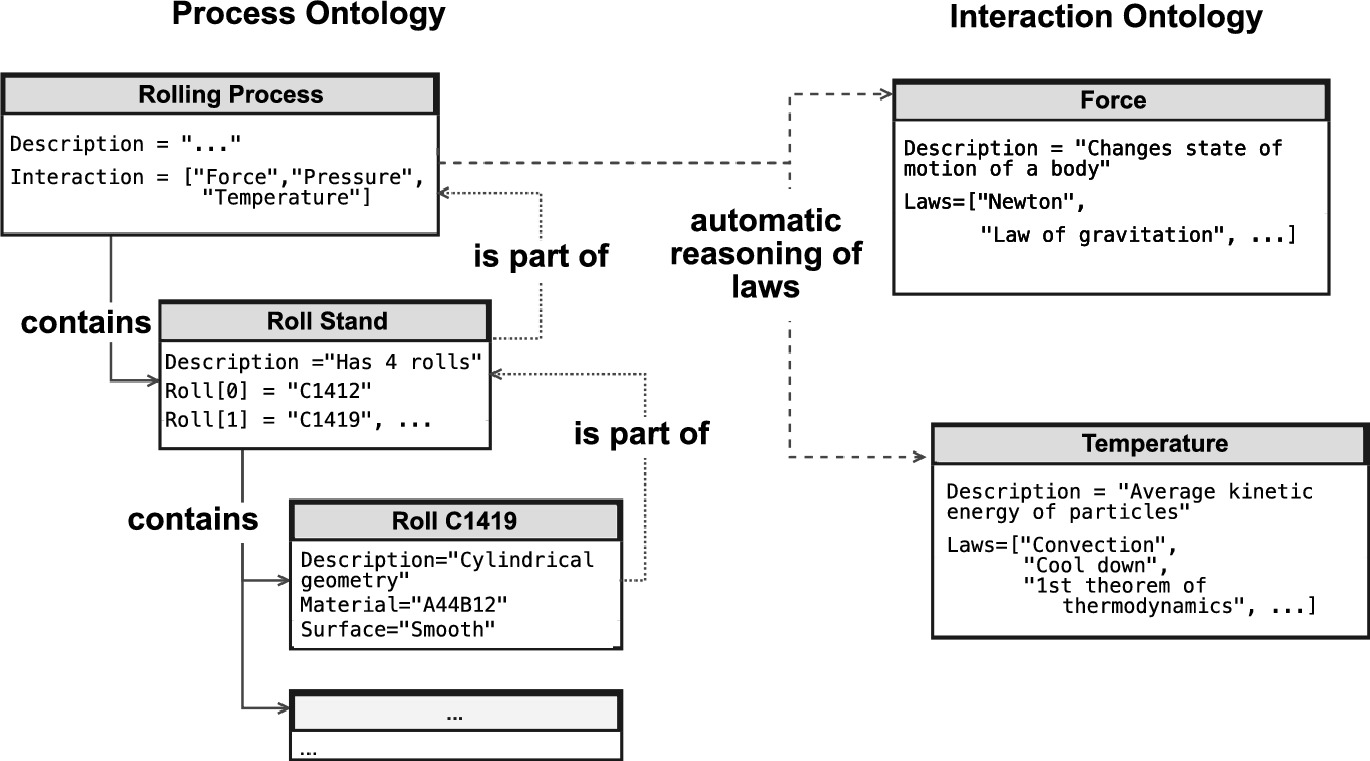
Ontologies for feature engineering
- Ontological relationships encode domain knowledge about what matters:
- “Composition determines phase” → include composition features.
- “Processing affects microstructure” → include processing parameters.
- This connects to Unit 13 (physics-informed learning): ontologies formalize the physics knowledge.
The six levels of explainability (E1–E6)
- A structured framework for matching explanation depth to audience and purpose.
- Each level addresses a different question about the model and its predictions.
- Comprehensive explainability requires addressing all six levels.
- Not every audience needs every level — match the explanation to the recipient (Neuer et al. 2024).
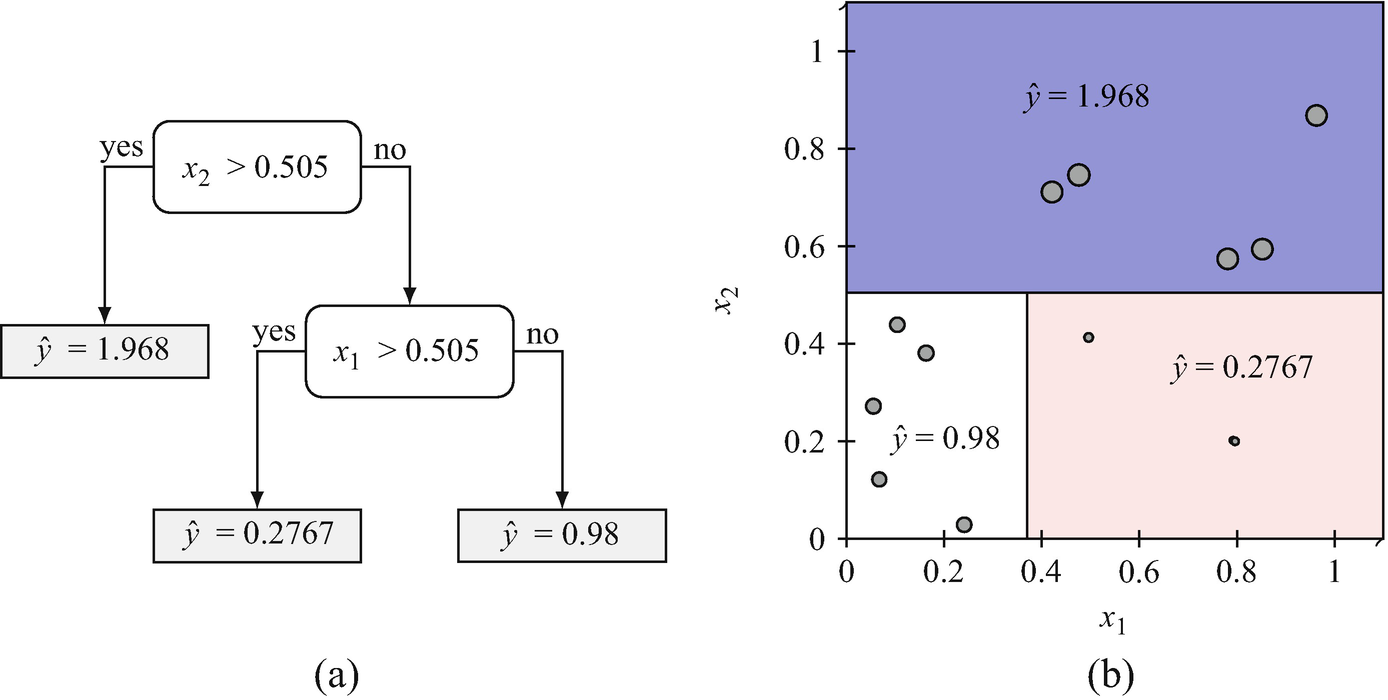
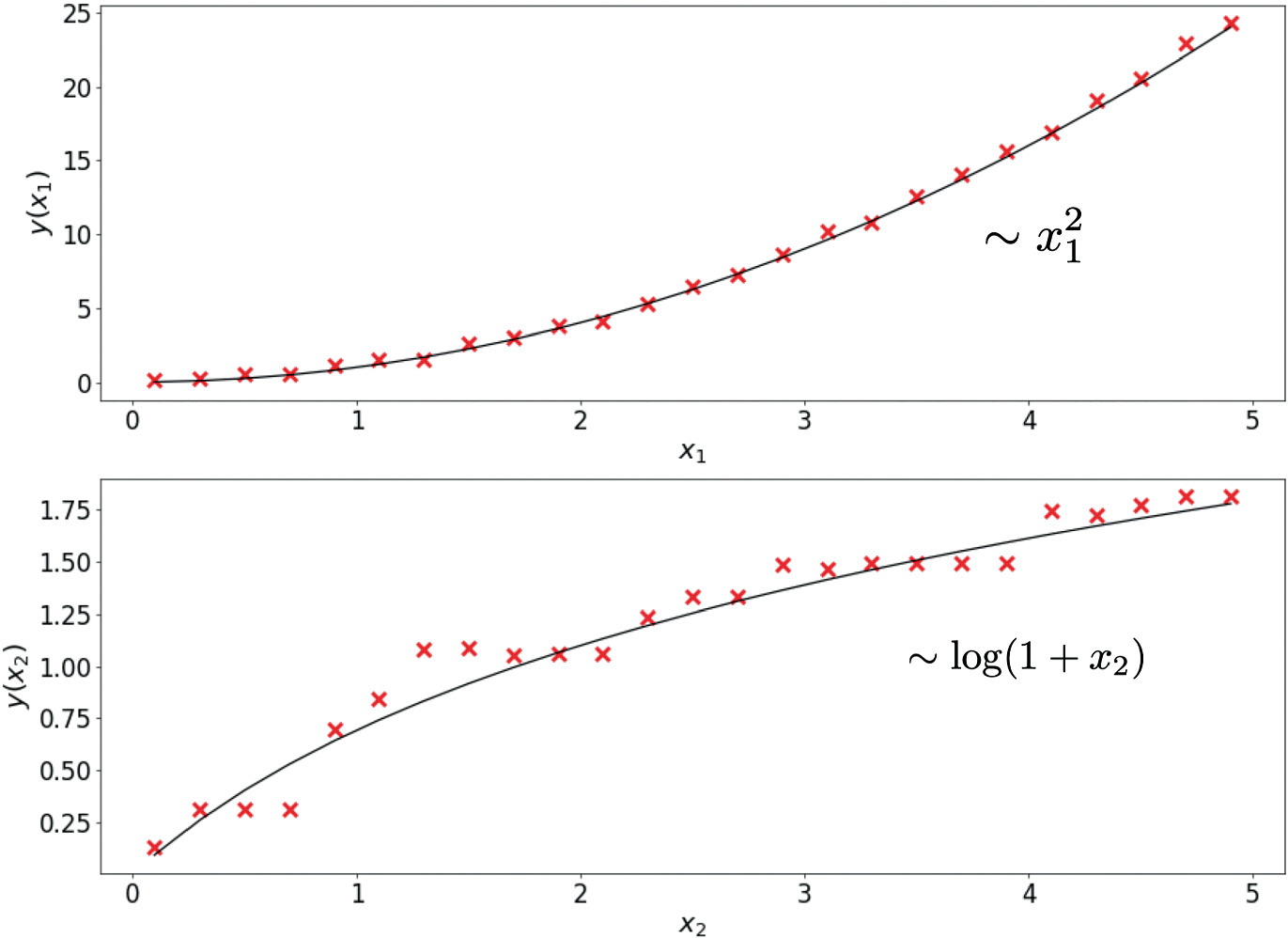
Sensitivity analysis in practice
- Vary each feature by \(%\) (or \(\)) while holding others constant.
- Record the output change for each perturbation.
- Rank features by average output sensitivity.
- Visualize as a bar chart: “tornado plot” showing feature sensitivities.
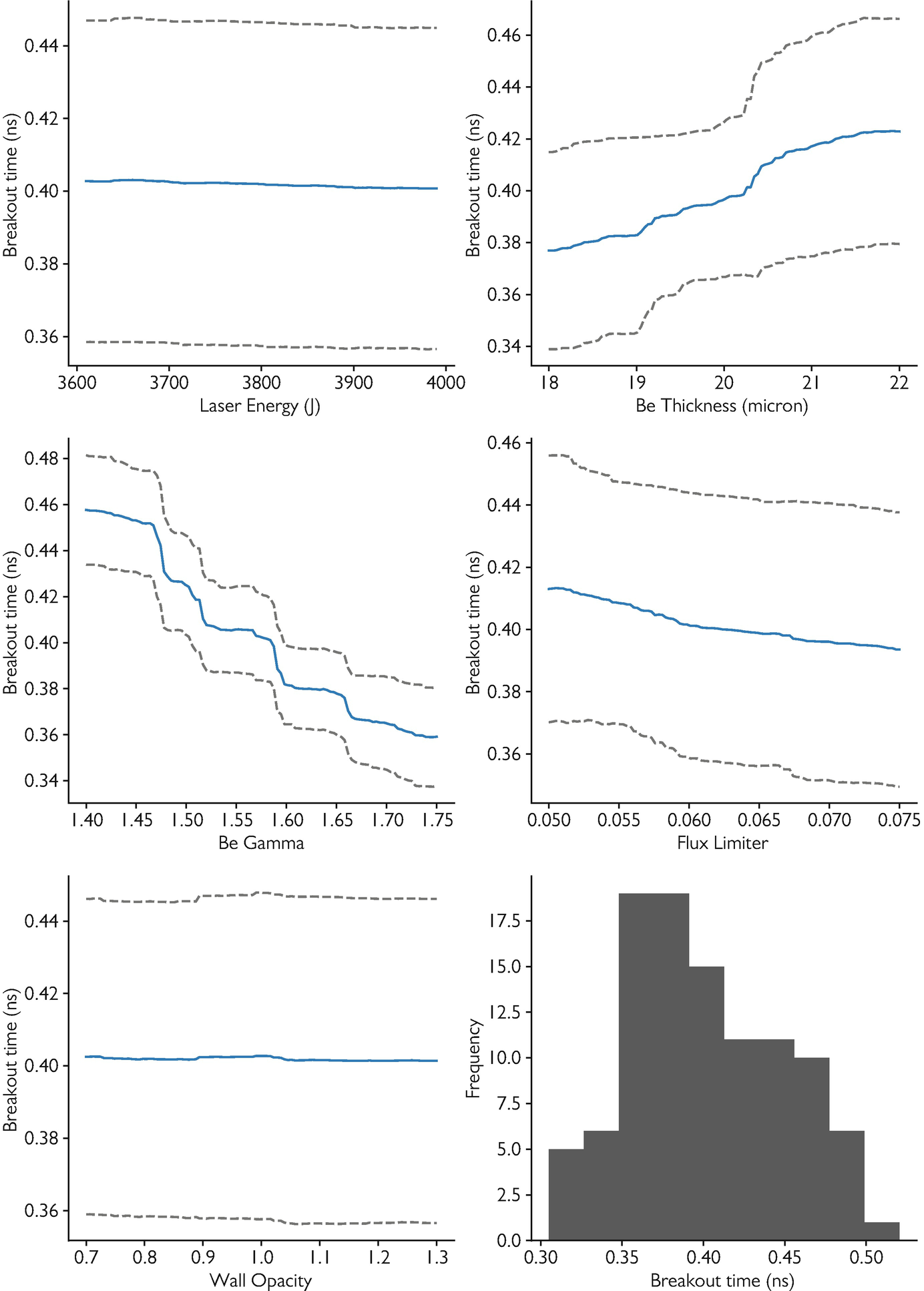
Feature importance from sensitivity
- High sensitivity \(\) important feature — changes in it strongly affect predictions.
- Low sensitivity \(\) unimportant feature — can potentially be removed.
- But: sensitivity alone does not imply causation — it reveals association.
- Combine with domain knowledge to interpret importance.
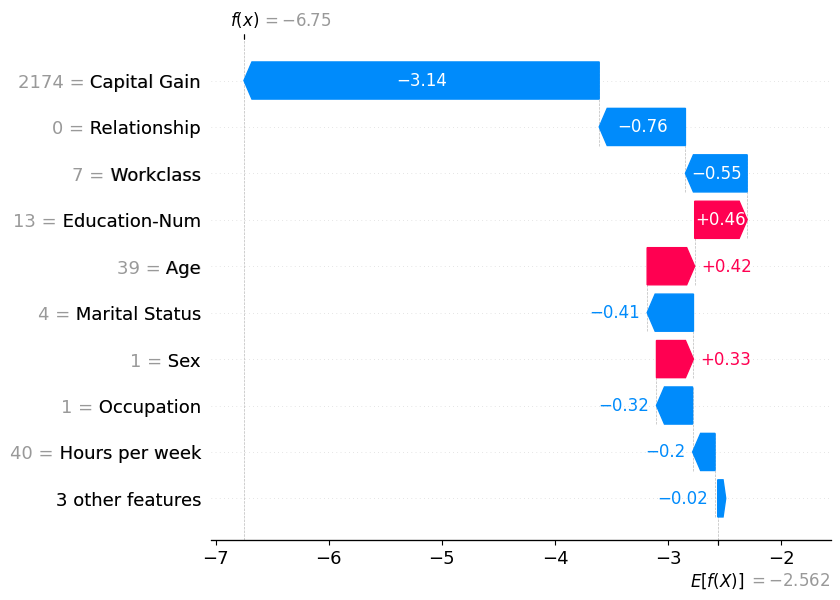
SHAP waterfall plot — explaining one prediction
- A waterfall plot decomposes a single prediction into per-feature contributions.
- Starting from the expected model output \(\mathbb{E}[f(x)]\), each bar adds or subtracts the SHAP value of one feature.
- Red bars push the prediction higher; blue bars push it lower.
- The final value at the top is the model output for that instance (Lundberg and Lee 2017).
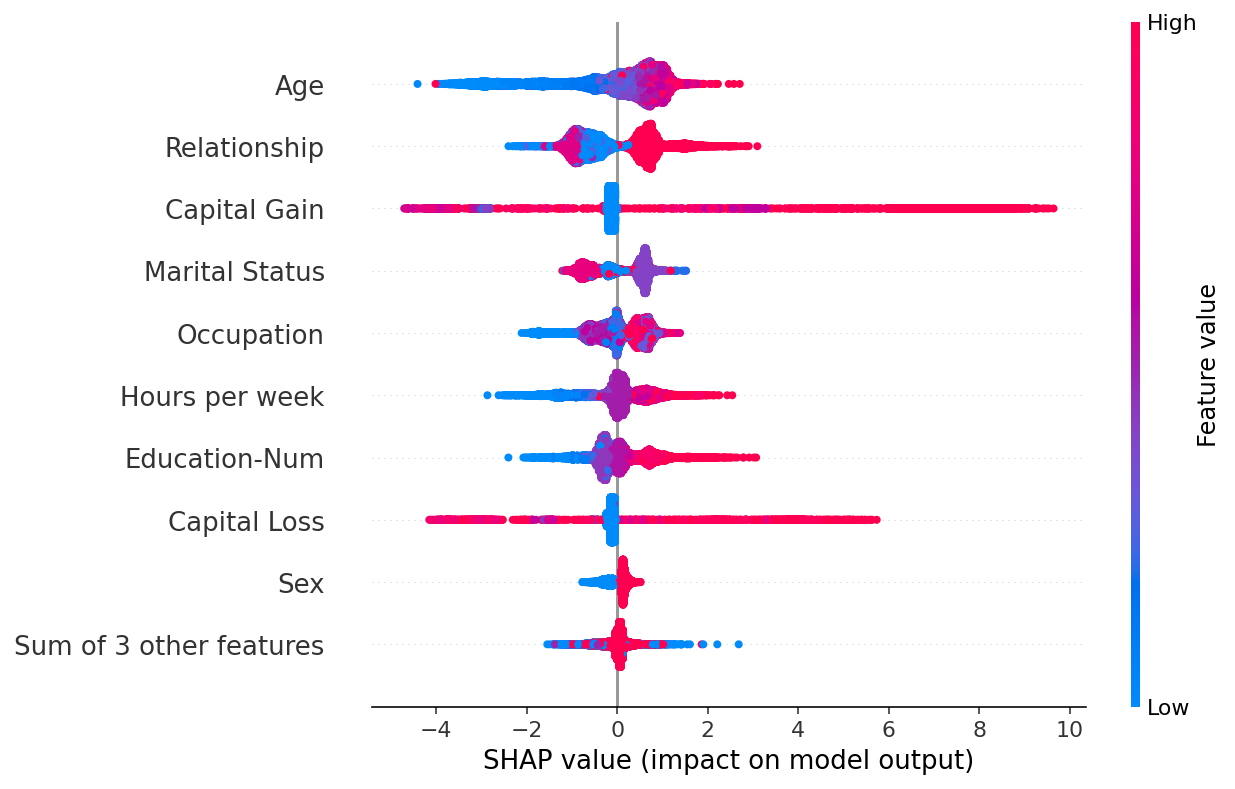
SHAP beeswarm plot — global feature importance
- A beeswarm plot summarises SHAP values across the entire dataset.
- Each dot is one data point; the x-axis shows the SHAP value (impact on prediction).
- Colour encodes the feature value (red = high, blue = low).
- Features are ranked by mean |SHAP|, giving a global importance ranking with local detail (Lundberg and Lee 2017).
Integrated Gradients: attributing deep network predictions
- Integrated Gradients (Sundararajan et al. 2017): attributes a prediction to each input pixel by integrating gradients along a straight path from a baseline (black image) to the input.
- Satisfies two key axioms: Sensitivity (if input and baseline differ only in one feature, it receives non-zero attribution) and Implementation Invariance (functionally identical networks get the same attribution) (Sundararajan et al. 2017).
- Visualised as pixel-level heatmaps: positive attributions highlight features supporting the predicted class.

Causal process chains
- In manufacturing: Composition \(\to\) Processing \(\to\) Microstructure \(\to\) Properties.
- The arrow direction encodes causation: changing composition causes different microstructure.
- ML can model these links, but the causal direction is known from physics, not learned from data (Neuer et al. 2024).

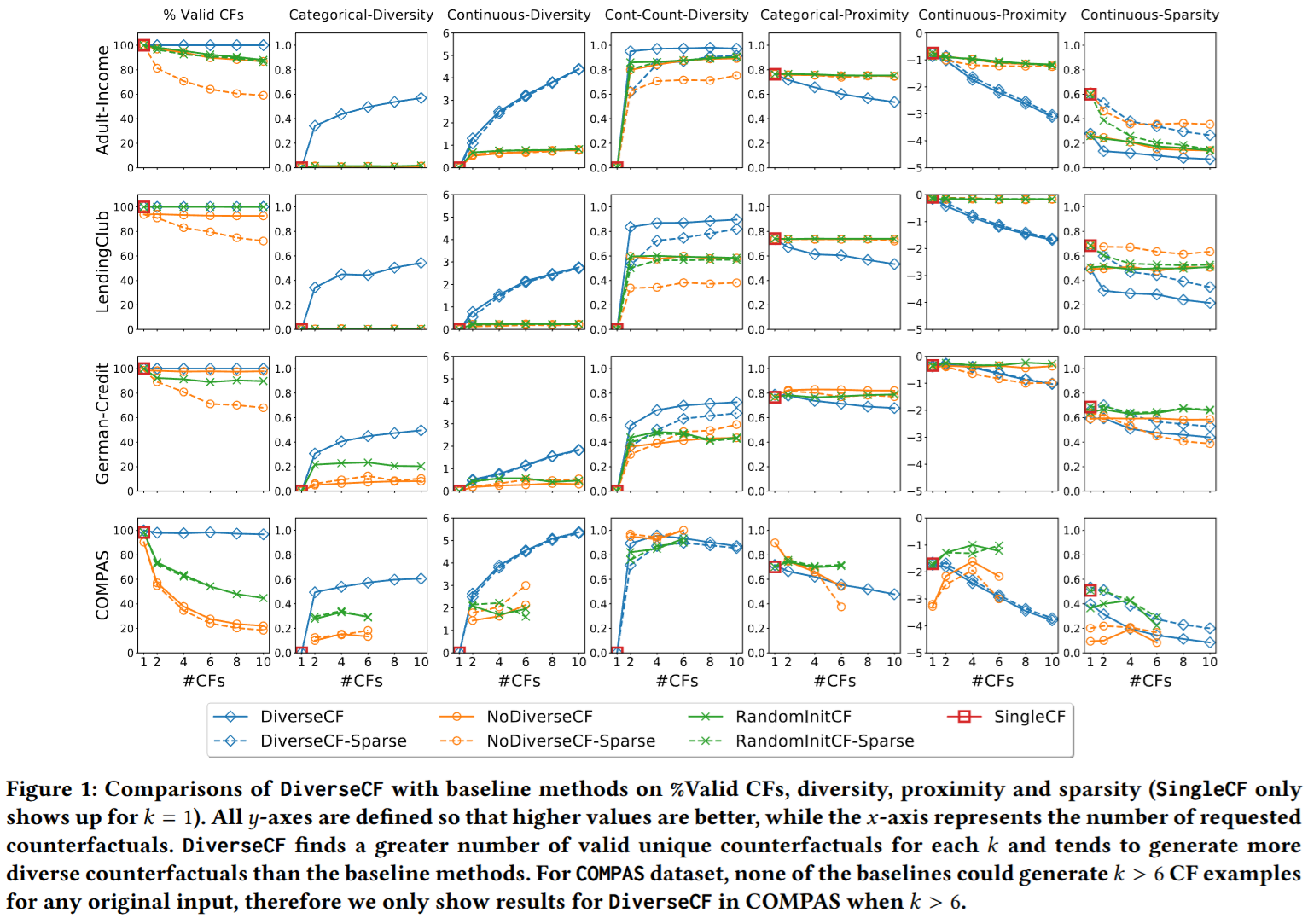
Counterfactual explanations: “what if?”
- A counterfactual explanation answers: “what is the smallest change to the input that would flip the prediction?”
- Example: “Your loan was denied. If your income were €5 000 higher and your debt €2 000 lower, it would be approved.”
- Counterfactuals are actionable: they tell users what to change, not just what mattered.
- DiCE (Mothilal et al. 2020) generates diverse counterfactuals so users see a range of valid alternatives (Mothilal et al. 2020).
Fairness and bias in ML predictions
- ML models can perpetuate or amplify societal biases present in training data.
- Equalized odds (Hardt et al. 2016): a predictor is fair if it has equal true-positive and false-positive rates across protected groups (e.g. race, gender).
- Equal opportunity: the weaker condition of equal true-positive rates only.
- Figure 1 shows the ROC polytope of achievable (FPR, TPR) pairs per group — fairness requires operating at the same point on both group-specific ROC curves (Hardt et al. 2016).
Building trustworthy ML systems
- Uncertainty quantification (Unit 12): know what you don’t know.
- Explainability (Unit 14): understand why predictions are made.
- Domain validation: check predictions against physical knowledge.
- Human oversight: experts review critical predictions.
- Trustworthy ML = the combination of all four.