Machine Learning in Materials Processing & Characterization
Unit 7: Generalization, Robustness, and Process Windows




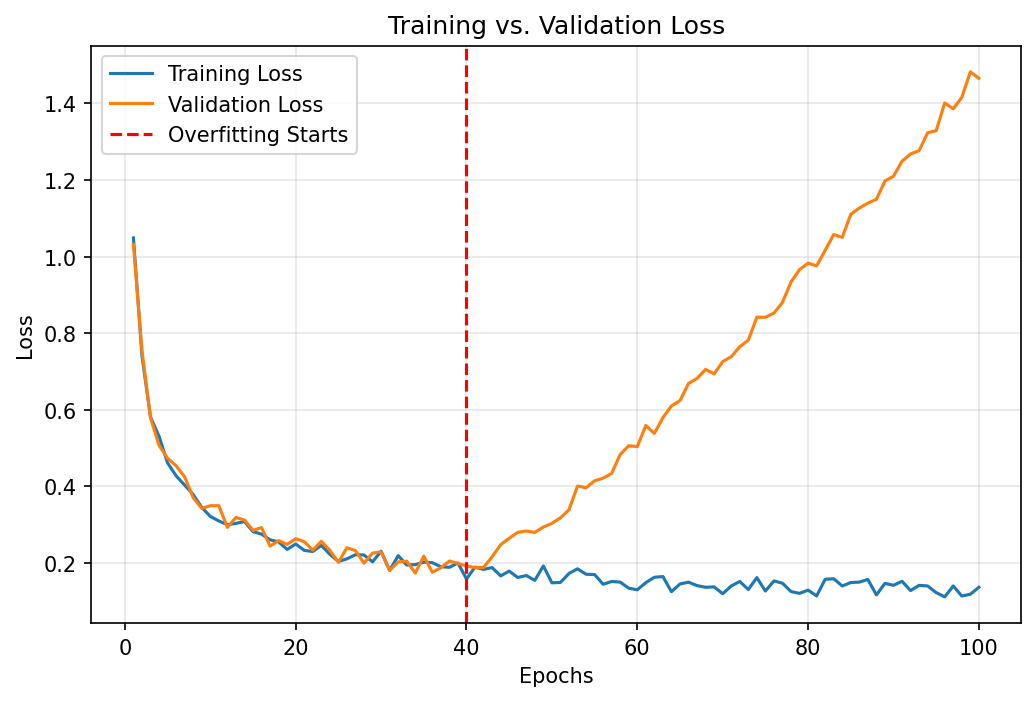
05. Training vs. Testing Error
- Training error measures fitting — how well the parameters minimize \(L\) on the data they were optimized against.
- Testing error measures generalization — how well the model performs on data the optimizer never touched.
- The gap \(L_{\text{test}} - L_{\text{train}}\) is the generalization gap.
Engineering reading Sandfeld, Stefan et al., (2024):
- Both errors decreasing → underfitting; add capacity.
- Train error \(\downarrow\), test error \(\uparrow\) → overfitting; regularize, get more data, or simplify.
- Both errors plateau at the same high value → noise floor / data is not informative.
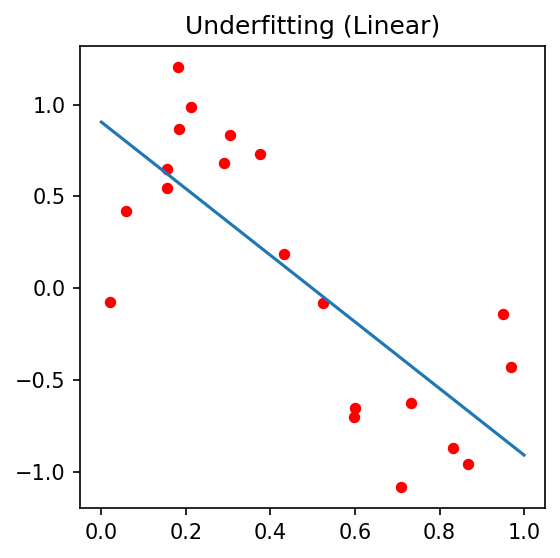
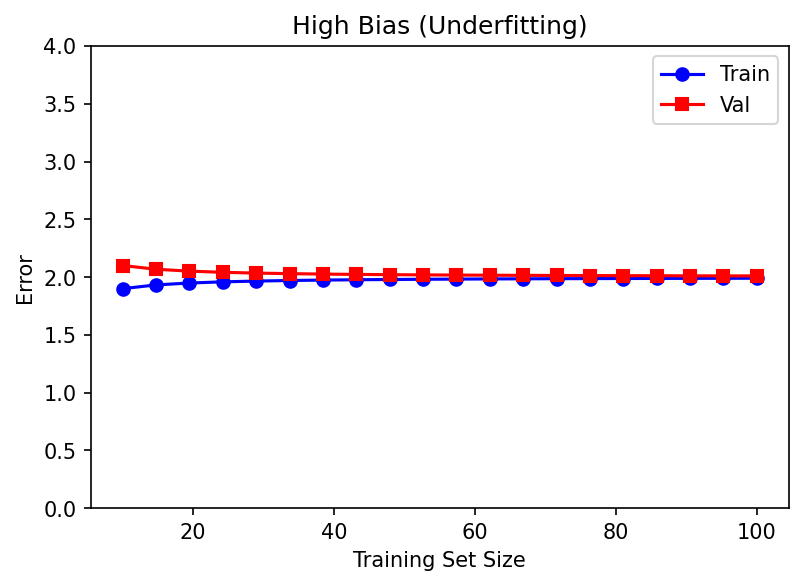
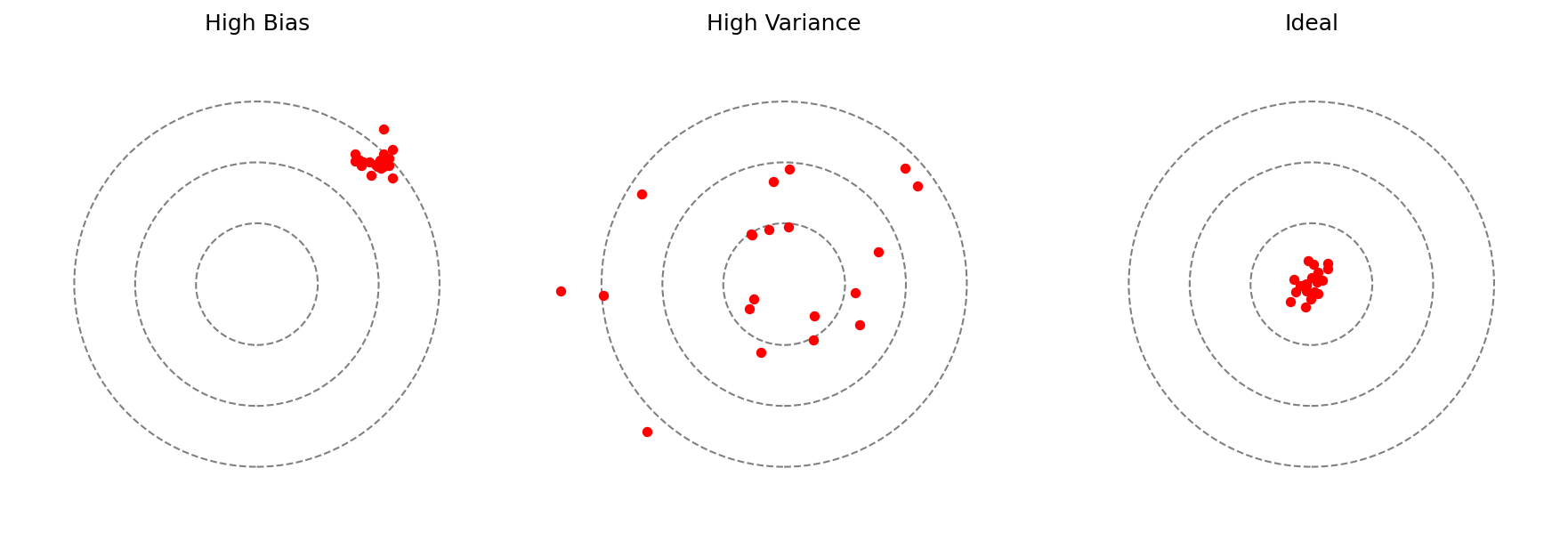
06. Underfitting — High Bias
A model with insufficient capacity to capture the underlying structure.
- Linear fit to a quadratic relationship.
- Constant predictor for a structured field.
- Both train and test error are high and similar.
Symptoms on the curve: both losses plateau early at a high value; the gap is small.
Materials examples:
- Predicting yield strength from composition alone, ignoring grain size.
- Linear regression on a nonlinear \(\sigma\)–\(\dot\varepsilon\)–\(T\) surface.
- Tiny CNN (\(<10^4\) params) on 4D-STEM patterns.
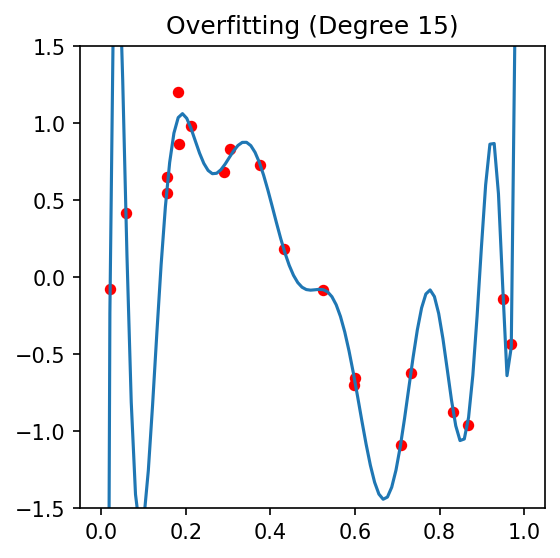
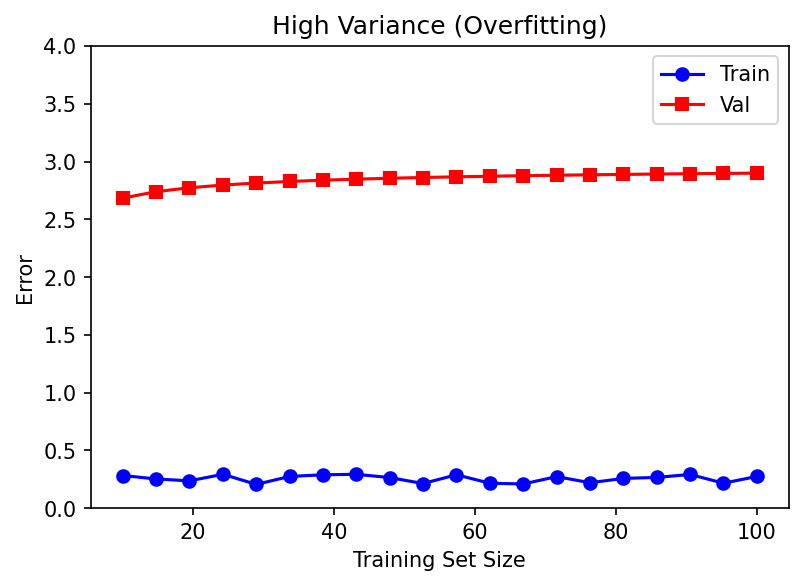
07. Overfitting — High Variance
A model with excess capacity that memorizes training noise.
- 10th-degree polynomial through 5 points.
- Decision tree grown to leaf-purity on every sample.
- Deep CNN with millions of parameters on a few hundred images (Unit 6).
Symptoms: train loss tiny, validation loss large; big gap.
Materials-specific causes:
- Tiny \(N\): hundreds of micrographs, millions of weights.
- Group structure: 1000 patches from 5 specimens looks like 1000 samples but behaves like 5.
- Instrument fingerprints: the model learns “this is microscope A’s vignetting,” not the physics.
08. The Bias–Variance Decomposition
For squared-error regression with target \(y = f(x) + \varepsilon\), \(\mathbb{E}[\varepsilon]=0\), \(\mathrm{Var}(\varepsilon)=\sigma^2\) Bishop, Christopher M., (2006); Murphy, Kevin P., (2012):
\[ \mathbb{E}\bigl[(y - \hat f(x))^2\bigr] = \underbrace{\bigl(\mathbb{E}[\hat f(x)] - f(x)\bigr)^2}_{\text{Bias}^2} + \underbrace{\mathrm{Var}(\hat f(x))}_{\text{Variance}} + \underbrace{\sigma^2}_{\text{Irreducible}} \]
- Bias² ↓ as model complexity ↑.
- Variance ↑ as model complexity ↑.
- Irreducible (\(\sigma^2\)) is fixed by the physics of the measurement (Unit 2).
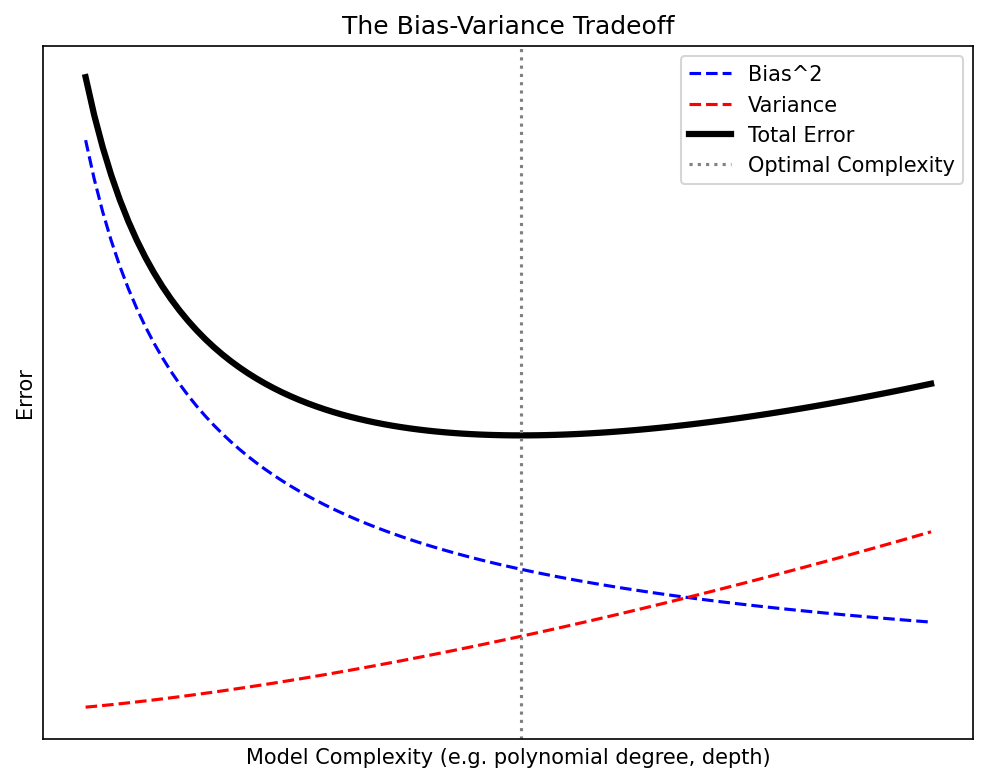
09. Reading the U-Curve
The classical “model selection” picture:
- Move right (more capacity) → bias falls, variance rises.
- The total-error curve has a minimum: this is the sweet spot \(\mathcal{M}^\star\).
- Capacity = parameter count, polynomial degree, tree depth, kernel bandwidth, NN width × depth.
Modern caveat (deep nets). In overparameterized networks the U-curve becomes a double descent: error rises near the interpolation threshold, then falls again deep into the overparameterized regime. We name it; we do not derive it. Pragmatically: regularize and CV either way.
11. Regularization — Keeping it Simple
Add a penalty on complexity to the training loss:
\[ \mathcal{L}_{\text{reg}}(\theta) \;=\; \mathcal{L}_{\text{data}}(\theta) \;+\; \lambda \cdot \Omega(\theta) \]
| \(\Omega(\theta)\) | Bayesian prior | Effect |
|---|---|---|
| \(\|\theta\|_2^2\) | Gaussian | shrinks all weights toward 0 |
| \(\|\theta\|_1\) | Laplace | sparsity — sets weights to 0 |
| \(\|\nabla \theta\|^2\) | smoothness | spatially smooth fields |
Other regularizers Goodfellow, Ian et al., (2016):
- Dropout (NN), early stopping, data augmentation (Unit 6), batch norm, weight averaging.
- All trade a little bias for a lot of variance.
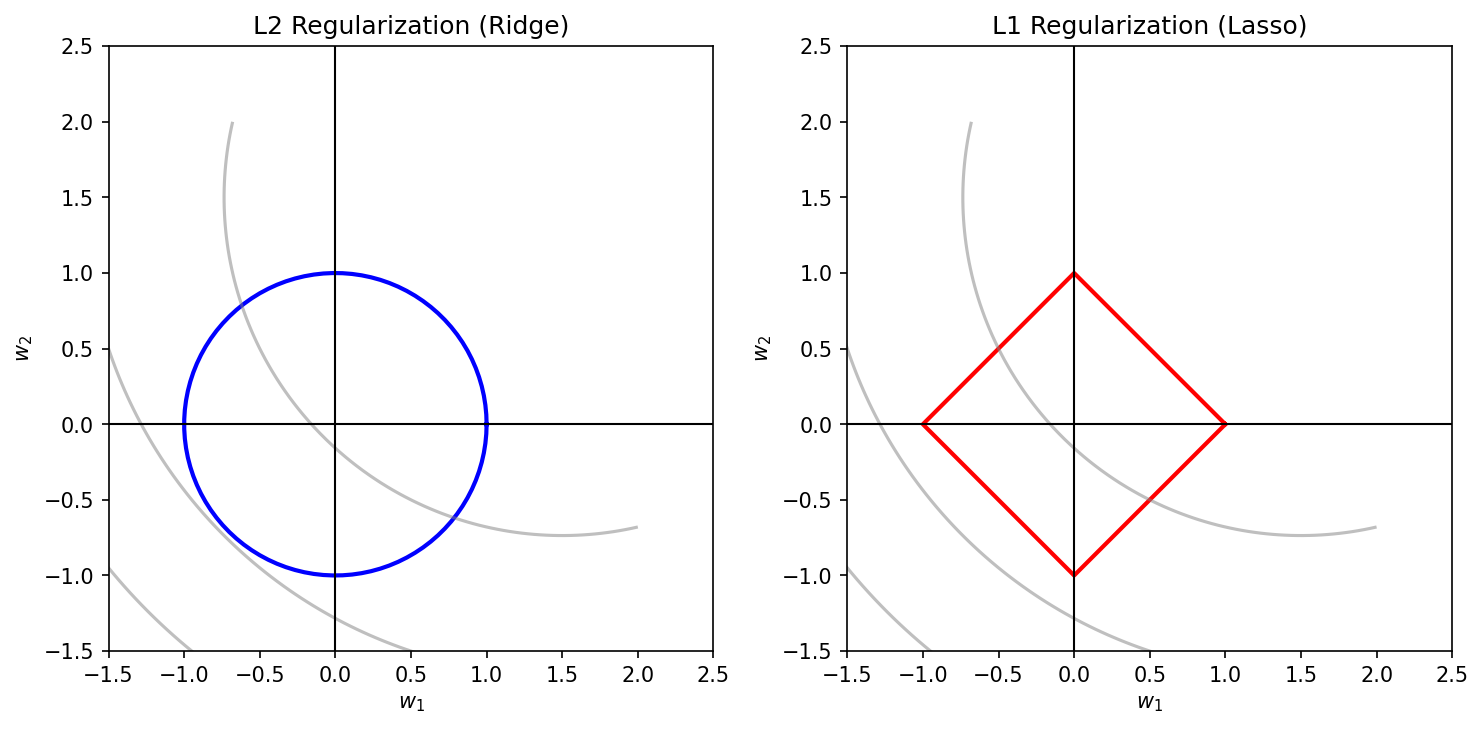
12. Regularization in Pictures
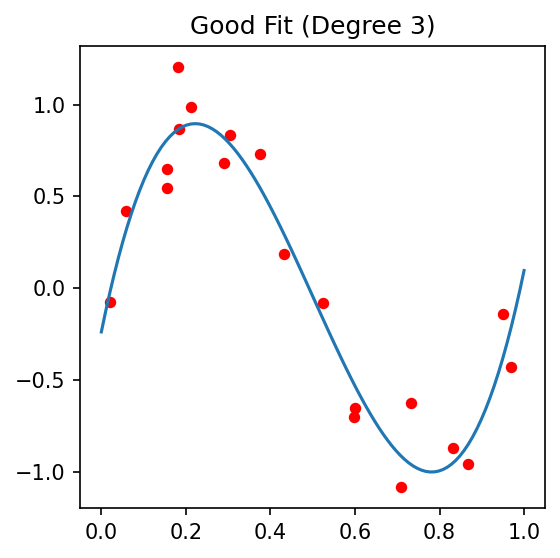
The same data, three values of \(\lambda\). Tuning \(\lambda\) is the most common single hyperparameter problem in applied ML.
20. Making CNNs Robust — Augmentation Recap
From Unit 6: augmentation = teaching invariances explicitly.
- Random flips, rotations, crops → rotational/translational invariance.
- Brightness/contrast jitter → exposure invariance.
- Gaussian / Poisson noise injection → noise invariance Bishop, Christopher M., (1995).
- MixUp / CutMix → mixed-sample interpolation invariance.
For materials specifically:
- Add realistic detector noise models, not generic Gaussian.
- Augment with instrument transfer functions — different PSFs simulate microscope swaps.
- Use physics-consistent augmentations only: a flipped diffraction pattern violates centrosymmetry of the lattice — a flipped grain map does not.
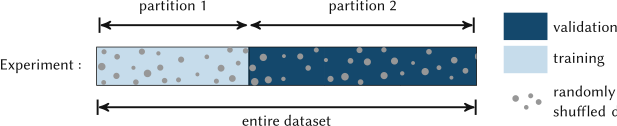
22. Cross-Validation — Getting More Out of Few Samples
The single hold-out problem. With \(N \approx 100\) samples, an 80/20 split tests on 20 — way too noisy, very dependent on which 20.
\(k\)-fold CV Sandfeld, Stefan et al., (2024):
- Partition the data into \(k\) disjoint folds.
- For \(i = 1, \dots, k\): train on the other \(k-1\) folds, test on fold \(i\).
- Report mean and std of the \(k\) test scores.
- \(k = 5\) or \(k = 10\): standard.
- \(k = N\): leave-one-out (LOOCV) — small bias, high variance, expensive.
- Each sample is in the test set exactly once.
33. The Traditional Process Map
Pre-ML construction:
- Run a designed experiment (DoE) over \((P, v)\) at a coarse grid.
- Section the parts; measure porosity, defects.
- Hand-draw “good” and “bad” regions on the \((P, v)\) plane.
Limitations:
- Coarse grid → boundaries are interpolated by eye.
- No uncertainty estimate on the boundary.
- Each new alloy / machine / powder requires a fresh DoE.
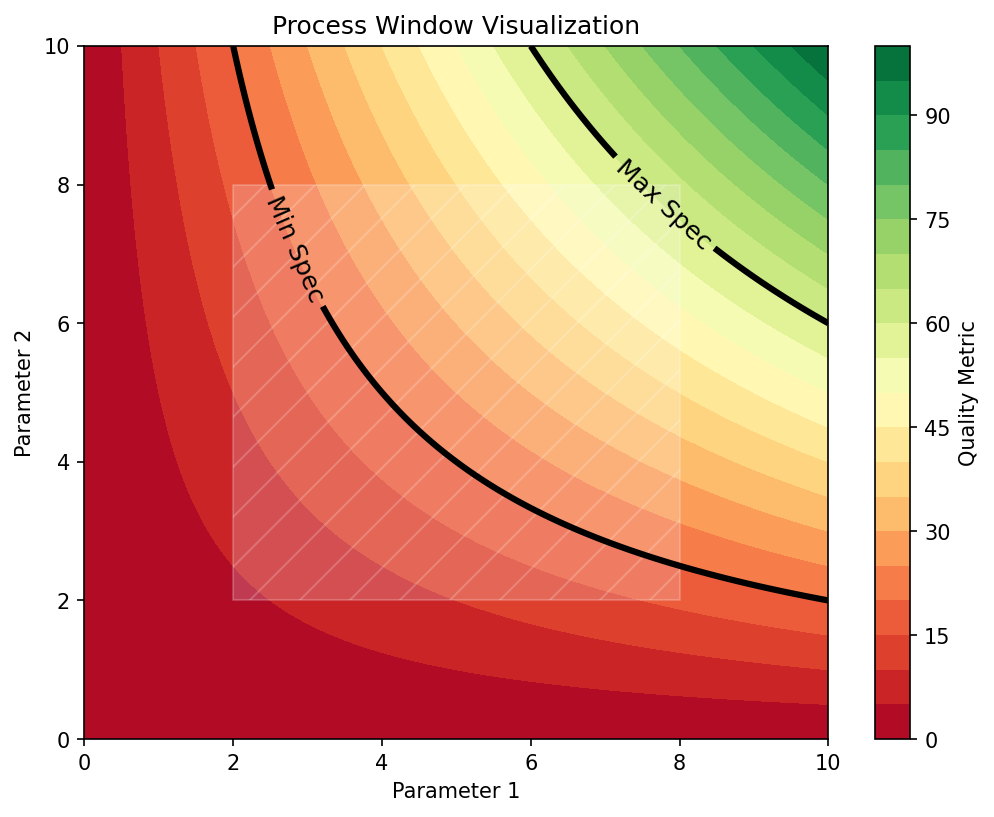
35. Probabilistic Windows — Add Uncertainty Bars
A sharp boundary lies. Use probability contours.
- Output of the classifier is \(p(\text{pass}\mid \eta) \in [0, 1]\).
- Draw the 95% safe contour: \(\{\eta : p \ge 0.95\}\).
- Draw the uncertain band: \(\{\eta : 0.05 < p < 0.95\}\).
Operational use:
- Inside the 95% contour: qualified operating region.
- In the uncertain band: do more experiments before shipping.
- Outside: do not operate.
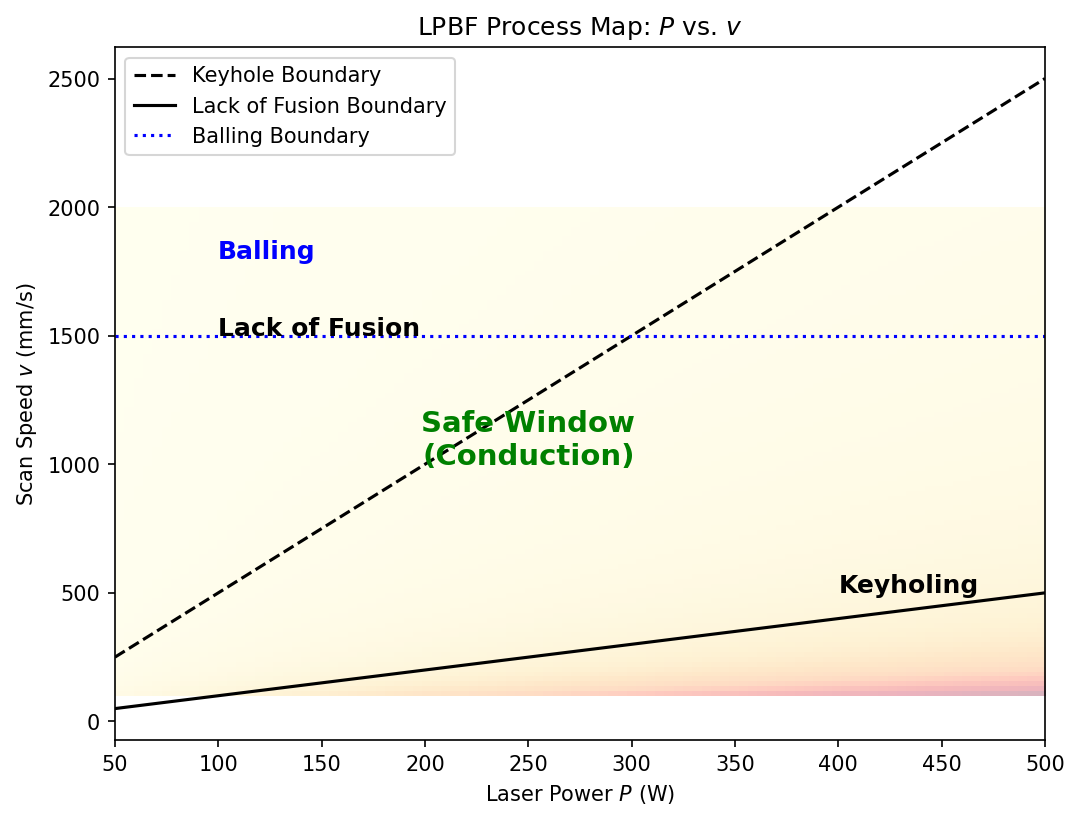
37. Case Study — Additive Manufacturing \((P, v)\)
The canonical AM process map. Laser-powder-bed fusion (L-PBF):
- \(P\): laser power, 100–400 W.
- \(v\): scan velocity, 0.5–3 m/s.
- Energy density \(E = P / (v \cdot t \cdot h)\) — a useful but incomplete derived feature.
Three regimes (drawn on the chalkboard):
- Low \(E\) — lack of fusion: incomplete melting, porosity, weak parts.
- Intermediate \(E\) — conduction mode: dense, sound parts. The window.
- High \(E\) — keyholing: vapor cavity, instability, deep porosity.