Machine Learning in Materials Processing & Characterization
Unit 7: Time-series and process monitoring




09. The recurrent neuron
Feed-forward neuron.
\[y = \sigma(Wx + b)\]
- Input → output, no memory.
- Each example processed independently.
Recurrent neuron (McClarren 2021, sec. 7.1).
\[h_t = \sigma(W_h h_{t-1} + W_x x_t + b)\]
- Output at \(t-1\) feeds back as an input at \(t\).
- A loop in the computational graph.
- \(h_t\) summarises everything seen up to \(t\).
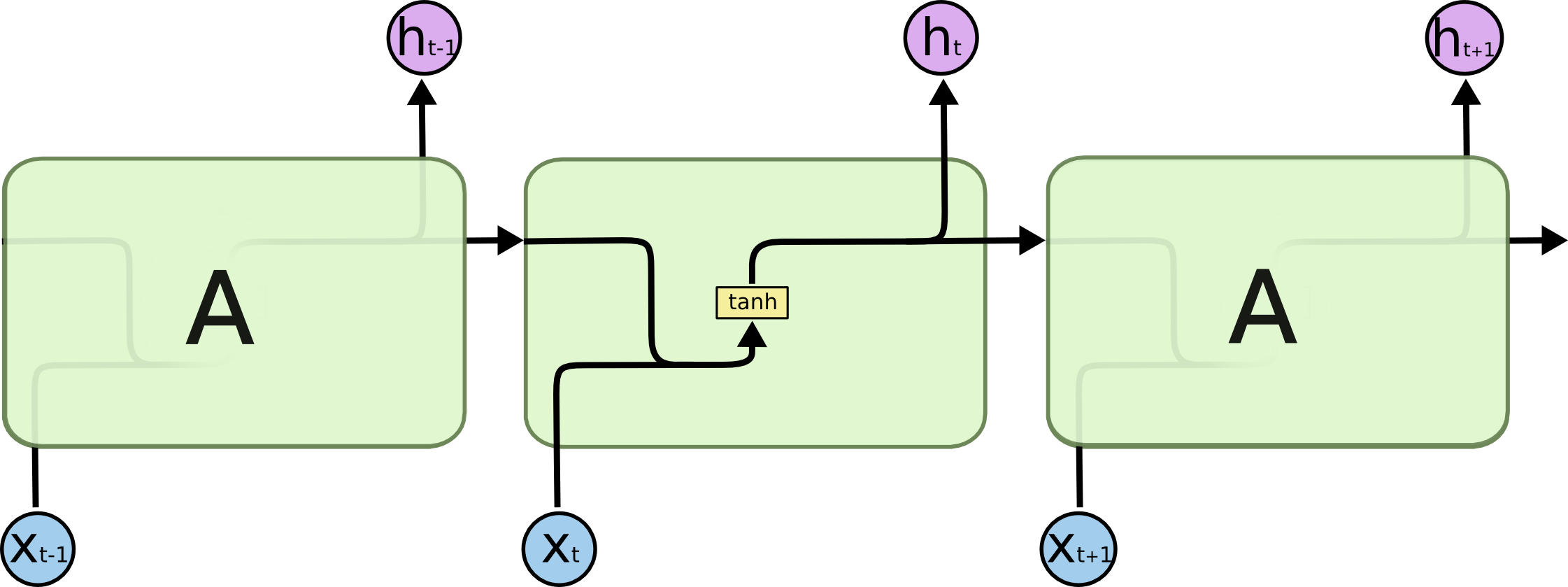
Standard RNN: the repeating module contains a single \(\tanh\) layer. Image: colah’s blog.
10. Unrolling and weight sharing
Unrolled view.
- Visualise the loop as a sequence of identical layers — one per time step.
- The same parameters \((W_h, W_x, b)\) apply at every step.
- This is the source of generalisation across sequence length.
Forward equations.
\[h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b_h)\] \[\hat y_t = W_{hy} h_t + b_y\]
- Same network can process \(T = 10\) or \(T = 1000\).
- Cost is \(O(T)\) per forward pass.
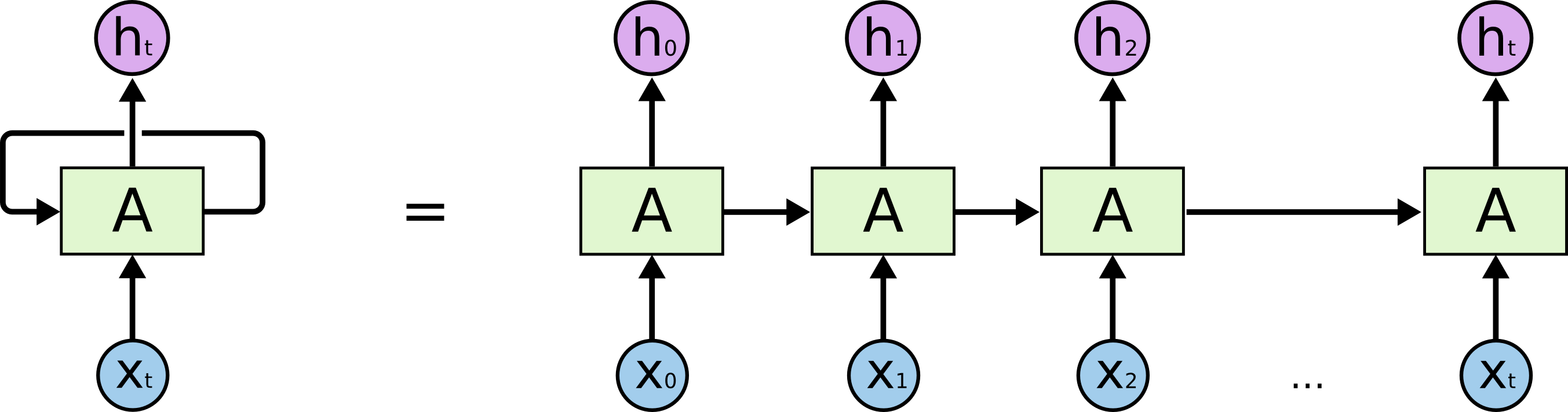
Unrolled RNN — a loop becomes a chain of identical layers. Image: colah’s blog.
16. The LSTM cell state
\(C_t\) as a conveyor belt.
- Runs through the sequence with minimal interaction.
- Gradient flows along \(C\) almost unchanged — additive updates, no repeated multiplication by \(W\).
- Carries long-term memory.
\(h_t\) vs \(C_t\).
- \(h_t\) is the output — what downstream layers see.
- \(C_t\) is the internal memory — typically not exposed.
- Both have the same dimension; the parameter count of an LSTM is roughly \(4\times\) that of a vanilla RNN of the same hidden size.
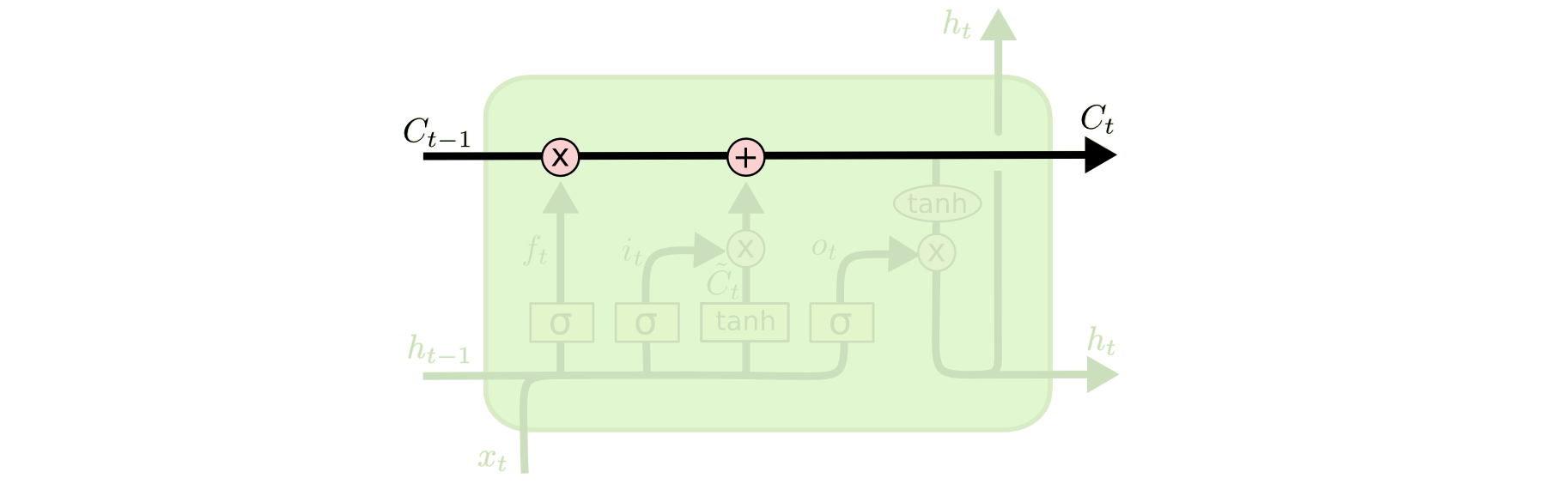
The cell state \(C_t\) flows along the top of the cell like a conveyor belt, modified only by gated additive updates. Image: colah’s blog.
17. The three gates
Forget gate. What to drop from \(C_{t-1}\). \[f_t = \sigma(W_f [h_{t-1}, x_t] + b_f)\]
Input gate. What new information to write. \[i_t = \sigma(W_i [h_{t-1}, x_t] + b_i)\] \[\tilde C_t = \tanh(W_C [h_{t-1}, x_t] + b_C)\]
Cell-state update. \[C_t = f_t \odot C_{t-1} + i_t \odot \tilde C_t\]
Output gate. What to expose as \(h_t\). \[o_t = \sigma(W_o [h_{t-1}, x_t] + b_o)\] \[h_t = o_t \odot \tanh(C_t)\]
Each gate is a small sigmoid network on \((h_{t-1}, x_t)\).

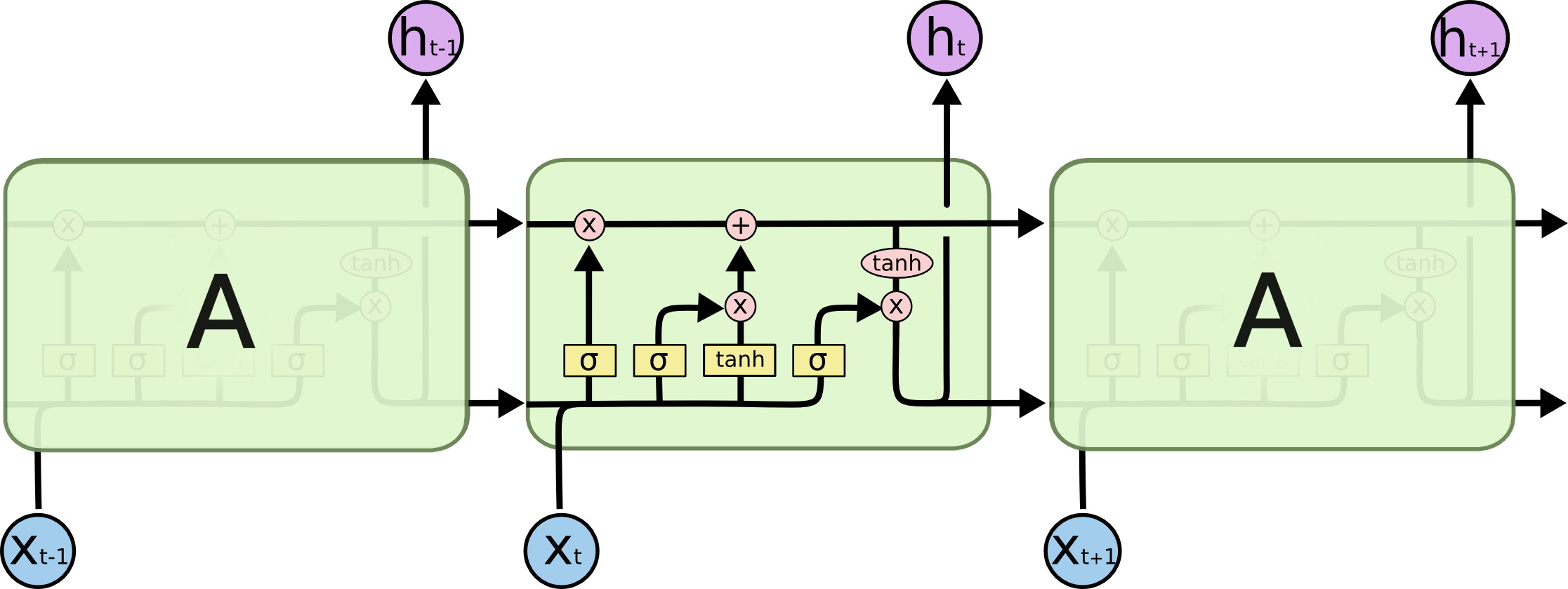
18. Why LSTMs do not vanish
The crucial line. \[C_t = f_t \odot C_{t-1} + i_t \odot \tilde C_t\]
When \(f_t \approx 1\) and \(i_t \approx 0\) (forget nothing, write nothing), \(C_t \approx C_{t-1}\) — the identity in the recurrence.
Gradient flow.
- \(\partial C_t / \partial C_{t-1} = f_t\).
- If \(f_t\) is on (close to 1), gradient flows back unchanged.
- The additive structure prevents the multiplicative collapse.
- Long-range dependencies become learnable.
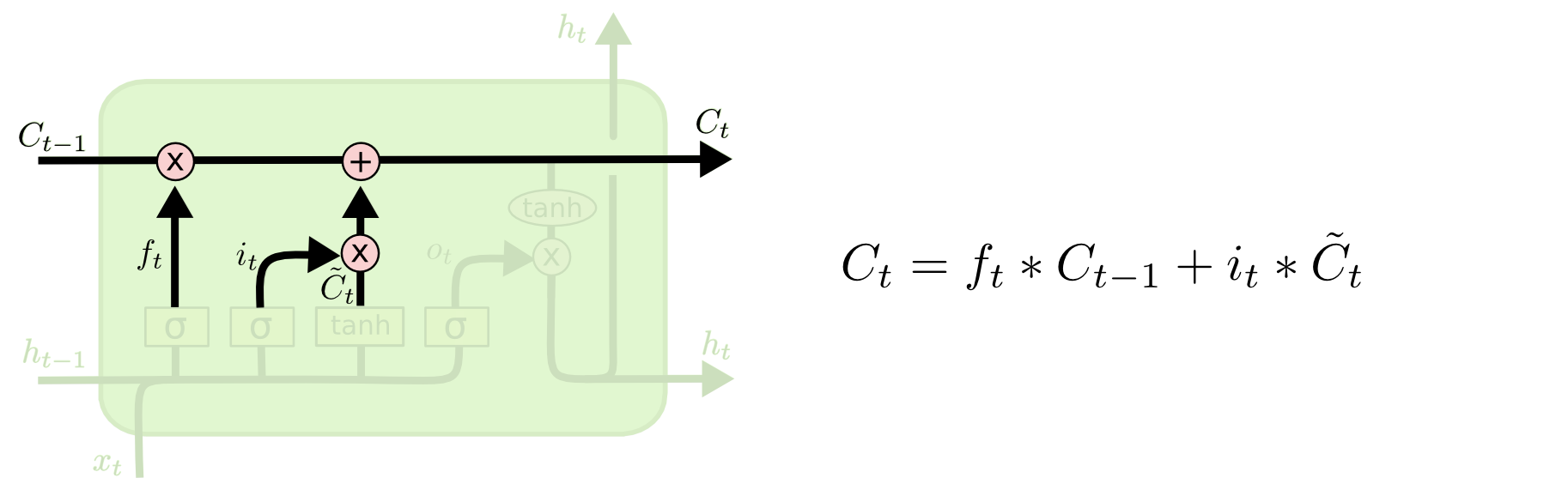
Cell-state update \(C_t = f_t \odot C_{t-1} + i_t \odot \tilde C_t\) — additive, with \(\partial C_t / \partial C_{t-1} = f_t \approx 1\) when the forget gate is on. Image: colah’s blog.
19. GRU — a simpler gate structure
Gated Recurrent Unit (Cho et al. 2014).
- Merges \(C\) and \(h\) into a single state.
- Two gates: update \(z_t\) (= forget + input combined), reset \(r_t\).
\[z_t = \sigma(W_z[h_{t-1}, x_t])\] \[r_t = \sigma(W_r[h_{t-1}, x_t])\]
Update. \[\tilde h_t = \tanh(W_h[r_t \odot h_{t-1}, x_t])\] \[h_t = (1-z_t) \odot h_{t-1} + z_t \odot \tilde h_t\]
- \(\sim 3\times\) the parameters of a vanilla RNN (vs \(\sim 4\times\) for LSTM).
- Comparable performance on most tasks.

GRU: update gate \(z_t\) merges forget+input, reset gate \(r_t\) modulates the candidate; single state \(h_t\). Image: colah’s blog.
26. Worked example — separating the two
Synthetic melt-pool signal.
- Ground truth \(\mu^*(t)\): smooth radius trajectory.
- Add Gaussian noise \(\sigma_a\) — known aleatoric component.
- Train an LSTM on \(N\) examples — epistemic component shrinks as \(N\) grows.
Decomposition recipe.
- Train \(K\) models with different seeds (or use MC dropout — Slide 32).
- At each \(t\), model \(k\) outputs \((\mu_k, \sigma_k)\) — heteroscedastic Gaussian head.
- Aleatoric: \(\bar\sigma^2_a = \tfrac{1}{K}\sum_k \sigma_k^2\).
- Epistemic: \(\sigma^2_e = \mathrm{Var}_k(\mu_k)\).
Synthetic melt-pool signal — the kind of trace we will train on.
35. Recalibration — Platt and isotonic
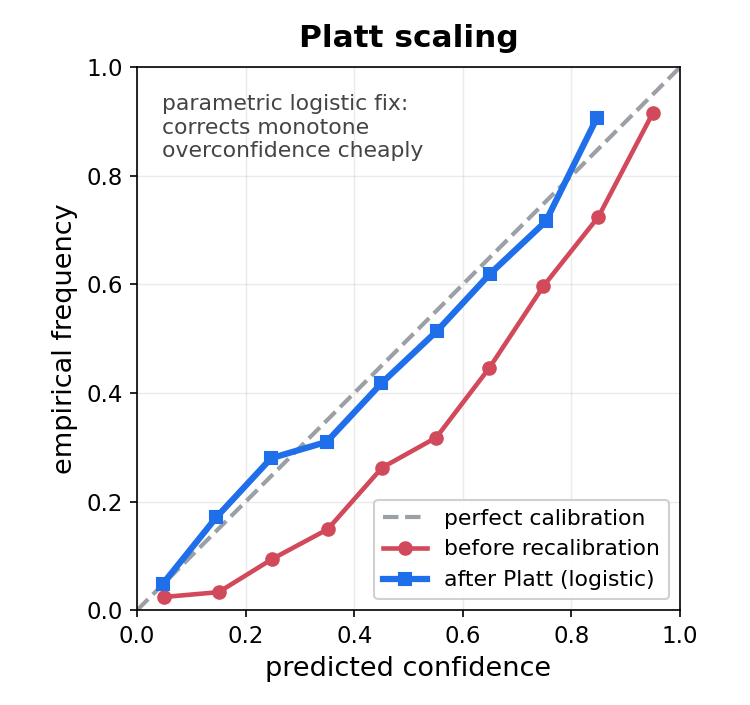
Platt scaling.
- Fit a logistic mapping \(\sigma \mapsto a\sigma + b\) on the validation set.
- Two parameters; cheap; assumes a parametric form.
- Good first attempt; fails when miscalibration is non-monotone.
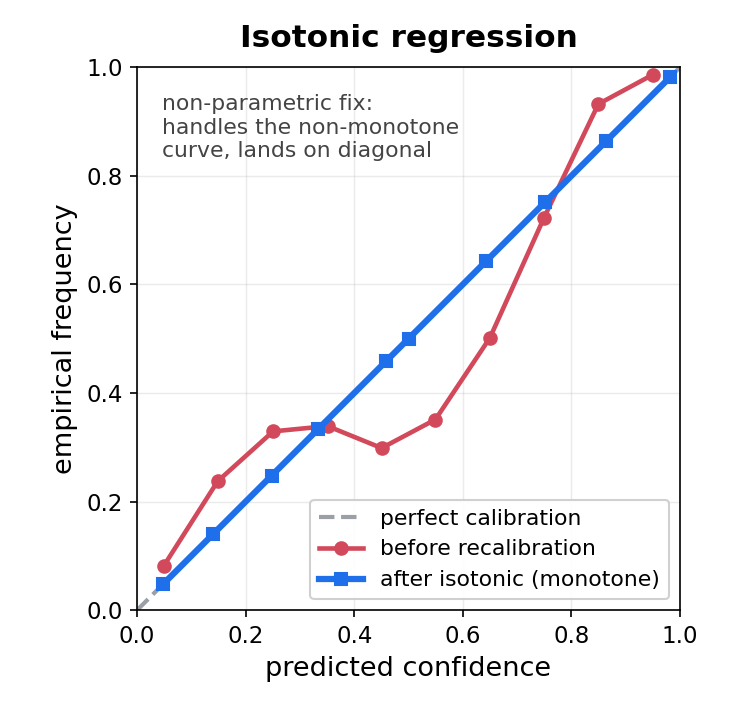
Isotonic regression.
- Fit a non-parametric monotone remapping on the validation set.
- More flexible; needs more validation data.
- Gold standard when the calibration curve is non-trivial.
Always recalibrate on a held-out set you did not train on. Otherwise you are fitting calibration on the same data you measured it from — guaranteed-good calibration plot, no real improvement.
39. Anomaly detection via predictive likelihood
The score.
\[s_t = -\log p_\theta(x_{t+1}\mid x_{1:t})\]
- Low likelihood → high anomaly score.
- Threshold \(s_t > \tau\) → flag.
- \(\tau\) chosen via desired false-alarm rate on a clean set.
Contrast with W5 (autoencoder anomaly).
- AE: anomaly = high reconstruction error of a static input.
- Sequence model: anomaly = low predictive likelihood of the next observation.
- Different priors, different failure modes.
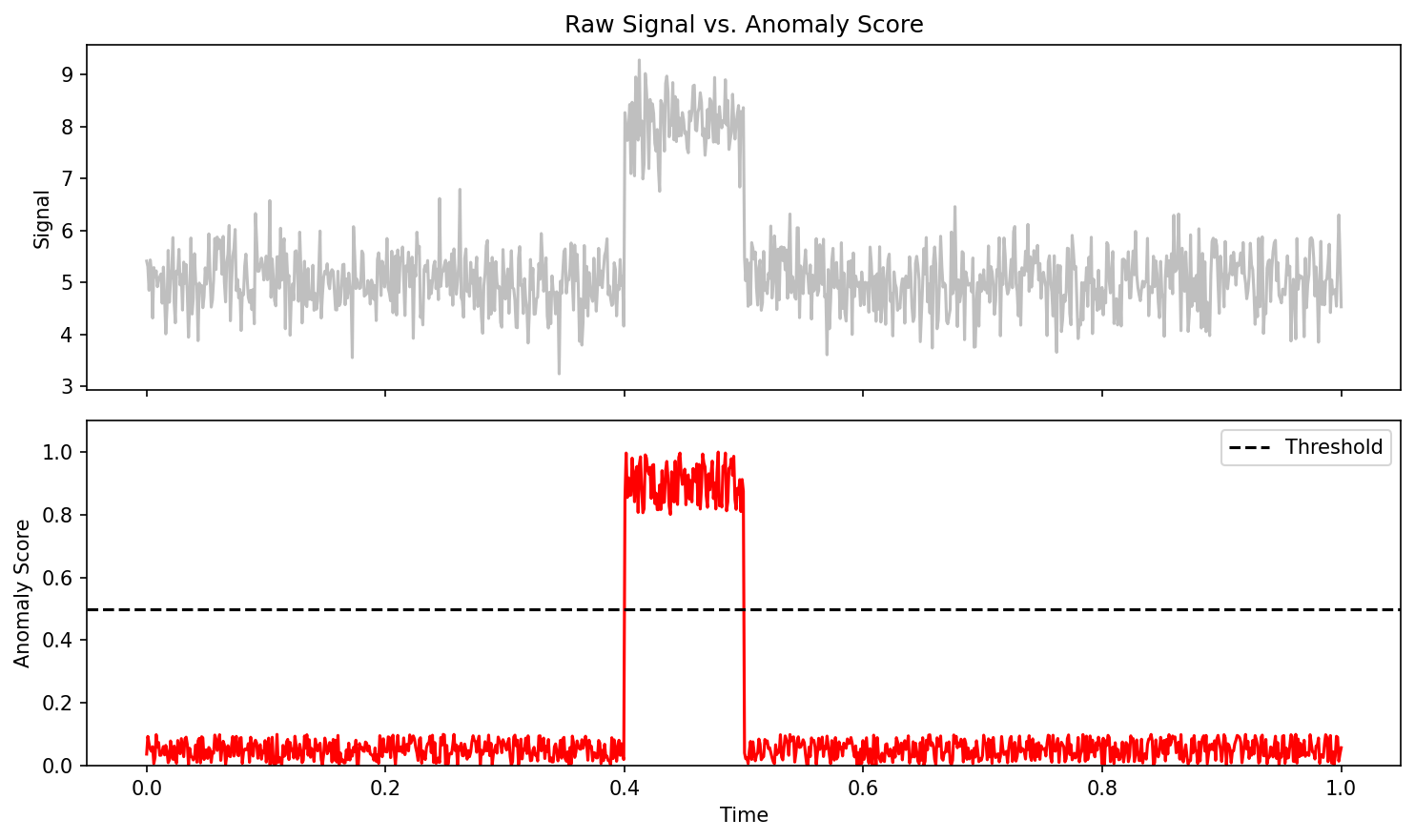
Anomaly score over time — predictive likelihood drops sharply at process events.
44. Recovering frequency from a noisy sine — McClarren example
The toy.
\[y(t) = \sin(\omega t) + \varepsilon, \quad \varepsilon \sim \mathcal N(0, \sigma_\mathrm{noise}^2)\]
- LSTM predicts \(y(t+\Delta t)\).
- Vary \(\sigma_\mathrm{noise}\) and the training-set size; observe regimes (McClarren 2021).
With probabilistic head.
- Heteroscedastic Gaussian head reports \(\sigma_t\).
- Calibration plot: does the predicted 90 % CI contain truth 90 % of the time?
- Educational and tractable — McClarren’s textbook example, upgraded.
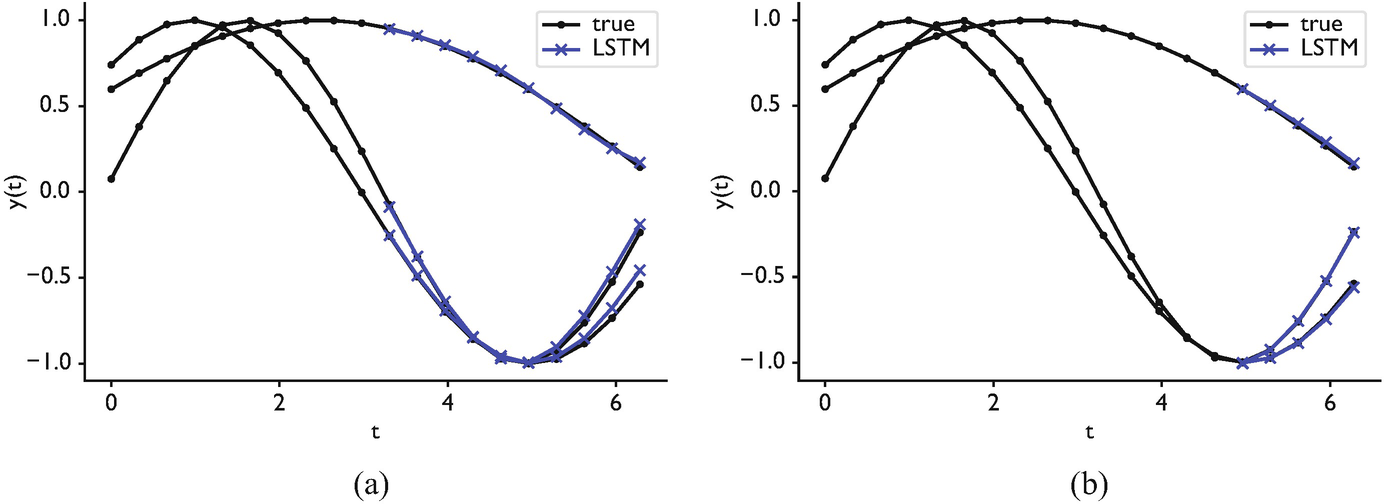
LSTM tracking a noisy sine — the simplest sandbox for probabilistic forecasting.