Data Science for Electron Microscopy
Week 8: Unsupervised learning & autoencoders for EM




The unsupervised learning landscape
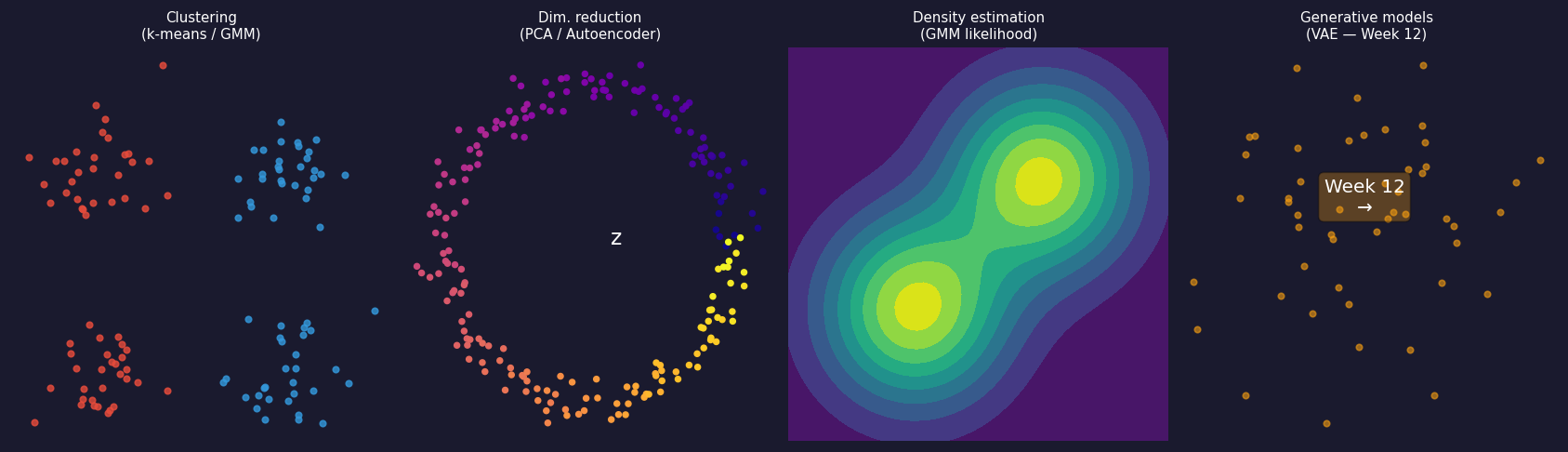
The four families of unsupervised learning. Clustering assigns each spectrum to a discrete group (k-means, GMM). Dimensionality reduction finds a low-dimensional coordinate that summarises each spectrum (PCA, autoencoder). Density estimation models the full probability distribution over spectra. Generative models sample new spectra from that distribution — introduced as a teaser for Week 12.
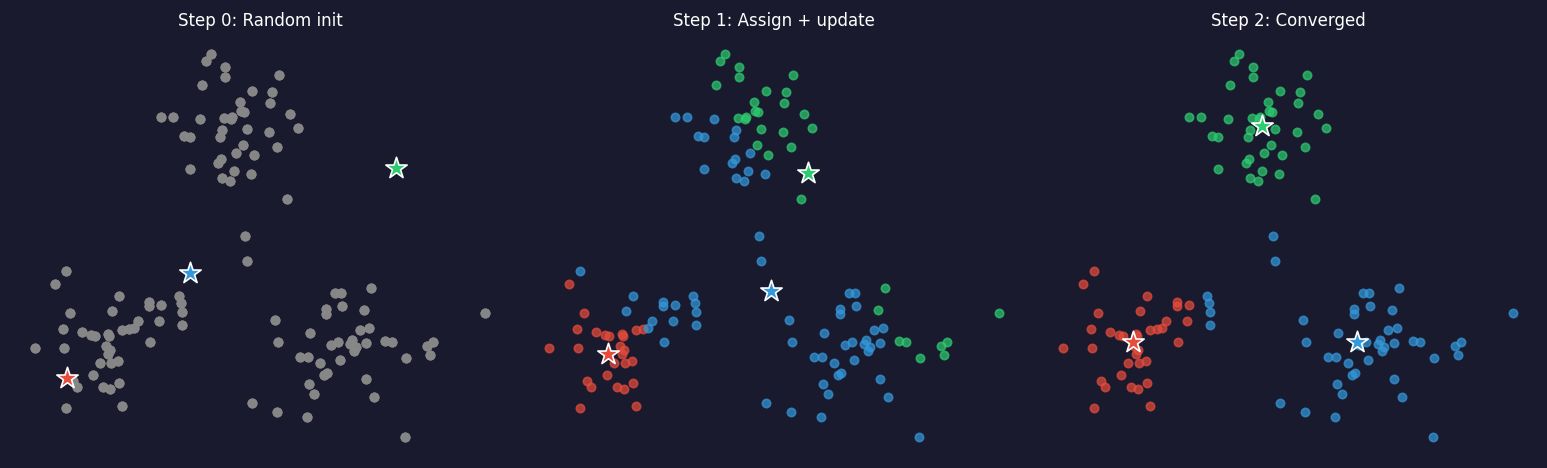
K-means: objective and Lloyd’s algorithm
Assign \(N\) spectra \(\{x_1, \ldots, x_N\} \subset \mathbb{R}^d\) to \(K\) groups \(C_1, \ldots, C_K\) by minimising:
\[ J = \sum_{k=1}^{K} \sum_{x_i \in C_k} \|x_i - \mu_k\|^2. \]
Lloyd’s algorithm — alternate two steps until assignments stop changing:
- Assign: each spectrum goes to its nearest centroid \(\mu_k\).
- Update: each centroid moves to the mean of its assigned spectra.
Each step strictly decreases \(J\); convergence in finitely many steps is guaranteed — to a local minimum.
GMM: soft clustering for overlapping phases

Hard vs soft assignment on the same spectral dataset. Left: k-means — each point belongs to exactly one phase (coloured circles). Right: GMM — each point carries a probability over phases; points near boundaries are shown as colour mixtures. This matters physically when EELS spectra from a transition zone contain contributions from both adjacent phases.
The manifold hypothesis: why compression works
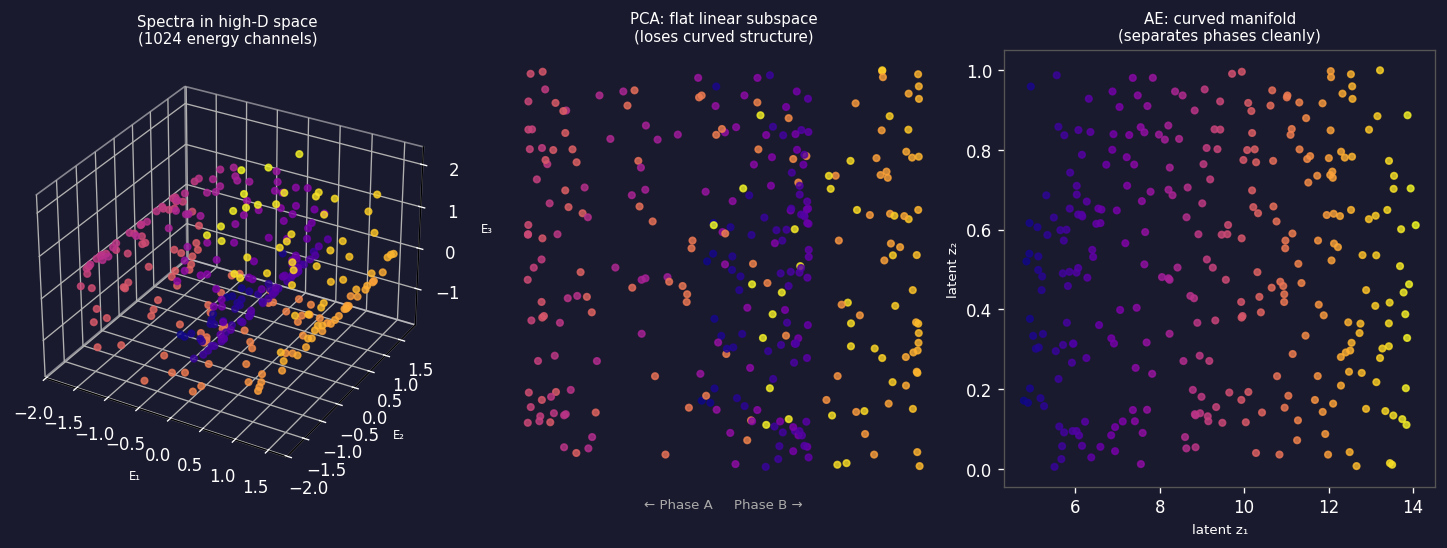
From high-dimensional spectra to a curved low-dimensional manifold. Left: three-dimensional view of data lying on a curved 2D surface embedded in 3D (analogy for 1024-D spectra on a ~10-D surface). Centre: PCA finds the best flat hyperplane — it unrolls the curve linearly and loses structure. Right: a nonlinear autoencoder follows the curved manifold, keeping phases separated along interpretable latent axes.
Autoencoder architecture: encoder–bottleneck–decoder
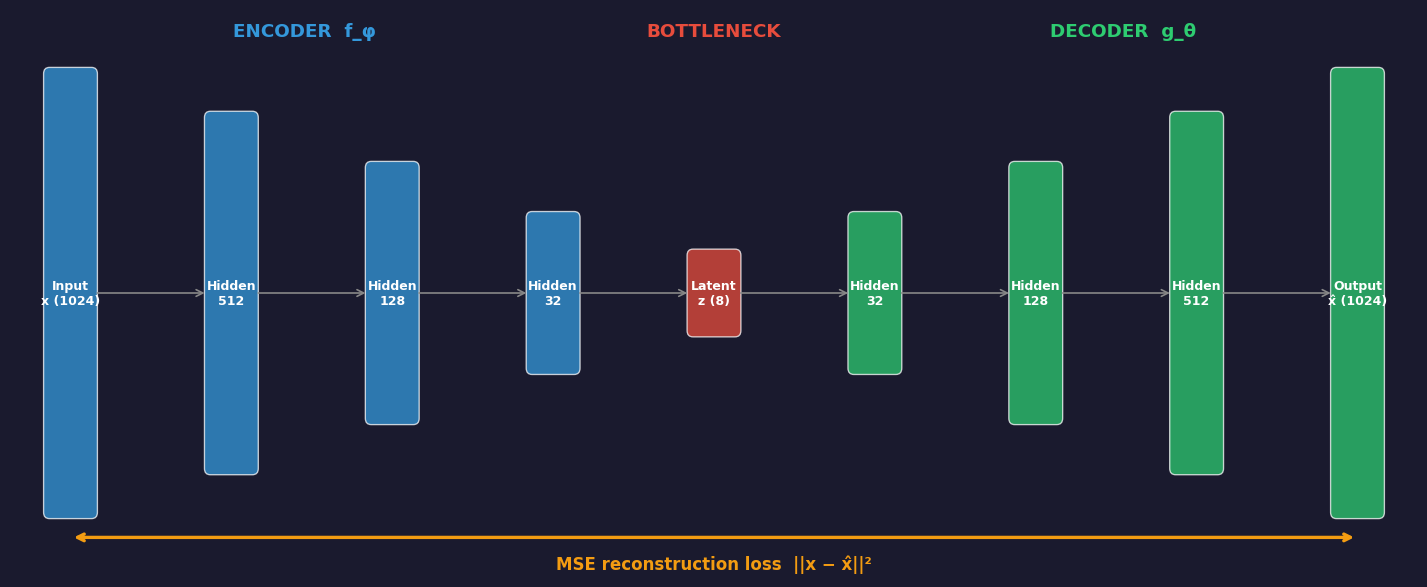
A deep autoencoder for spectral data. The encoder (blue, left) progressively compresses a 1024-channel spectrum to an 8-dimensional latent code z through successive hidden layers. The decoder (green, right) reconstructs the original 1024 channels from z. The bottleneck (red, centre) is the only constraint: it must retain enough information to reconstruct the input. The MSE reconstruction loss (orange, bottom) is the only supervisory signal — no labels needed.
Linear AE vs nonlinear AE: the geometric picture
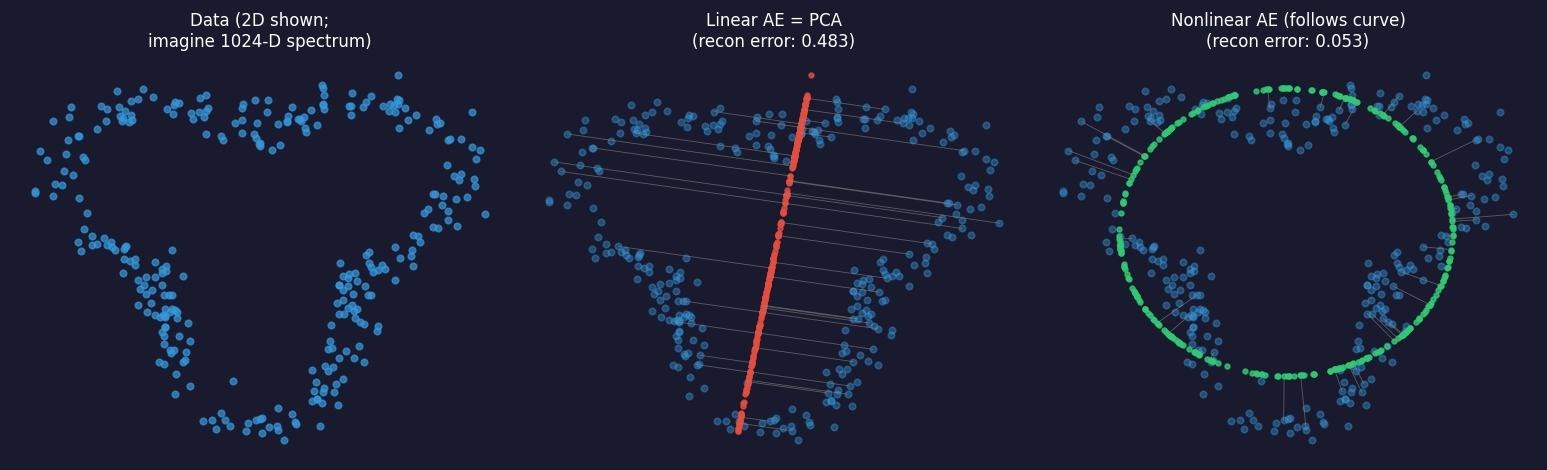
Left: data lying on a curved 2D line embedded in the plane. Centre: linear AE (= PCA) projects onto the best straight line — many points are far from the line (high reconstruction error, orange residuals). Right: nonlinear AE follows the curved surface — all points are close (low reconstruction error, green residuals). This is why a nonlinear AE outperforms PCA when the spectral manifold is curved.
Denoising AE: results on synthetic EELS spectra
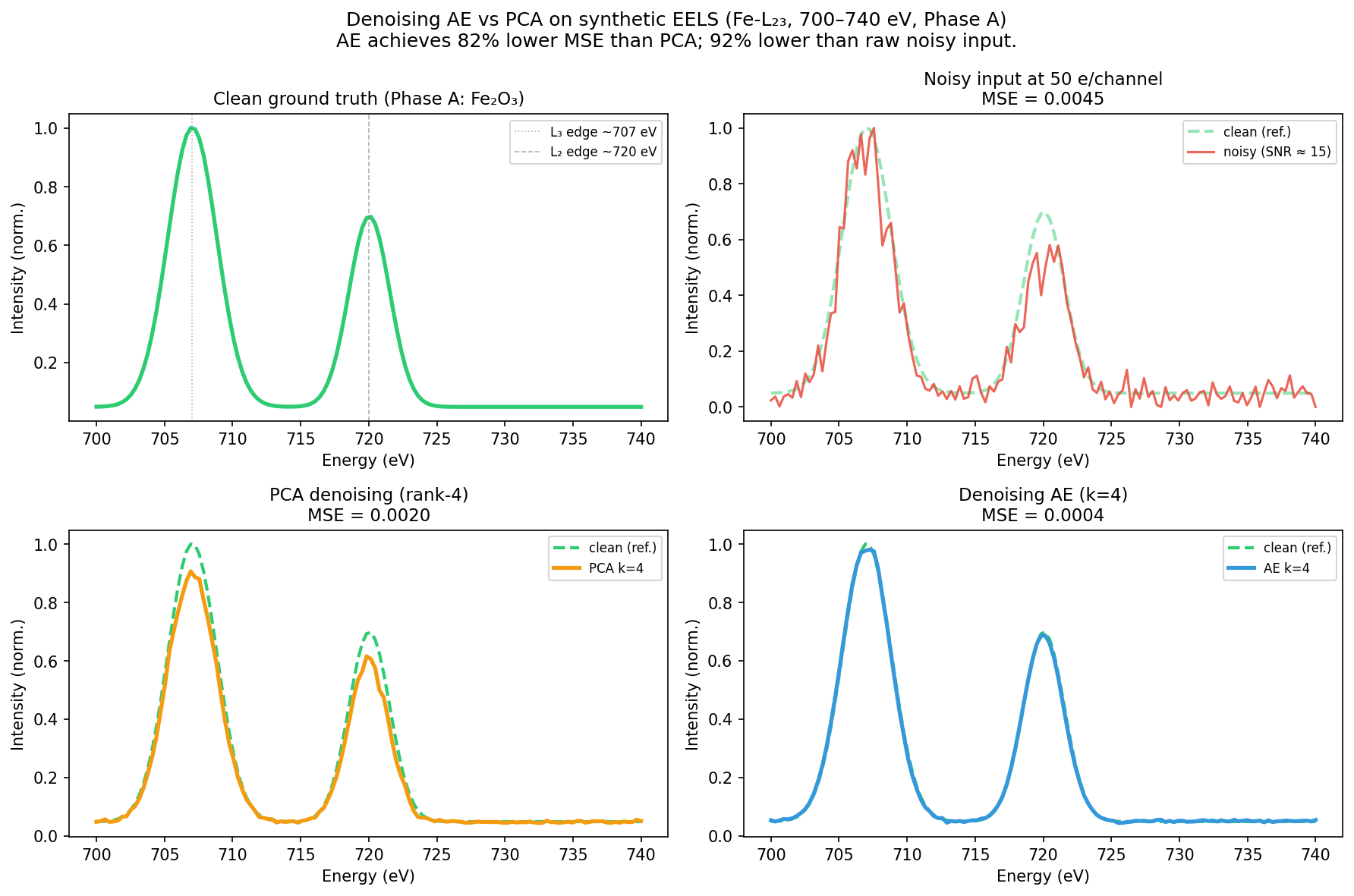
Denoising performance on synthetic low-dose EELS spectra near the Fe-L₂₃ edge (700–740 eV). Top-left: clean ground-truth spectrum (two Gaussian peaks: L₃ main edge ~707 eV and L₂ shoulder ~720 eV). Top-right: noisy input at 50 electrons/channel (Poisson noise). Bottom-left: PCA denoising (rank-4) — the MSE title shows the quantitative cost of linear approximation. Bottom-right: denoising AE (k=4) — achieves ≈81% lower MSE than PCA and ≈92% lower than the raw noisy input. Green dashed line is the clean reference in the bottom panels. PCA recovers the spectral shape but at ~5× higher reconstruction error; the AE captures the non-linear inter-phase variation and denoises with far less residual error.
The latent space: a learned coordinate system
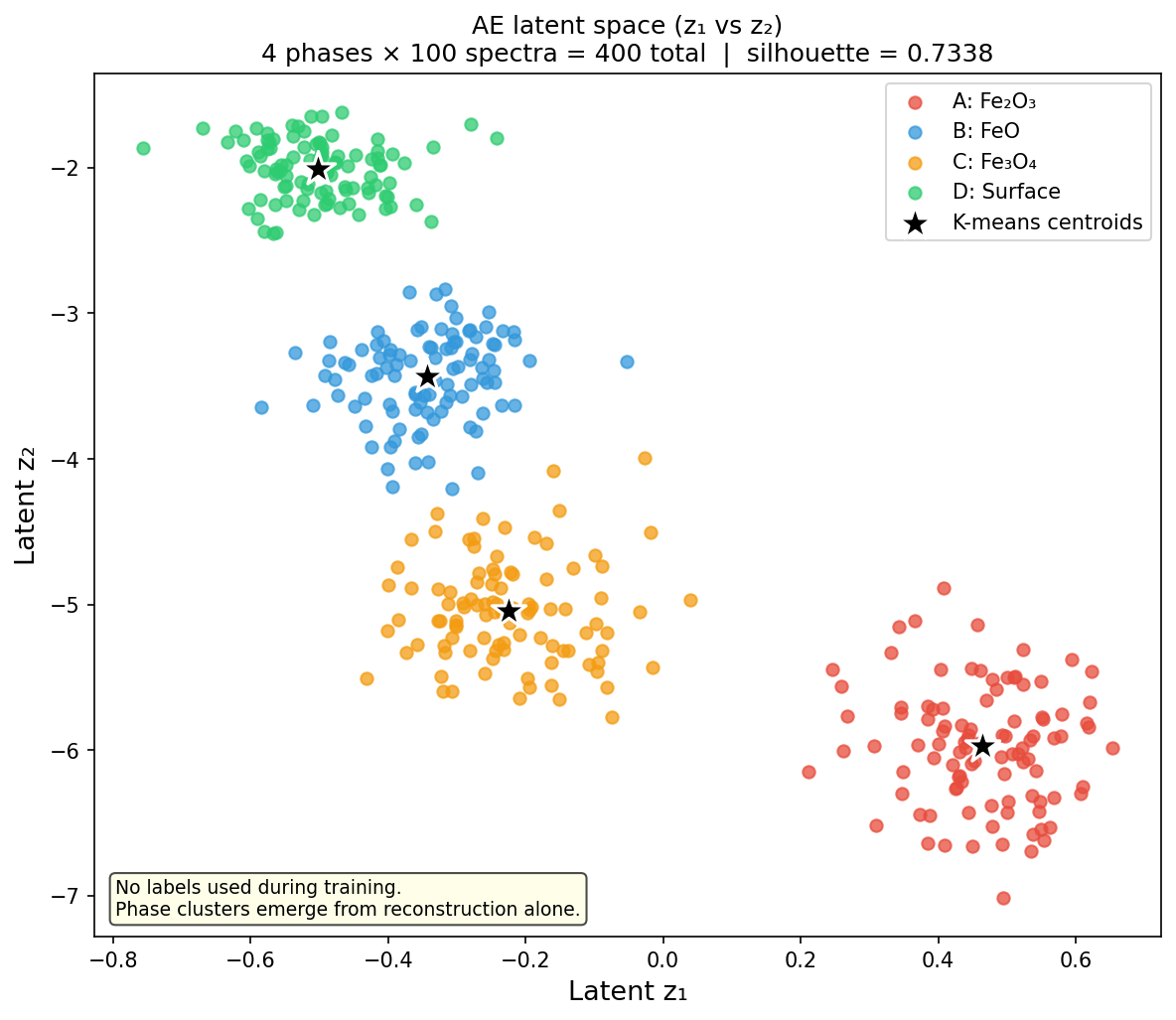
AE latent space (z₁ vs z₂) for 400 synthetic iron-oxide EELS spectra (4 phases, 100 spectra each: Fe₂O₃ red, FeO blue, Fe₃O₄ orange, Surface/amorphous green). The four phases cluster into well-separated islands without any labels — the only information the AE received was the raw spectra and the instruction to reconstruct them. Stars mark the k-means cluster centroids applied to the 4-D latent codes (silhouette ≈ 0.73). Only z₁ and z₂ are shown; all four latent dimensions contribute to the clustering.
t-SNE and UMAP: visualising high-dimensional latent codes
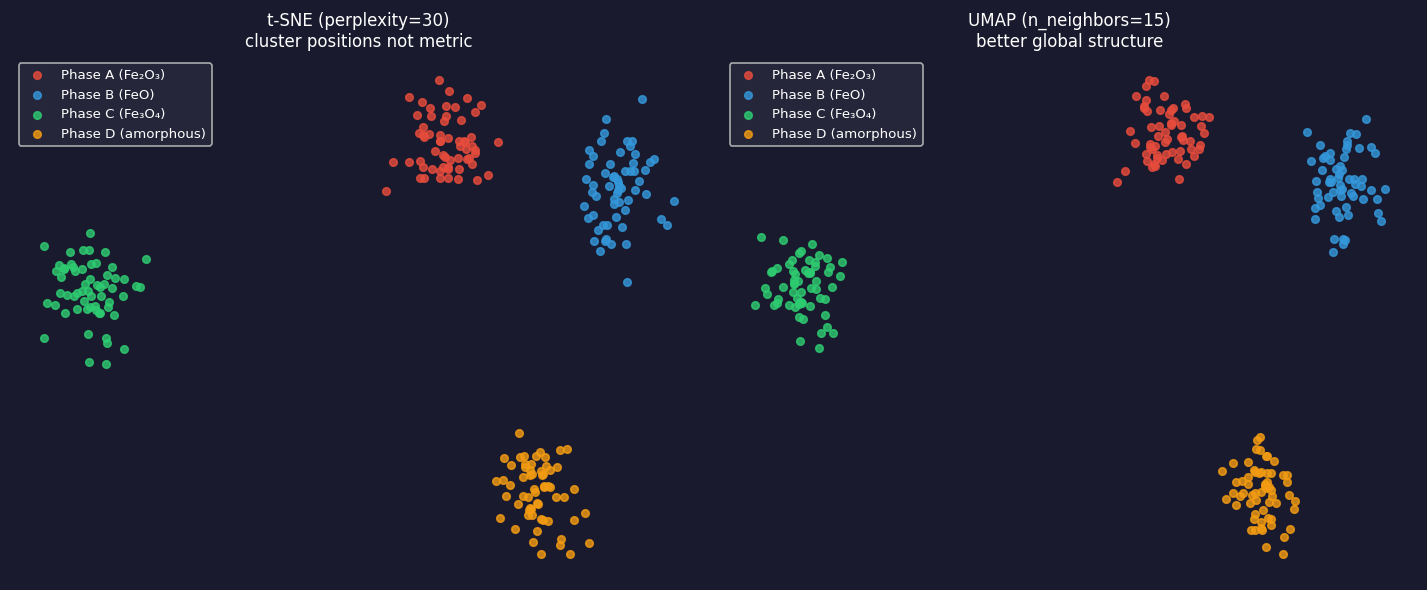
Left: t-SNE (perplexity=30) — 2D embedding of 240 latent codes from a 10-D AE. Four iron-oxide phases form islands. Warning: inter-island distances are not metric — the gap between Fe₂O₃ and FeO in this plot does not reflect their spectral similarity. Right: UMAP (n_neighbors=15) — same codes, tighter clusters, better preservation of global structure. Use UMAP for 2026 pipelines; t-SNE is a useful diagnostic.
Anomaly/novelty detection: reconstruction error as a score
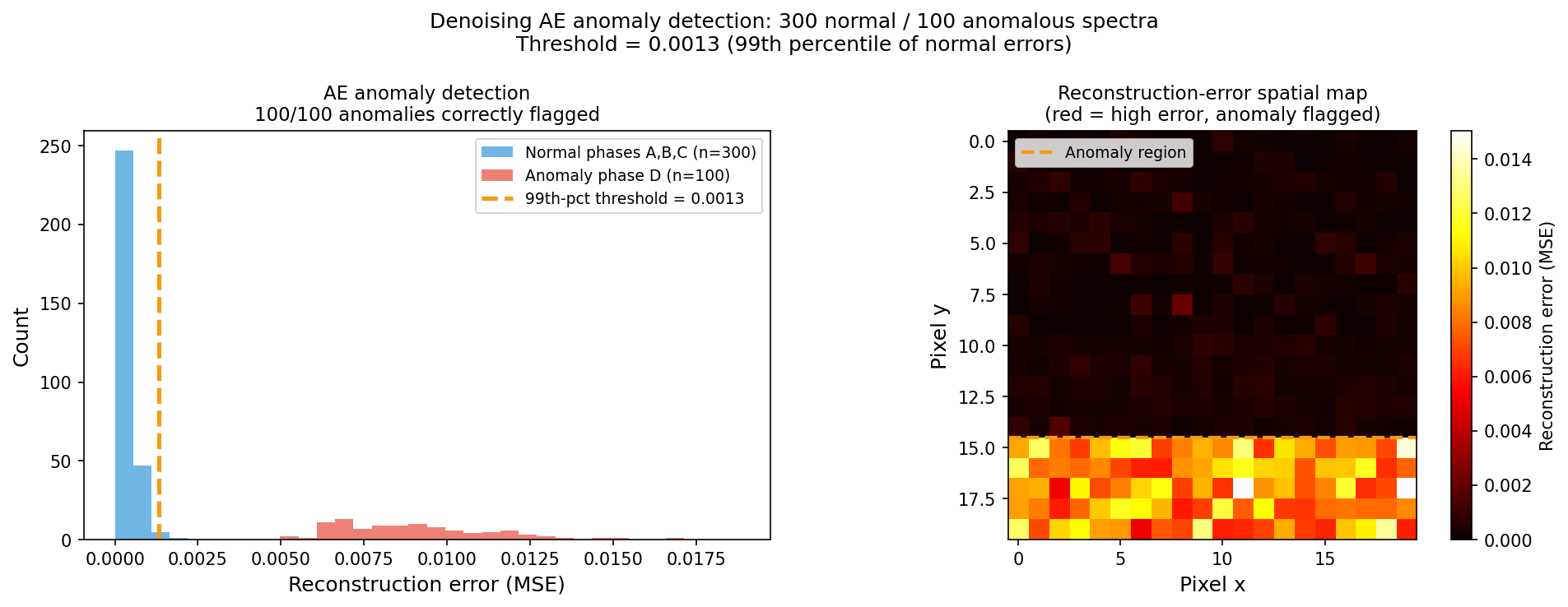
Left: reconstruction error distribution for 300 normal iron-oxide spectra (phases A, B, C; blue) and 100 anomalous spectra from Phase D (surface/amorphous; red). The AE was trained on normal spectra only. Anomalies reconstruct poorly — they lie outside the manifold the AE learned — with mean error ~25× higher than normal spectra. The 99th-percentile threshold ≈ 0.0013 (orange dashed line) flags all 100/100 anomalies correctly. Right: simulated reconstruction-error spatial map where the high-error region (bottom rows) marks anomalous Phase D pixels.
VAE preview: from discrete codes to a structured distribution
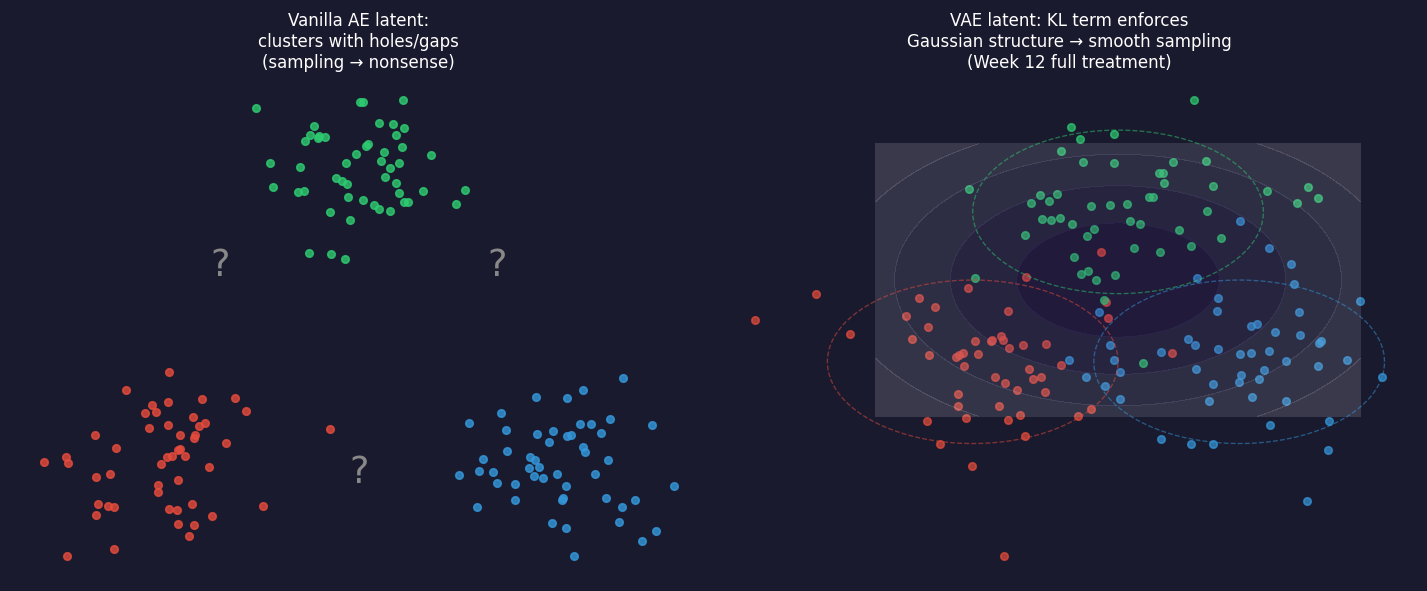
Left: vanilla AE latent space — clusters form but with gaps between them (question marks). Sampling from the gaps (grey arrows) decodes to nonsense because those regions were never seen during training. Right: VAE latent space — the KL divergence term forces the encoding distribution toward a Gaussian; the space is continuous and sampling anywhere gives a meaningful spectrum. Full VAE mathematics are Week 12.
Putting it all together: the unsupervised EM pipeline
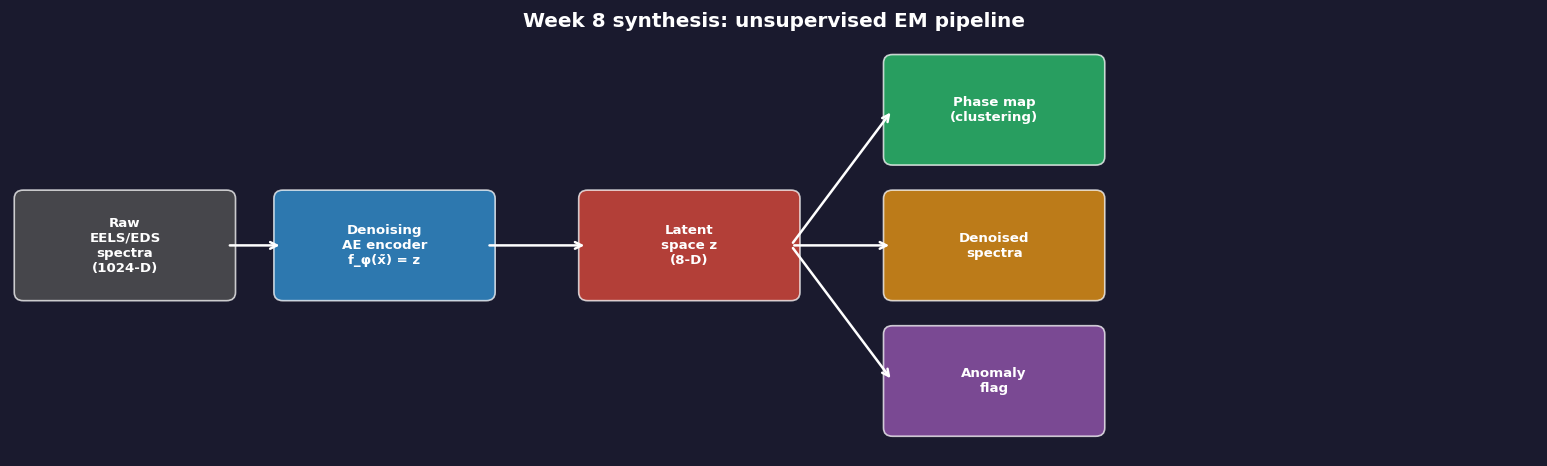
Complete pipeline from raw EELS/EDS spectra to actionable outputs. Raw spectra enter a denoising AE encoder; the latent space \(z\) branches into three outputs: (1) a phase map via k-means clustering, (2) denoised spectra via the decoder, and (3) anomaly flags where reconstruction error exceeds the threshold. All three outputs require zero labels.