Data Science for Electron Microscopy
Week 11: Imaging inverse problems I




The forward model: \(y = Hx + \epsilon\)

The computational imaging chain: the unknown object \(x\) (left, a synthetic core-shell nanoparticle) is transformed by the forward operator \(H\) (Gaussian blur, representing the PSF) into the measurement \(y\) (centre, blurred and noisy STEM image). Regularised inversion recovers an estimate \(\hat{x}\) (right) that is stable but retains some smoothing bias — an honest consequence of the ill-posed nature of the problem.
Why inversion is hard (I): non-uniqueness
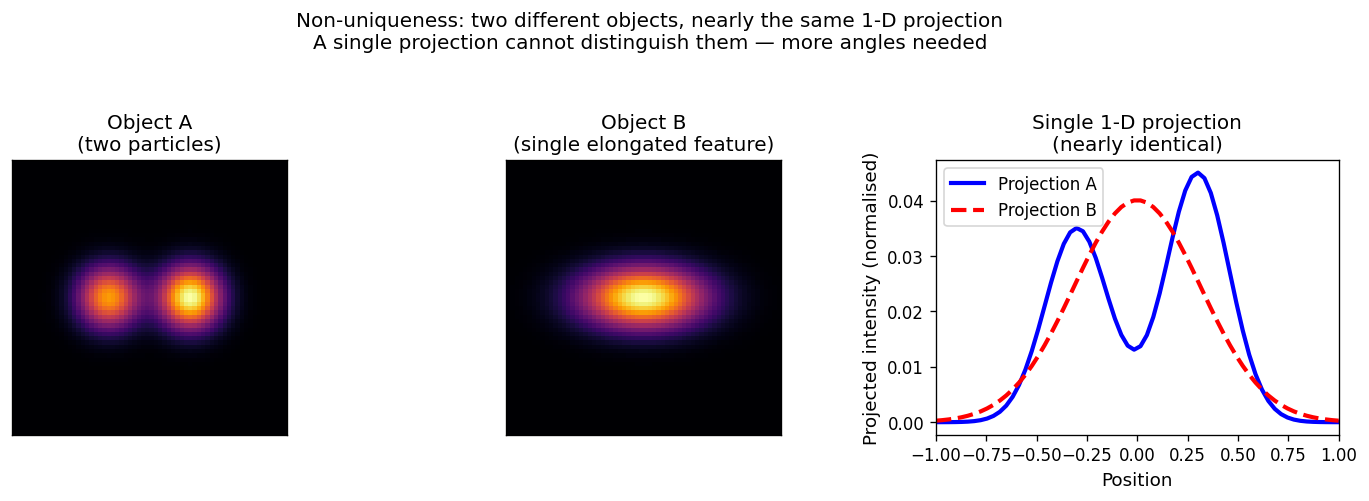
Non-uniqueness in projection imaging: Object A (two separated bright particles, left) and Object B (a single elongated feature, centre) produce nearly identical 1-D projections along the horizontal axis (right panel, blue and red curves are nearly superimposed). A single projection cannot distinguish them. This is the non-uniqueness problem: the same measurement \(y\) is consistent with many objects \(x\).
Why inversion is hard (II): ill-conditioning
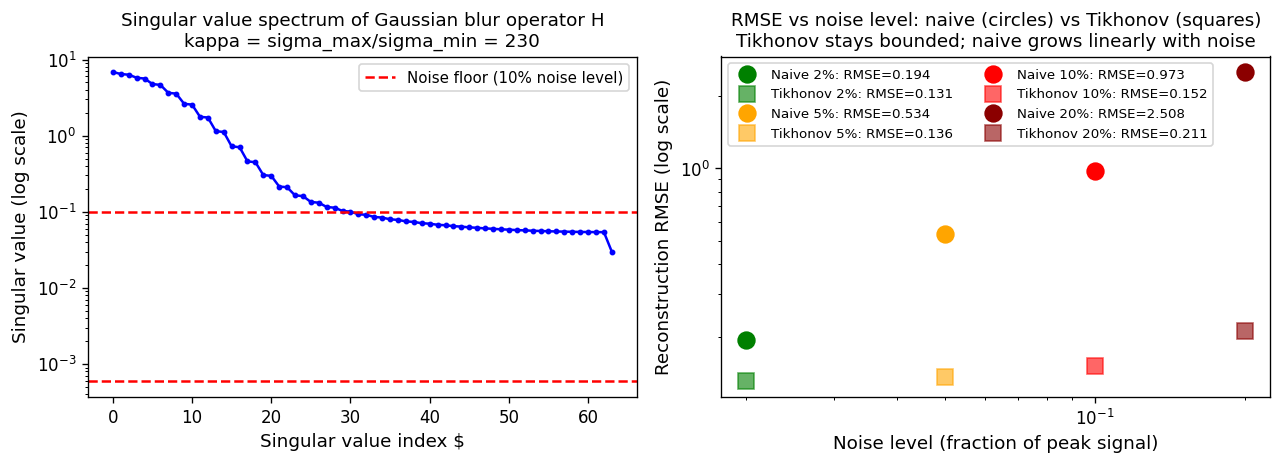
Singular value spectrum of the Gaussian-blur forward operator \(H\) used in this week’s notebook. The condition number \(\kappa = \sigma_\text{max}/\sigma_\text{min} \approx 230\) means a 1-% noise in the measurement can amplify to a 230-% error in the naive inverse. The red dashed line marks the noise floor: singular values below it are dominated by noise and the naive inverse is meaningless for those components. Left panel: the SVD spectrum; right panel: reconstruction RMSE vs noise level — circles (naive inverse) grow catastrophically; squares (Tikhonov) stay bounded.
Noise amplification in action
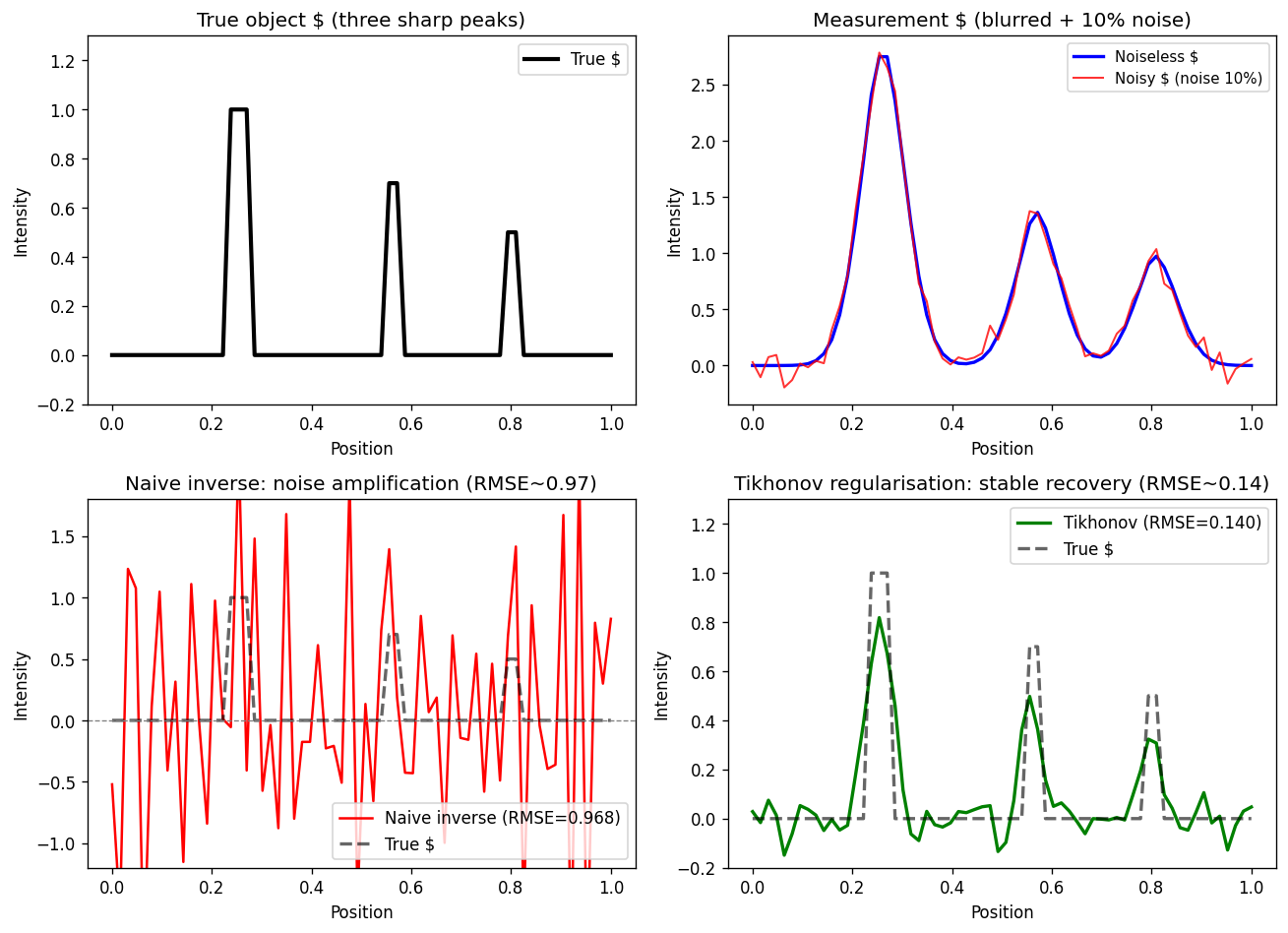
Top-left: the true 1-D object (three sharp peaks at positions 15, 35, 50). Top-right: the blurred+noisy measurement \(y = Hx + \epsilon\) (Gaussian blur, \(\sigma=3\) pixels, 10% noise). Bottom-left: naive least-squares inverse — RMSE ≈ 0.968, comparable to the signal amplitude, rendering the peaks indistinguishable from noise. Bottom-right: Tikhonov-regularised reconstruction (\(\lambda \approx 0.13\)) — RMSE ≈ 0.140, a 7× improvement. The peaks are correctly located but slightly broadened — the honest smoothing bias of regularisation.
Tikhonov vs TV: comparison on a step-function signal
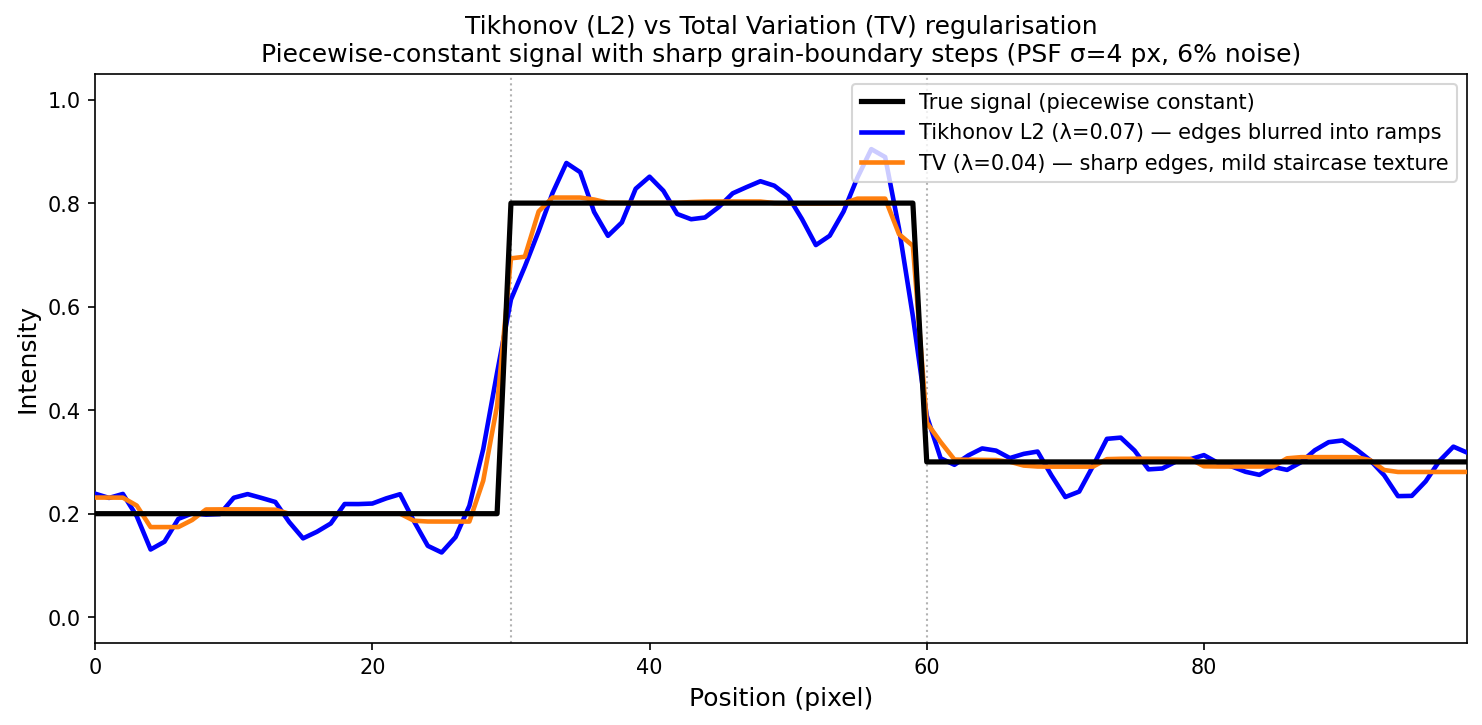
Comparison of L2 (Tikhonov) and total-variation (TV) regularisation on a 1-D piecewise-constant signal representing two grain-boundary steps (true values: 0.2 → 0.8 → 0.3; Gaussian PSF σ=4 px; 6% noise). Tikhonov (blue) blurs both transitions into broad ramps — the step positions are approximately correct but the edges are smoothed over several pixels. TV (orange) preserves the sharp step edges: the transitions are close to vertical, with only mild staircase texture in the flat regions. True signal in black (dashed vertical lines mark the step positions). TV RMSE ≈ 0.032; Tikhonov RMSE ≈ 0.057. Neither is perfect — the choice of regulariser determines which artefact appears.
Sensor fusion: HAADF + EELS as a regularised inverse problem

Three-panel comparison of a synthetic core-shell nanoparticle reconstruction. Left: HAADF image (high SNR, Z-contrast proportional to \(Z^{1.7}\), no chemical specificity). Centre: EELS elemental map (chemically specific but very noisy at low dose — 25% relative noise). Right: TV-regularised fusion result combining both signals, with objective \(\arg\min_{x \geq 0} \|b_H - Ax^\gamma\|^2 + \lambda_1 \|b_E - x\|^2 + \lambda_2\,\text{TV}(x)\) Pennycook, Stephen J. et al., (2012), doi:10.1007/978-1-4419-7200-2. The fused map recovers the core and shell structure with 5–10× dose reduction compared to a high-SNR EELS-only acquisition.
Choosing λ: the bias–variance trade-off
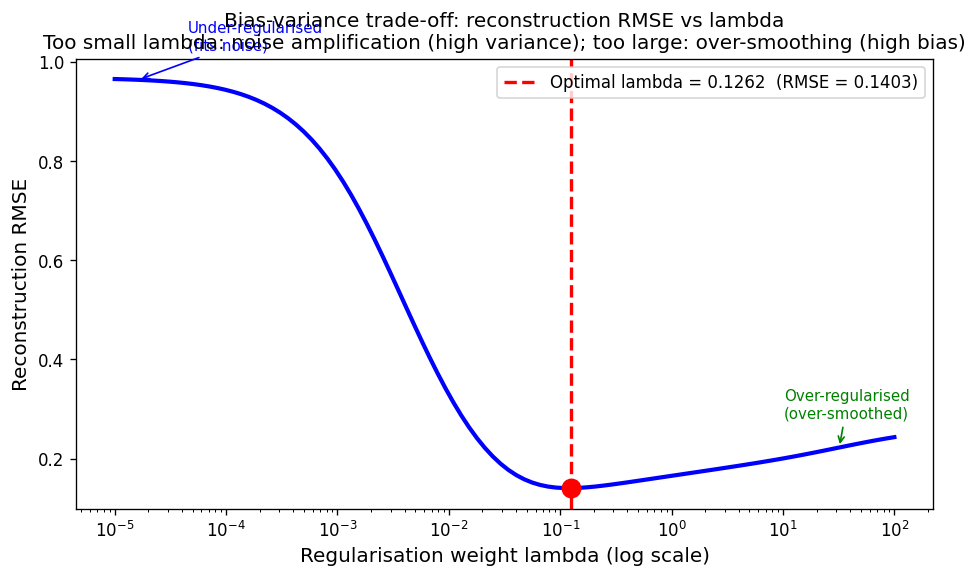
Reconstruction RMSE as a function of regularisation weight \(\lambda\) for the 1-D deblurring notebook (SEED=42, N=64, \(\sigma_\text{PSF}=3\), noise=10%). The curve has a clear U-shape: at \(\lambda=10^{-5}\) RMSE≈0.966 (under-regularised — fits noise); at \(\lambda=100\) RMSE≈0.243 (over-regularised — over-smoothed); minimum at \(\lambda^* \approx 0.126\) (red vertical line) with RMSE≈0.140. The optimal \(\lambda\) balances data fit against prior smoothness. This U-shaped RMSE curve is a genuine executed notebook result — reproduce it to verify your implementation.
Choosing \(\lambda\): the L-curve method
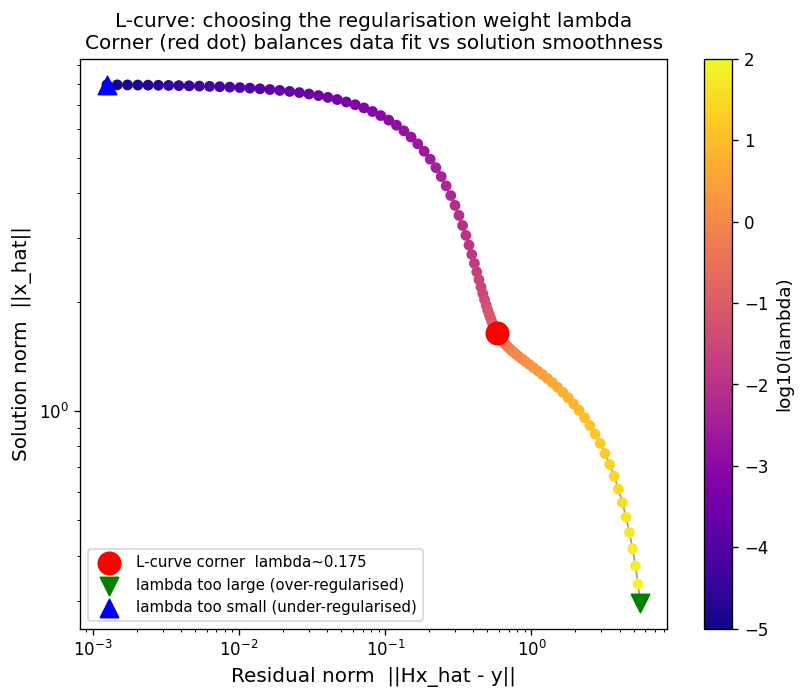
L-curve for the 1-D deblurring problem: horizontal axis = residual norm \(\|Hx̂ - y\|\) (data fit), vertical axis = solution norm \(\|x̂\|\) (solution complexity), both in log scale. Each point on the curve corresponds to a different \(\lambda\) (colour-mapped from blue = large \(\lambda\) to yellow = small \(\lambda\)). The curve has a characteristic L-shape. The corner (red dot, \(\lambda \approx 0.175\)) is the point of maximum curvature in log–log space — a data-only estimate of the optimal balance between data fit and solution norm. The L-curve corner (\(\lambda \approx 0.175\)) lies slightly above the true RMSE-optimal \(\lambda \approx 0.126\) (RMSE \(\approx 0.140\)): the L-curve is a heuristic, not an exact optimum. Blue triangle (bottom-right): small \(\lambda\) = under-regularised, very tight data fit but enormous solution norm. Green triangle (top-left): large \(\lambda\) = over-regularised, very small solution norm but poor data fit.
Electron tomography: the missing wedge problem
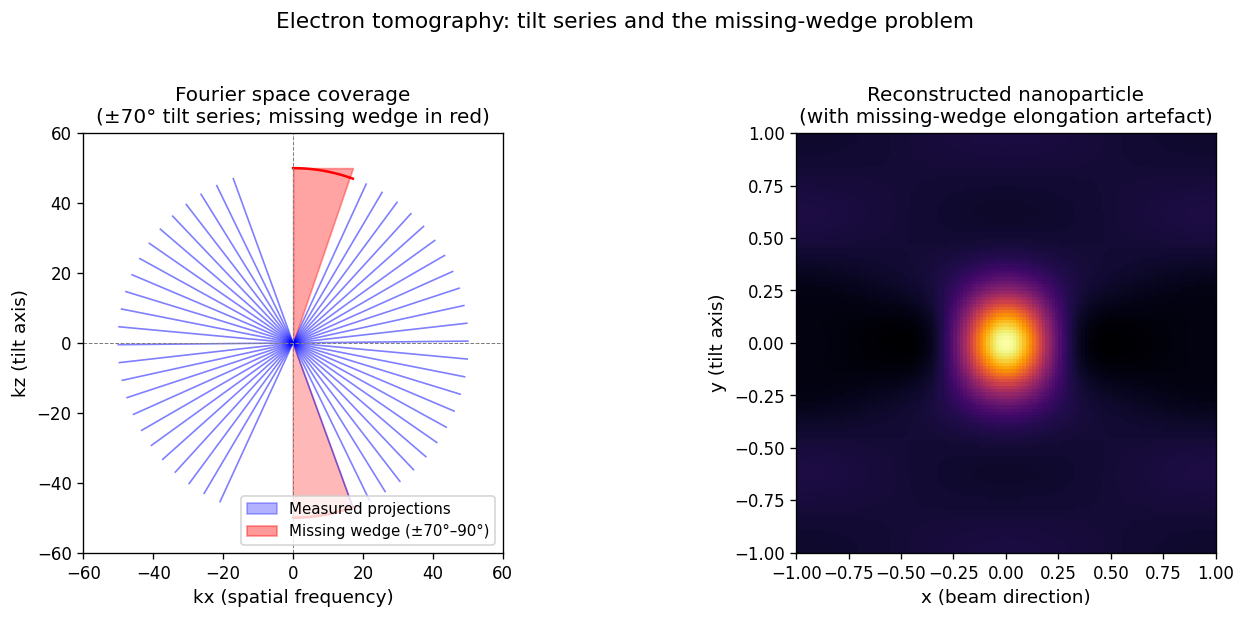
Fourier-space coverage for a ±70° tilt series (left): each blue line represents the 1-D slice measured by one projection. The red shaded region is the “missing wedge” — the angular sector from ±70° to ±90° that cannot be reached without mechanically shadowing the specimen holder. Right: reconstruction of a spherical nanoparticle with the missing-wedge artefact. The particle appears elongated in the beam direction (vertical) because the Fourier frequencies that encode vertical extent were never measured. This anisotropic elongation is not real structure — it is a missing-wedge artefact. Regular compressed-sensing methods Leary, Rowan et al., (2013), doi:10.1016/j.ultramic.2013.03.019 reduce but do not eliminate this artefact.
HAADF + EELS fusion: the reconstruction result
Sensor fusion result for a synthetic core-shell nanoparticle. Left: HAADF image (high SNR, Z-contrast — structure visible, no chemistry). Centre: EELS elemental map at low dose (chemically specific but signal buried in 25%-relative noise). Right: TV-regularised fusion, minimising \(\|b_H - Ax^\gamma\|^2 + \lambda_1\|b_E - x\|^2 + \lambda_2\,\text{TV}(x)\). The core (bright) and shell (dim ring) are clearly distinguished in the fused map — the HAADF structural prior guided noise suppression without requiring the full EELS dose. Honest caveat: the reconstruction sharpens edges but may slightly over-estimate core-shell contrast (TV over-sharpening artefact) at high \(\lambda_2\).
What good reconstruction looks like — and its honest limits
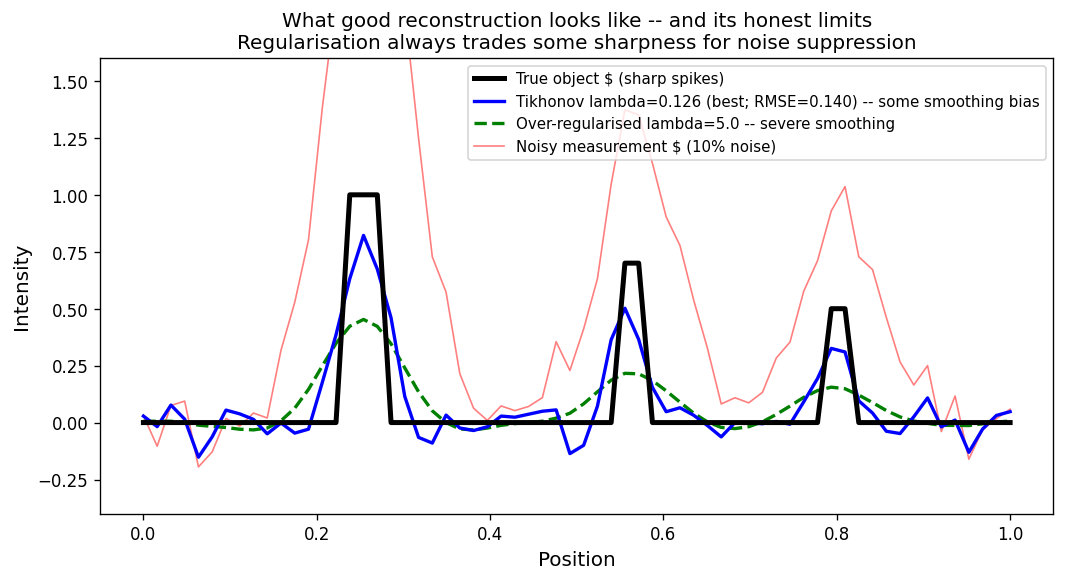
Reconstruction quality comparison for the 1-D deblurring notebook (SEED=42, noise=10%). Black curve: true object (three sharp spikes). Red curve: noisy measurement \(y\). Blue curve: Tikhonov at near-optimal \(\lambda \approx 0.126\) (RMSE ≈ 0.140) — peaks correctly located, heights slightly underestimated (regularisation bias). Dashed green curve: over-regularised Tikhonov (\(\lambda = 5.0\), RMSE ≈ 0.189) — peaks smeared into a broad hump. The best achievable reconstruction is not “perfect” — regularisation always trades some sharpness for stability. The naive inverse (RMSE ≈ 0.968, not shown) is dominated by noise and useless.