Machine Learning in Materials Processing & Characterization
Unit 4: From Classical Metrics to Learned Representations




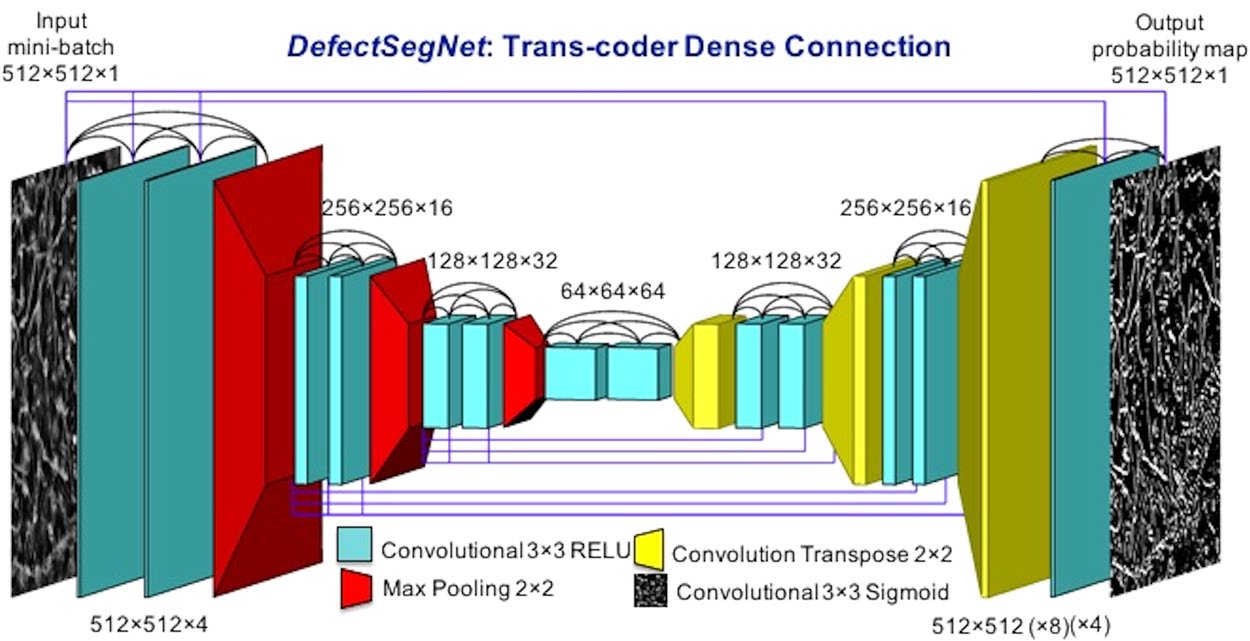
08. Hero Result — Steel Phase Classification
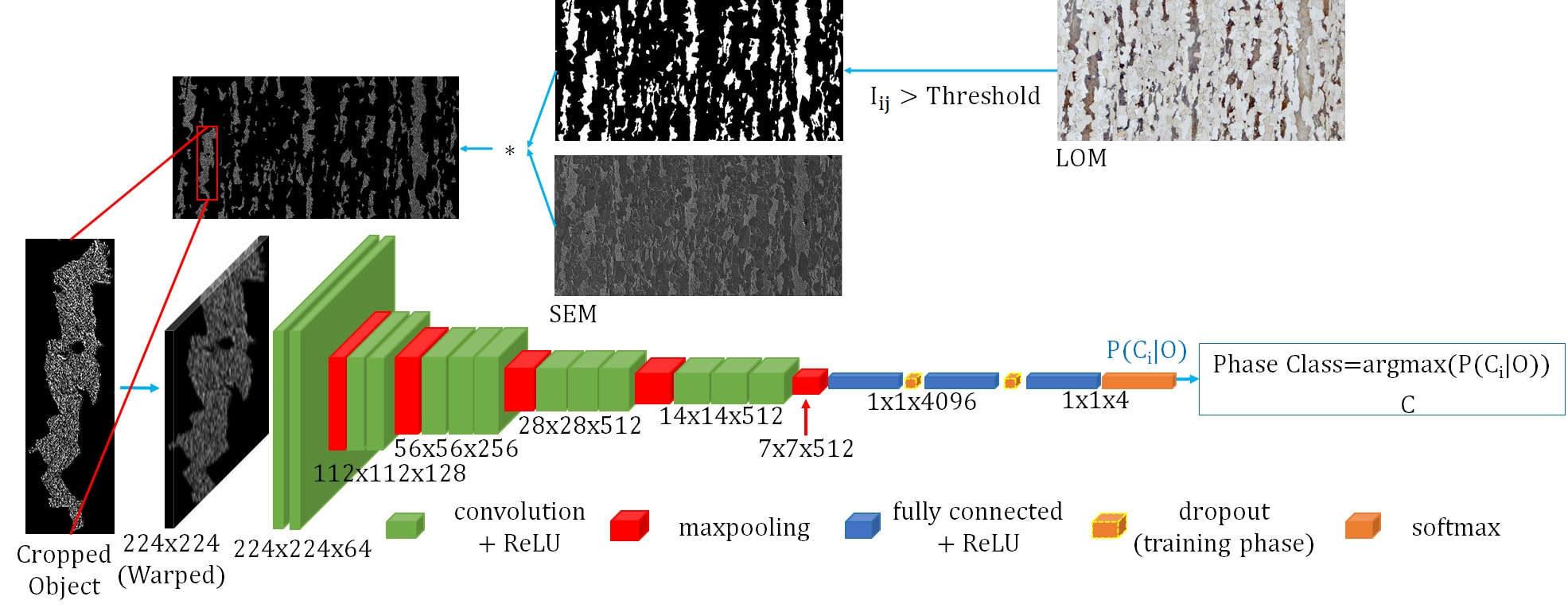
Azimi et al., Sci. Rep. 2018 Azimi, Seyed Majid et al., (2018), doi:10.1038/s41598-018-20037-5
- Dual-phase steel constituents on SEM micrographs (martensite, bainite, pearlite, …).
- Fully Convolutional Net + superpixel max-voting.
- Prior SOTA: 48.9% → FCNN: 93.94%.
- Same images. No new physics — representation change alone.
Note
The 45-point jump is the headline of this whole unit.
09. Where Hand-Crafted Hits a Wall — A Wider View

Holm et al., MMTA 2020 — review Holm, Elizabeth A. et al., (2020), doi:10.1007/s11661-020-06008-4
- Surveys CV/ML across classification, semantic segmentation, object detection, instance segmentation.
- Pattern: where labels exist, learned representations match or beat hand-crafted features.
- The bottleneck has moved: from “which descriptor?” to “which labels and which split?”
20. Case 1 — Steel Phase Classification (Azimi 2018)

- Task. Classify constituents in dual-phase steel SEM micrographs.
- Method. Fully Convolutional Net + max-voting on superpixels.
- Data. Thousands of SEM tiles, expert-labelled.
- Result. 93.94% vs prior SOTA 48.9%.
- Lesson. Representation change alone unlocks the 45-pt jump.
21. Case 2 — UHCS Microstructure Manifold (DeCost & Holm)

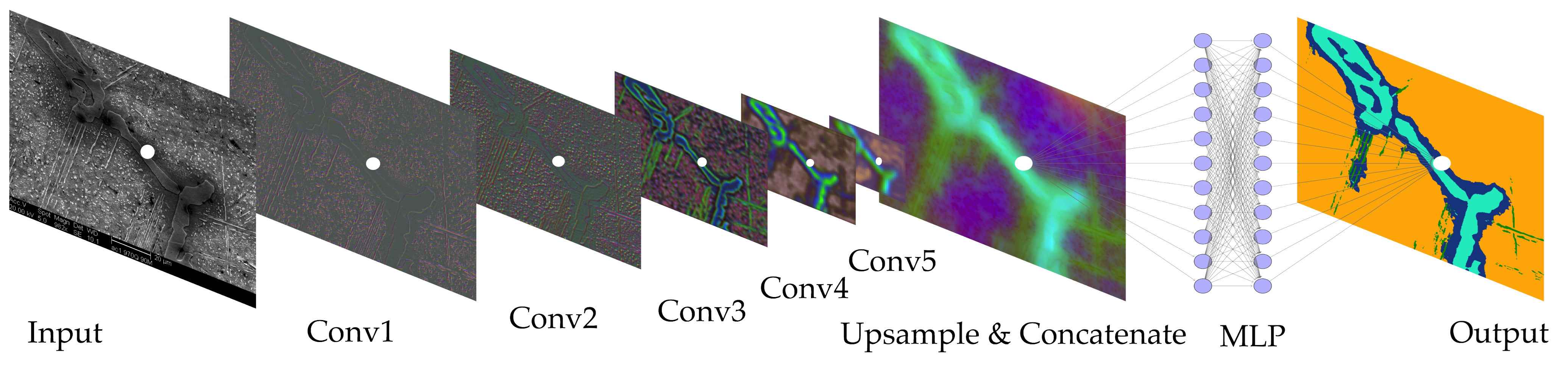
- Dataset. 961 public UHCS micrographs (
materialsdata.nist.gov). - Lesson. Pretrained CNN features cluster phase classes without labels — a transfer-learning preview (Unit 6) and the basis for Exercise 1.
22. Case 3 — U-Net for EBSD Phase Segmentation
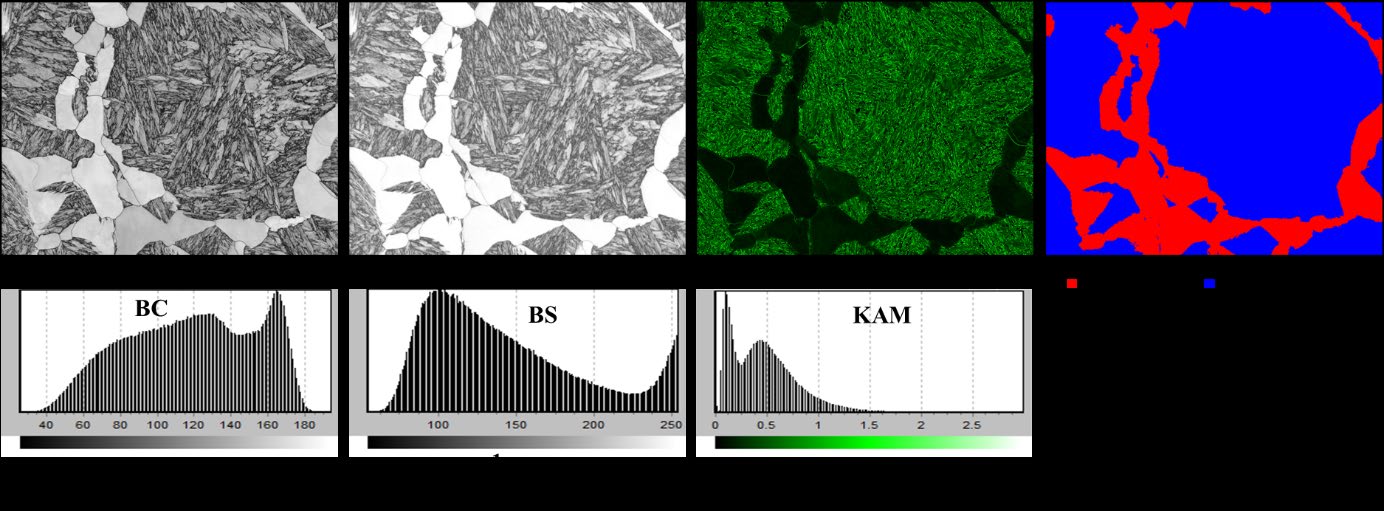
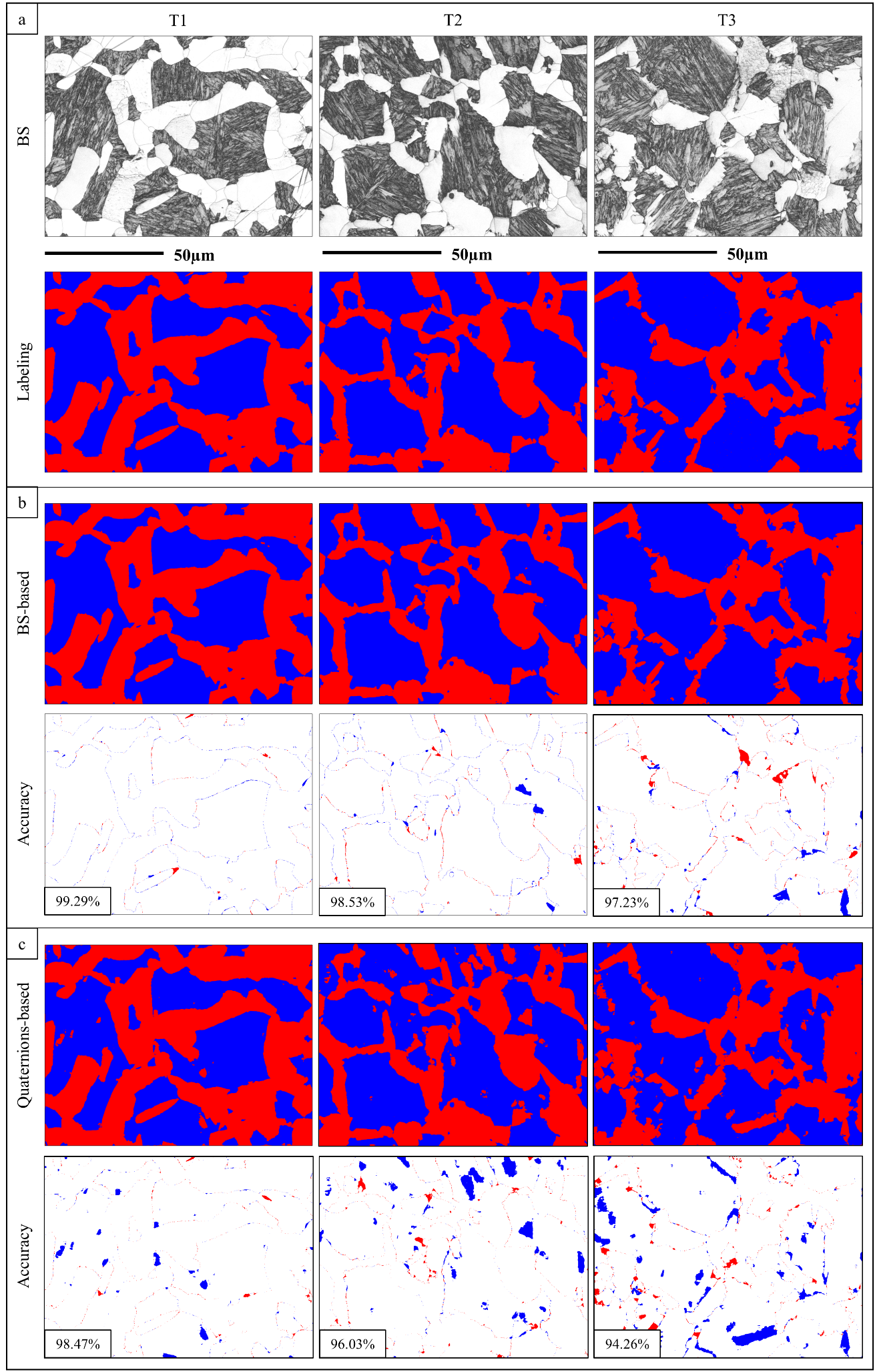
- Task. Pixel-level martensite / ferrite-bainite segmentation across three tempering conditions.
- Lesson. A standard U-Net on a single grayscale BS channel can reach the EBSD-quaternion baseline if augmentation is honest.
23. Case 4 — Complex Microstructure Inference (Durmaz et al. 2021)

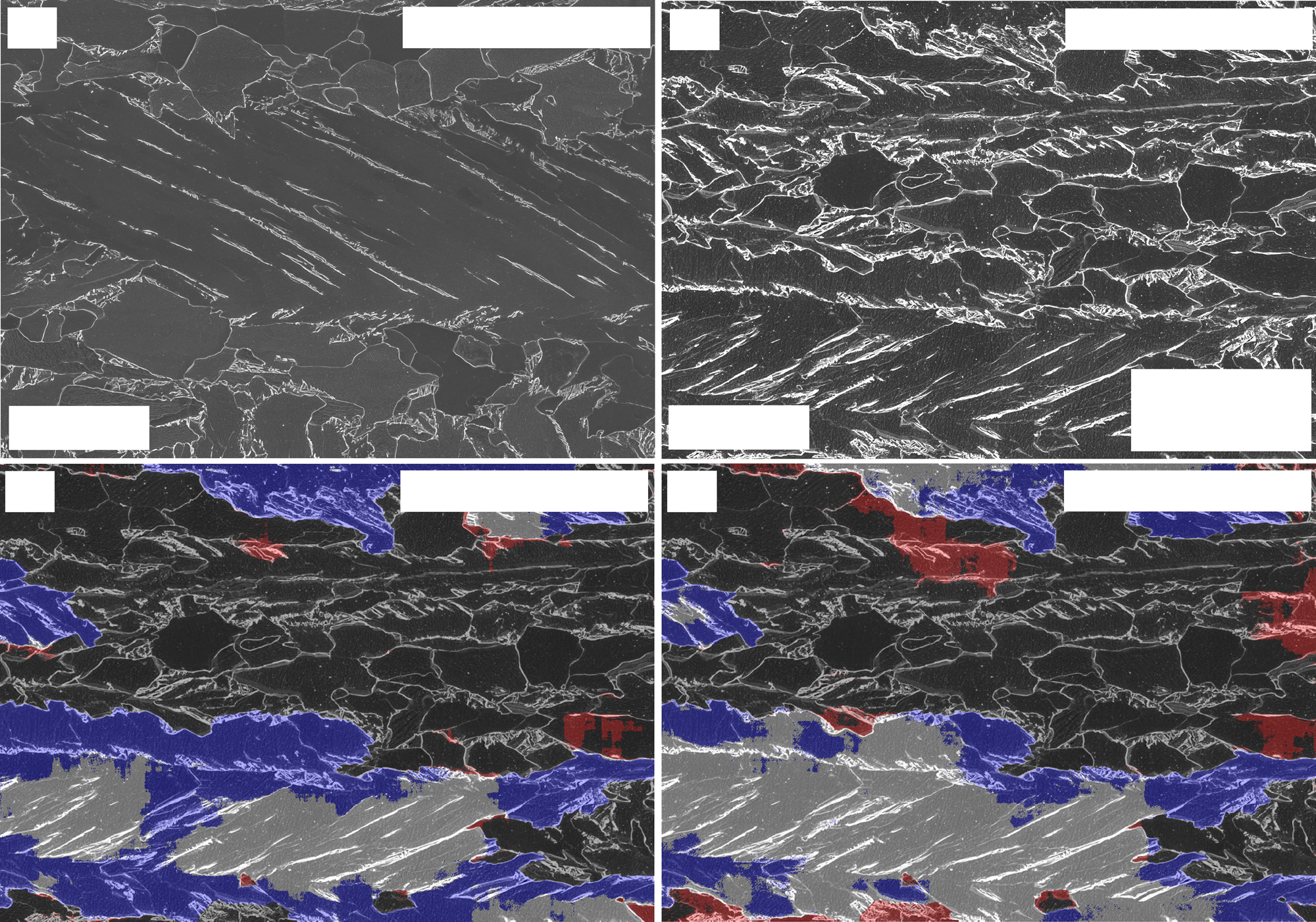
- Method. U-Net (semantic) + Mask R-CNN (instance) trained on EBSD-derived ground truth, deployed on LOM/SEM only at inference.
- Lesson. EBSD-grade labels at training time → optical-microscopy throughput at inference time.
24. Case 5 — TEM Dislocation Segmentation (Govind et al. 2024)
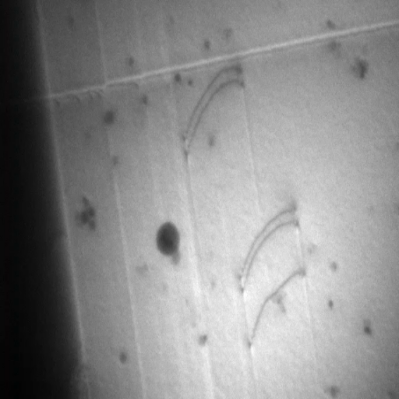
- Task. Instance segmentation of dislocations in TEM.
- Method. YOLO-style + U-Net trained on simulated dislocation images, evaluated on real experiments.
- Lesson. Simulation-augmented training bypasses the “never enough labels” bottleneck — standard wherever physics simulators are mature.
25. Case 6 — STEM Defects in Irradiated Steels (Roberts 2019)
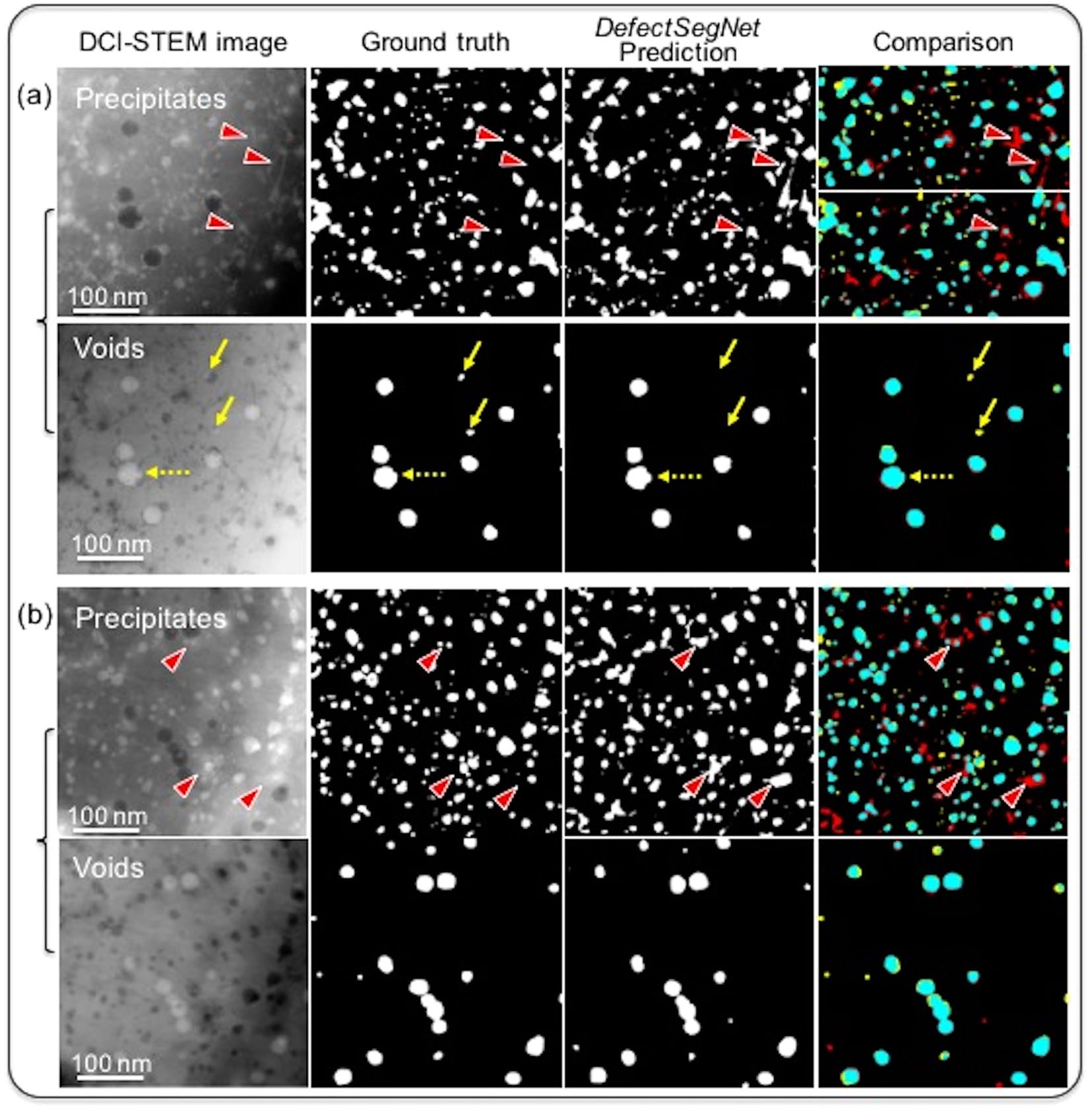
- Task. Semantic segmentation of voids, dislocation loops, precipitates in irradiated steels.
- Result. ~85% IoU — matches inter-annotator variability.
- Lesson. Once you hit the annotator floor, more model capacity buys nothing.
28. Case 9 — Lee/Park et al. 2020 — XRD Phase ID with 1-D CNN
- Task. Phase ID in multi-phase inorganic mixtures from XRD.
- Train on simulation, test on real. ~\(10^5\) patterns from ICSD with augmentation for strain, texture, peak broadening.
- Result. ~100% phase ID; ~86% three-phase quantification on real experiments.
- Lesson. CNN \(\neq\) image network — convolution applies wherever there is locality (peak shape along \(2\theta\)).
29. Case 10 — 3-D U-Net for Li-ion Electrode Tomography


- Method. 3-D U-Net trained partly on synthetic electrodes with known voxel-level ground truth.
- Lesson. Carbon-binder vs pore has near-zero contrast — thresholding fails; simulation-augmented CNN succeeds.
33. Case 12 — Thermographic Porosity Prediction in LPBF
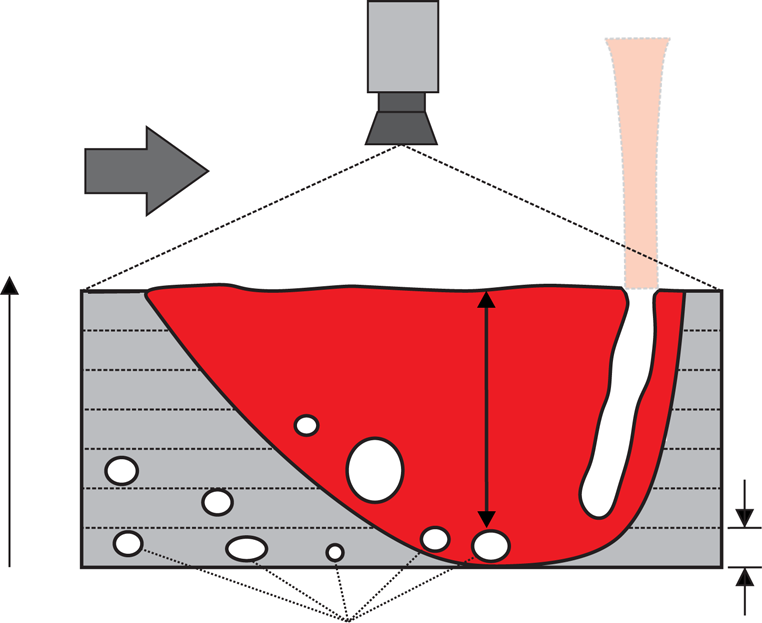

- Method. Multi-layer thermographic feature stack → supervised CNN classifier; CT ground truth.
- Result. Accuracy ~0.96, F1 ~0.86 for keyhole porosity in small sub-volumes.
- Lesson. Thermal history is a proxy for porosity — CNNs decode it densely, below the resolution of point pyrometers.
35. Case 14 — Radiographic Weld Inspection (CNN-ViT)
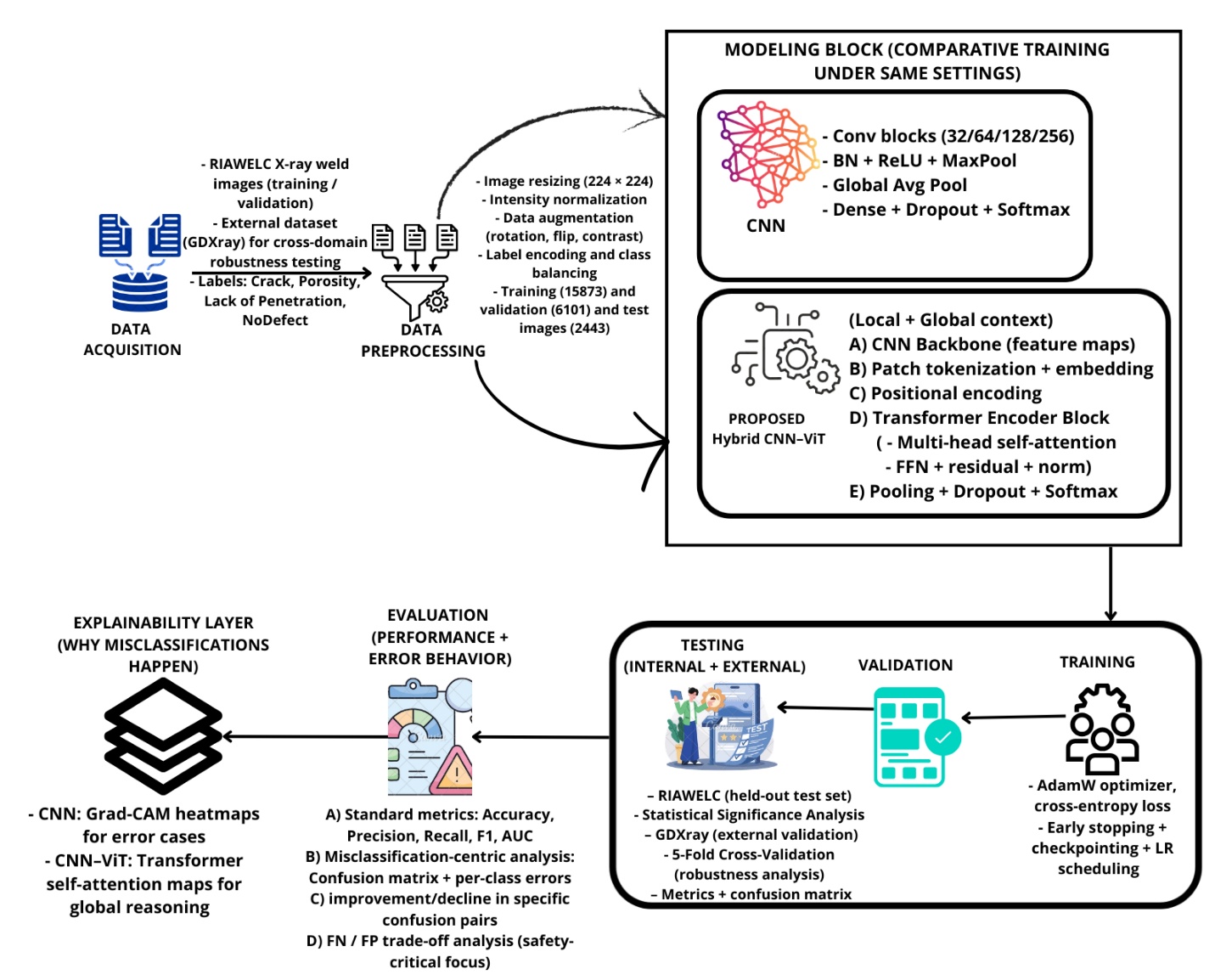

- Result. CNN-ViT 98.56% vs CNN baseline 97.90%; ~31% reduction in misclassification rate.
- Lesson. Hybrid CNN + ViT = local CNN features + global ViT context, with auditable Grad-CAM evidence per decision — a regulatory-grade design.
36. Case 15 — CNN as Crystal-Plasticity Surrogate
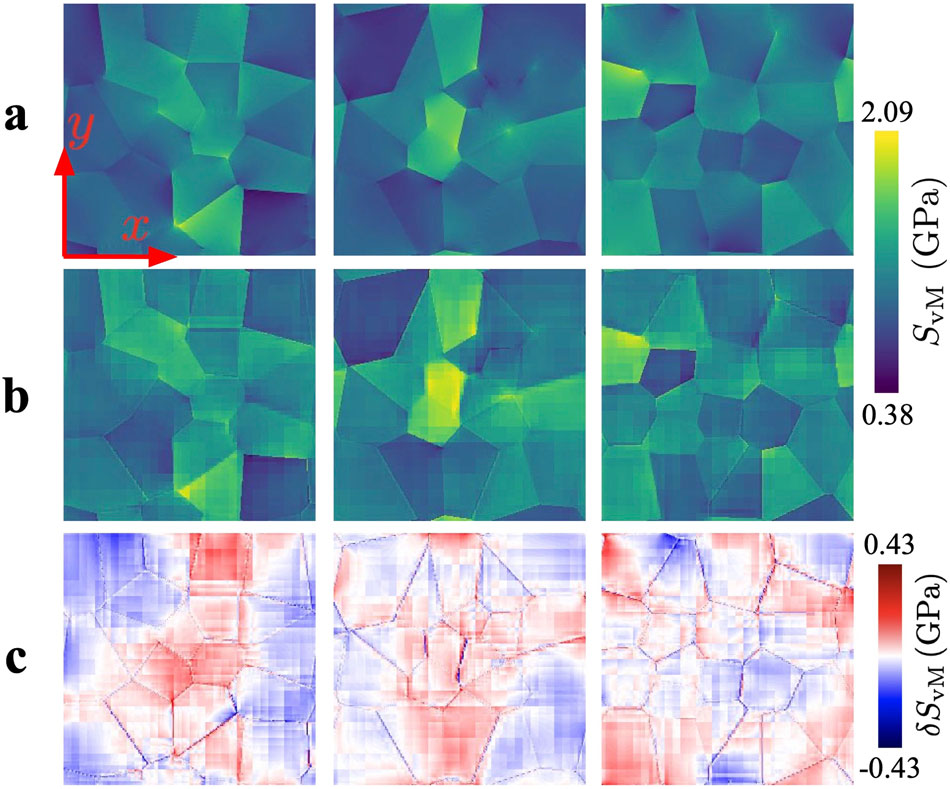
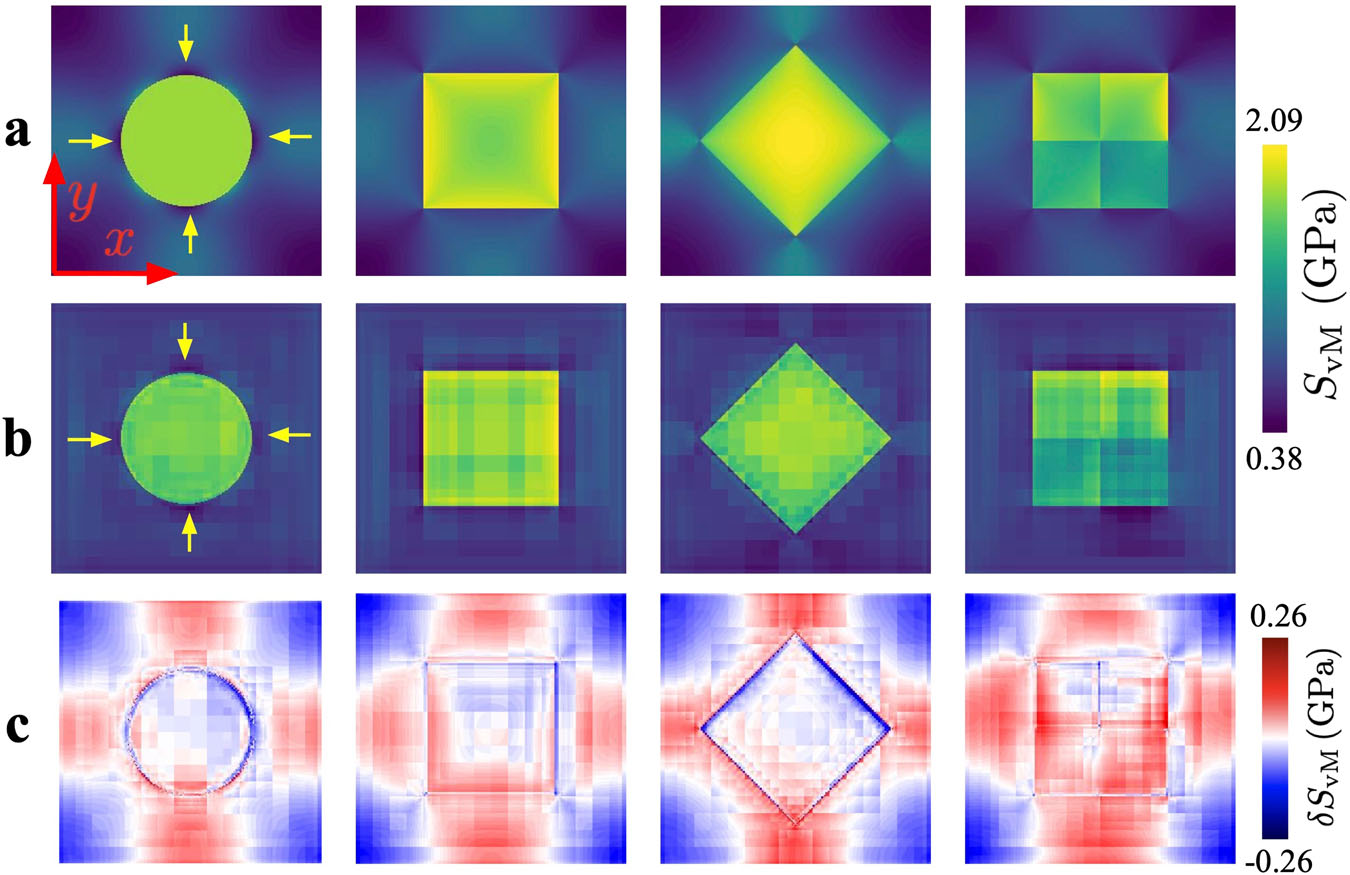
- Method. 3-D CNN trained on CPFEM ground truth; orders of magnitude faster at inference.
- Lesson. CNN now a viable surrogate inside design loops — replaces FE inner solves wherever speed matters more than the last fraction of a percent.
40. CNN vs 2-Point Statistics — When CNN Wins
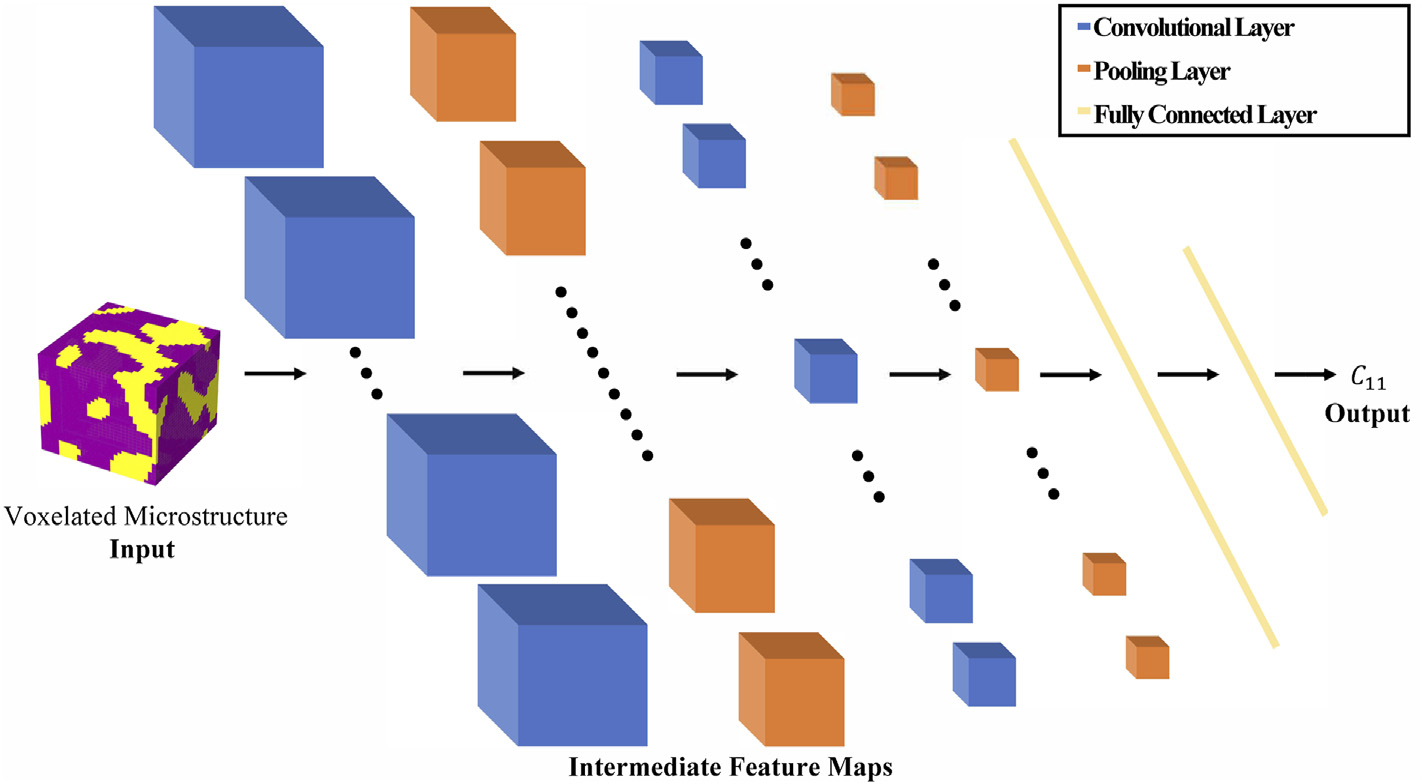
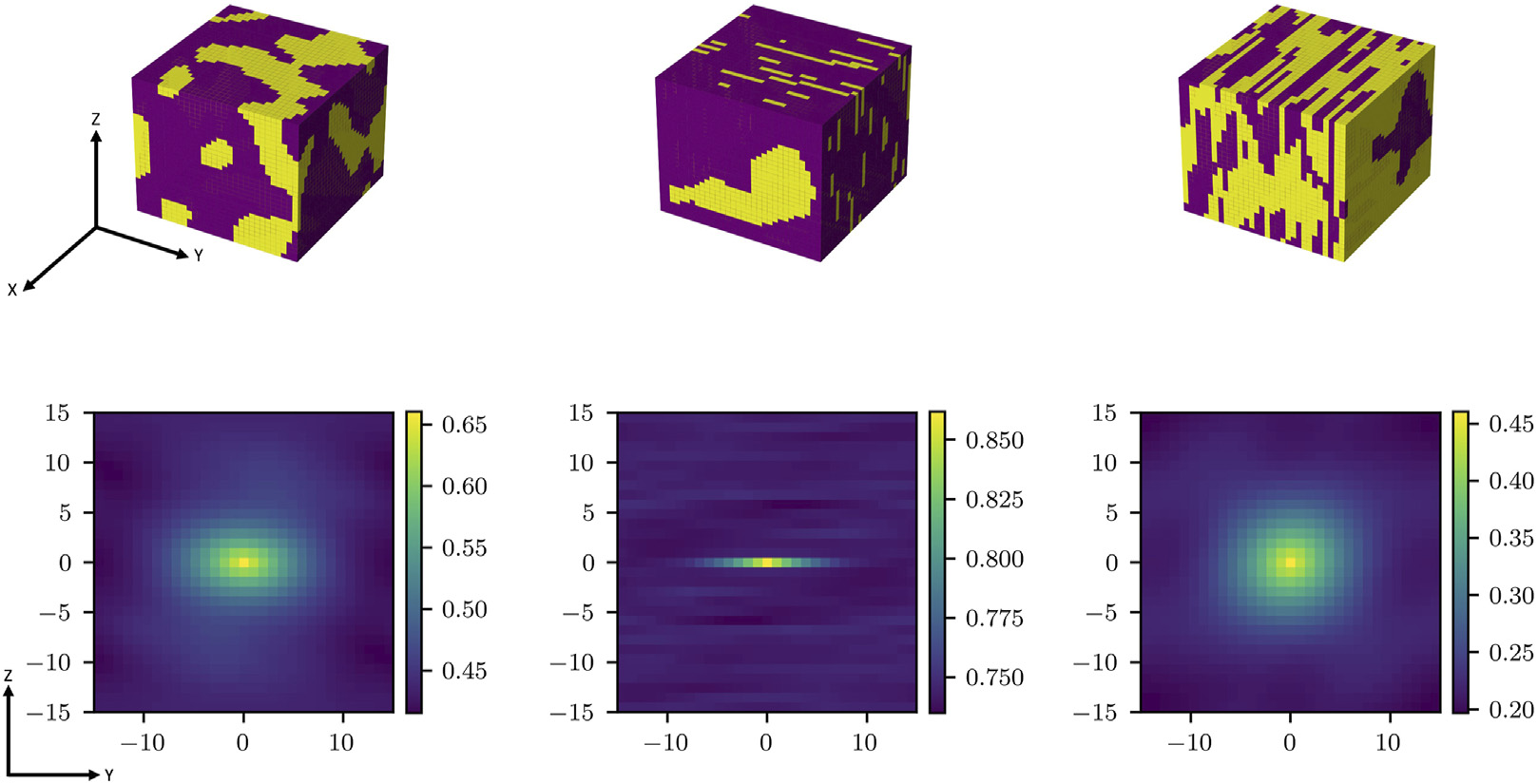
CNN wins when
- Spatial features are task-specific.
- \(N \gtrsim 10^3\) specimens or simulation augmentation available.
\(S_2\) / MKS still competitive when
- \(N\) small; simulation dominates.
- Hybrid (CNN ⊕ \(S_2\)): \(R^2 > 0.96\) on stiffness regression Mann, Andrew et al., (2022), doi:10.3389/fmats.2022.851085.