%%{init: {'theme': 'dark', 'themeVariables': { 'darkMode': true, 'background': 'transparent' }}}%%
graph LR
A["Image"] --> B["Flatten<br>(40k-D)"]
B --> C["z-score"]
C --> D["PCA<br>(50-D)"]
D --> E["K-means / GMM"]
style E fill:#e7ad52,color:#000
Machine Learning in Materials Processing & Characterization
Unit 5: Unsupervised Methods for Materials — Clustering and Autoencoders




11. ESTM — Picking K Without a Clean Elbow (2/4)
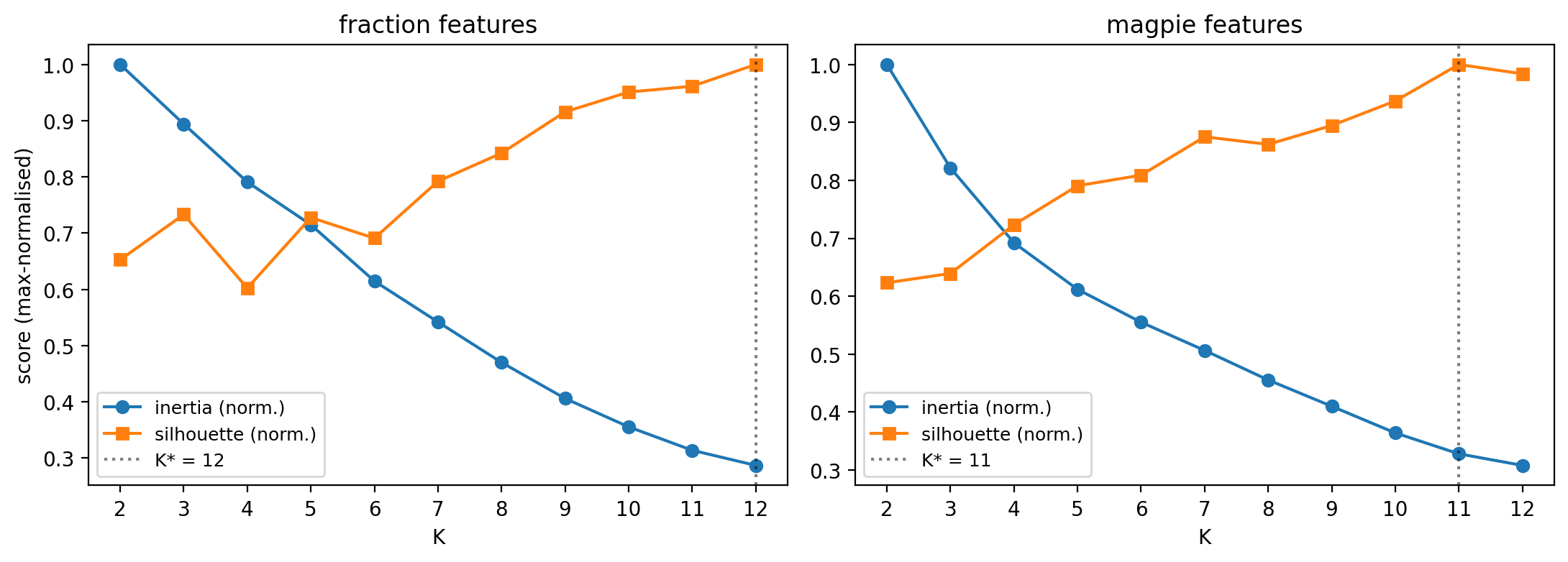
When silhouette is monotonic and inertia has no elbow, the data lacks discrete groups in this representation. Pick \(K\) honestly, then validate clusters by what they contain (next two slides).
What the diagnostics say
- Silhouette never peaks — it just keeps climbing as \(K\) grows.
- Inertia falls smoothly, no clean elbow either.
- Argmax silhouette: \(K^* = 12\) (fractions), \(K^* = 11\) (Magpie).
- These are working hypotheses, not “the answer”.
Two more numbers worth saying aloud
- Fraction-feature PCA-10 captures 29.5 % of variance.
- Magpie-feature PCA-10 captures 77.6 %.
- First quantitative hint that featurization changes the geometry of the data, not just its labels.
11a. ESTM — Featurization Shapes the Cluster Map (3/4)
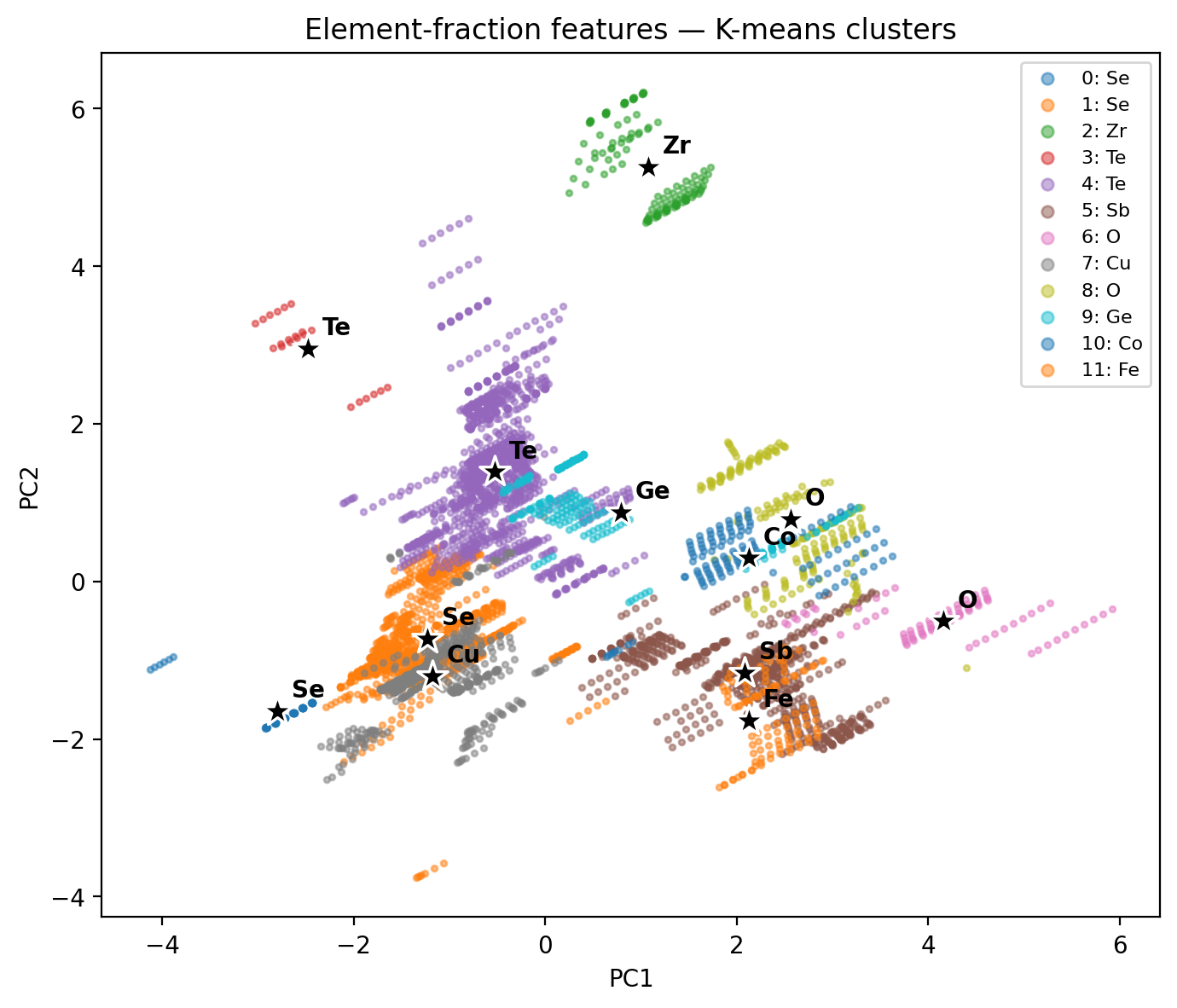
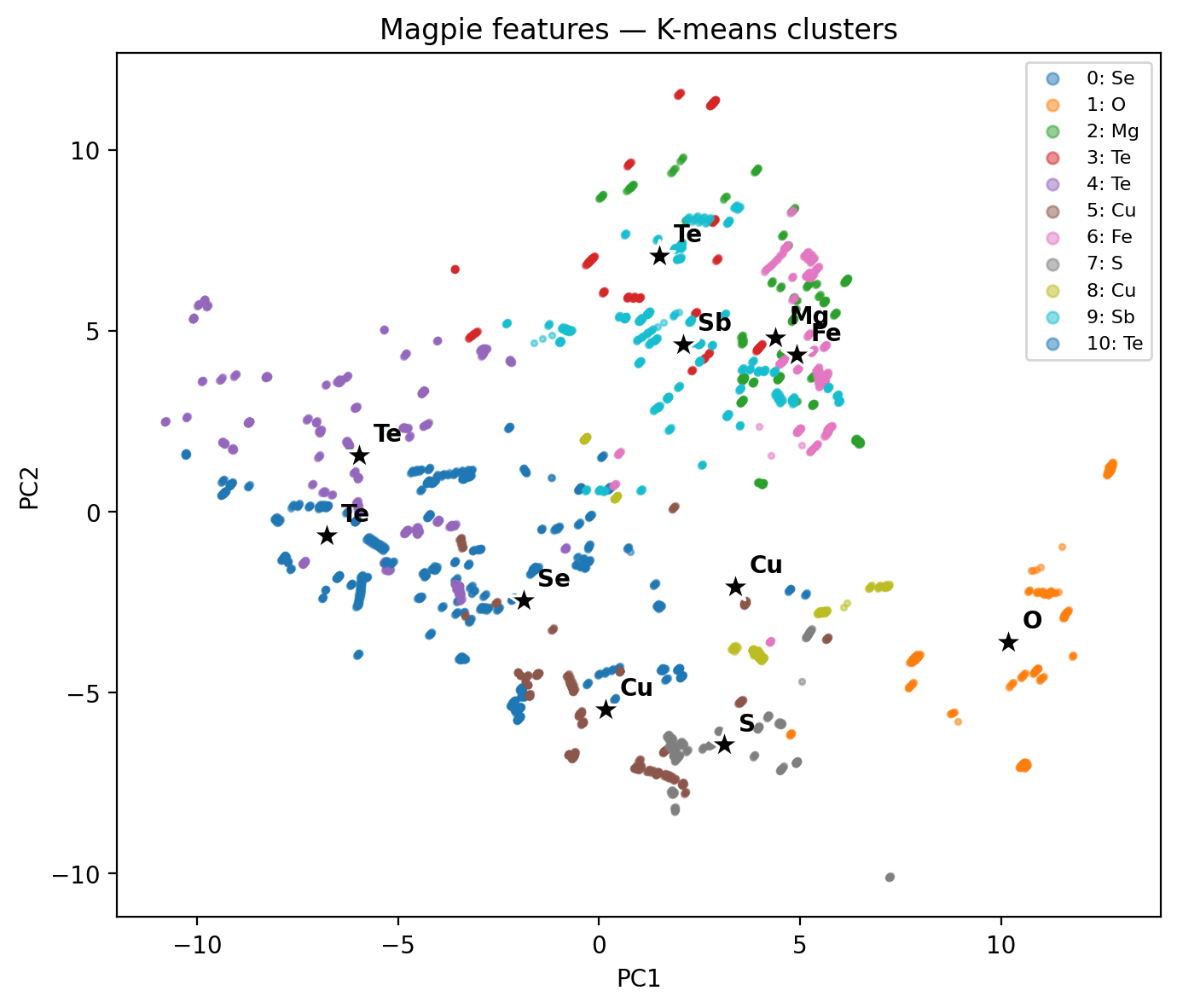
Same 5 205 compounds, same K-means, two different feature maps → two different cluster geometries. Featurization design has bigger impact than the choice of \(K\).
11b. ESTM — Clusters Concentrate ZT in Specific T Windows (4/4)
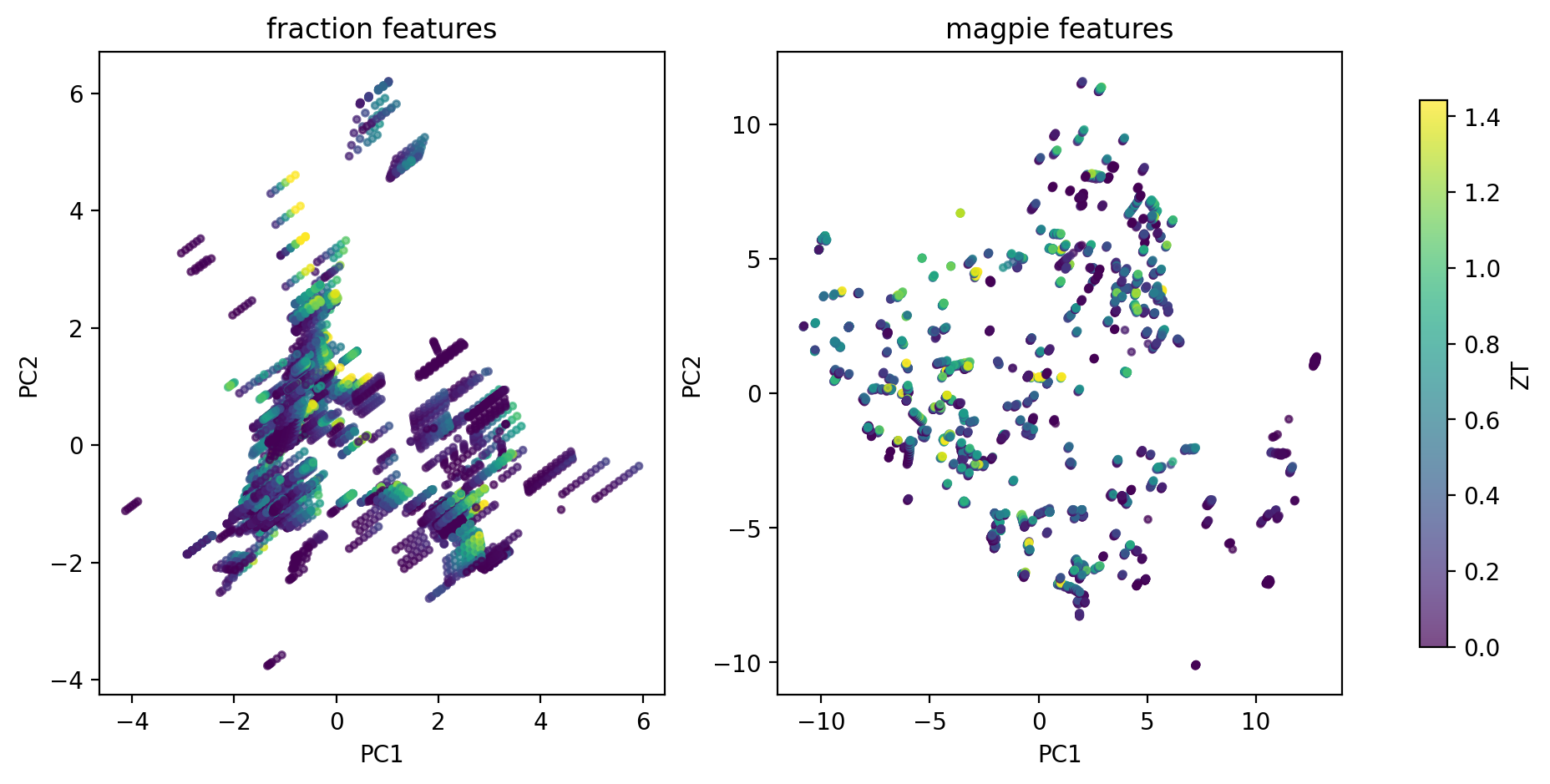
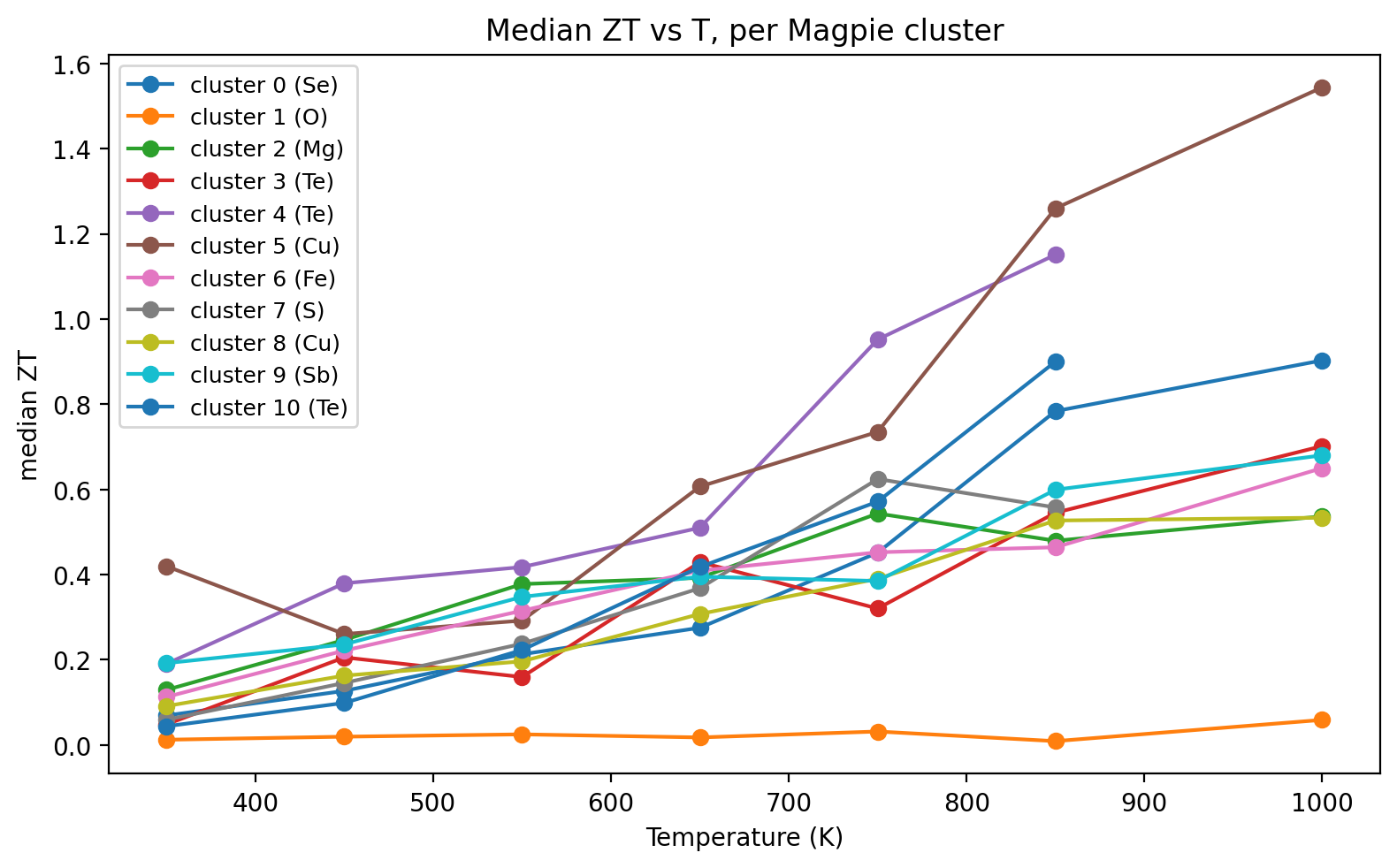
Discovery signal
- A handful of Magpie clusters carry >2× the median ZT of the full dataset.
- Cluster T-profiles separate low-\(T\) chalcogenides from high-\(T\) skutterudites / half-Heuslers.
- Cluster \(\equiv\) operating window: a shortlist for synthesis in a target \(T\) range.
- One step short of Na and Chang (2022)’s SIMD descriptor, which learns the cluster-aware projection — preview of Unit 9 latent spaces.
19. Case Study — NEU-DET Steel Defects (1/3)
Dataset
- NEU-DET (Song and Yan 2013): 1800 grayscale 200×200 micrographs of hot-rolled steel surfaces.
- Six defect classes, 300 frames each: crazing, inclusion, patches, pitted_surface, rolled-in_scale, scratches.
- Labels are used only for evaluation — clustering sees pixels.
Two feature pipelines, two algorithms
- A raw pixels (40 000-D) → z-score → PCA(50).
- B frozen ResNet18 (ImageNet) → 512-D embedding → z-score.
- Run both K-means and GMM with \(K = 6\) on each feature set.
- Score against ground truth with ARI and NMI; inspect with t-SNE and contingency tables.
- Notebook:
notebooks/MLPC/week05_clustering_neu_det.qmd.

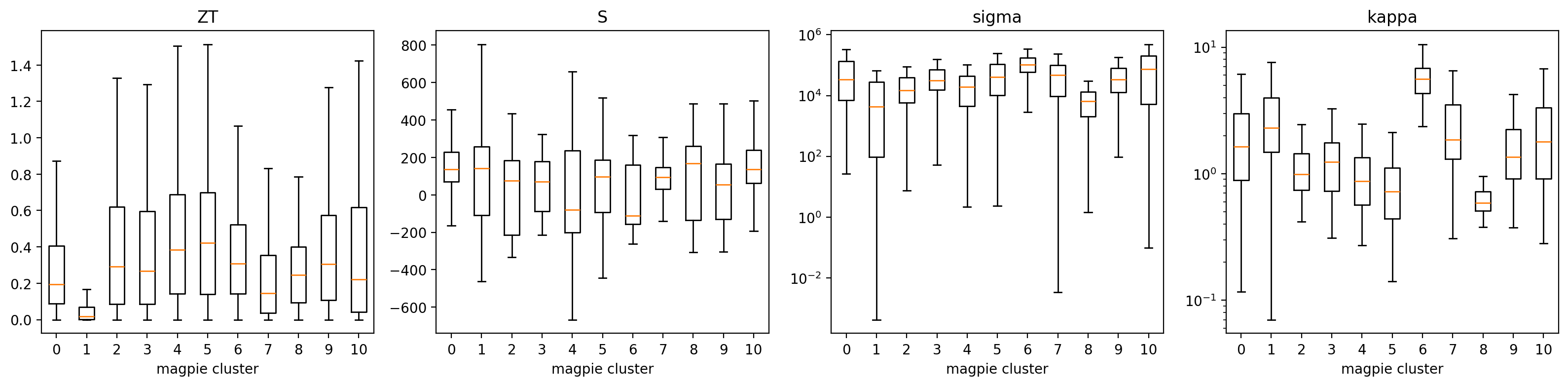
21. Case Study — NEU-DET Results (3/3)
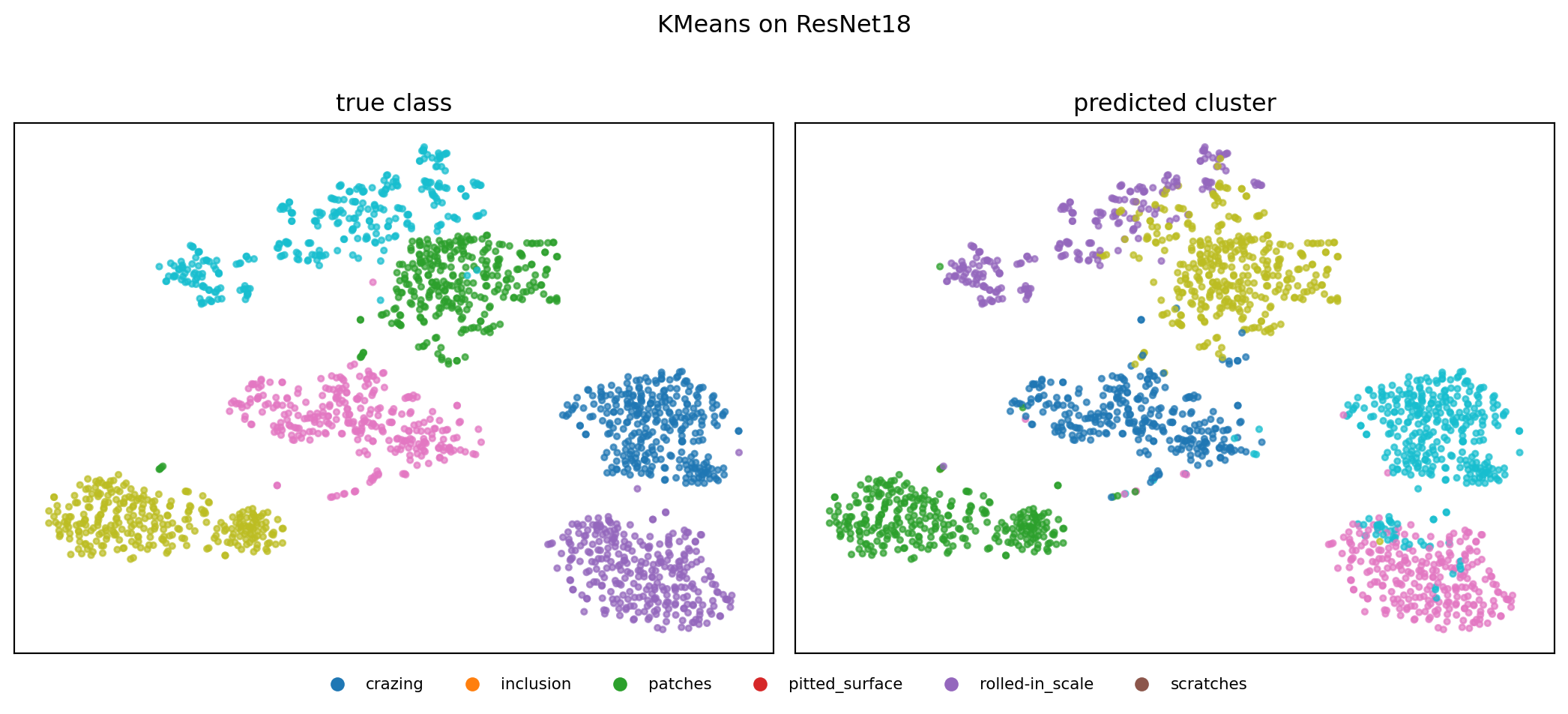
What the numbers say
- Representation beats algorithm. Swapping raw pixels for ResNet18 embeddings raises ARI from 0.12 → 0.81 for K-means — a \(\sim 7\times\) jump with the same clustering code.
- GMM ≈ K-means once features are good. On ResNet18, GMM (ARI 0.83) is within noise of K-means (0.81). The features carry the signal; soft vs hard assignment is a second-order knob.
- Some classes are easy, others not.
The encoder did the work. We will revisit this on slide 23 (caveat); domain-pretrained encoders are picked up again in Unit 9 (contrastive learning).
26. K-means Phase Maps — Duplex Stainless Steel by Low-Loss EELS
Setup (Castro Riglos et al. 2024)
- Industrial 2205 duplex stainless steel (aged), STEM low-loss EELS.
- Spectrum image: \(100 \times 100\) pixels over \(\sim 18 \times 18\) µm, 10–35 eV plasmon window, 0.1 eV/pixel, 0.05 s dwell.
What each cluster is
- Centroid \(\mu_k\) is a prototypical low-loss EELS spectrum — physically interpretable (panel d).
- Cluster IDs reshaped to a phase map (panel c).
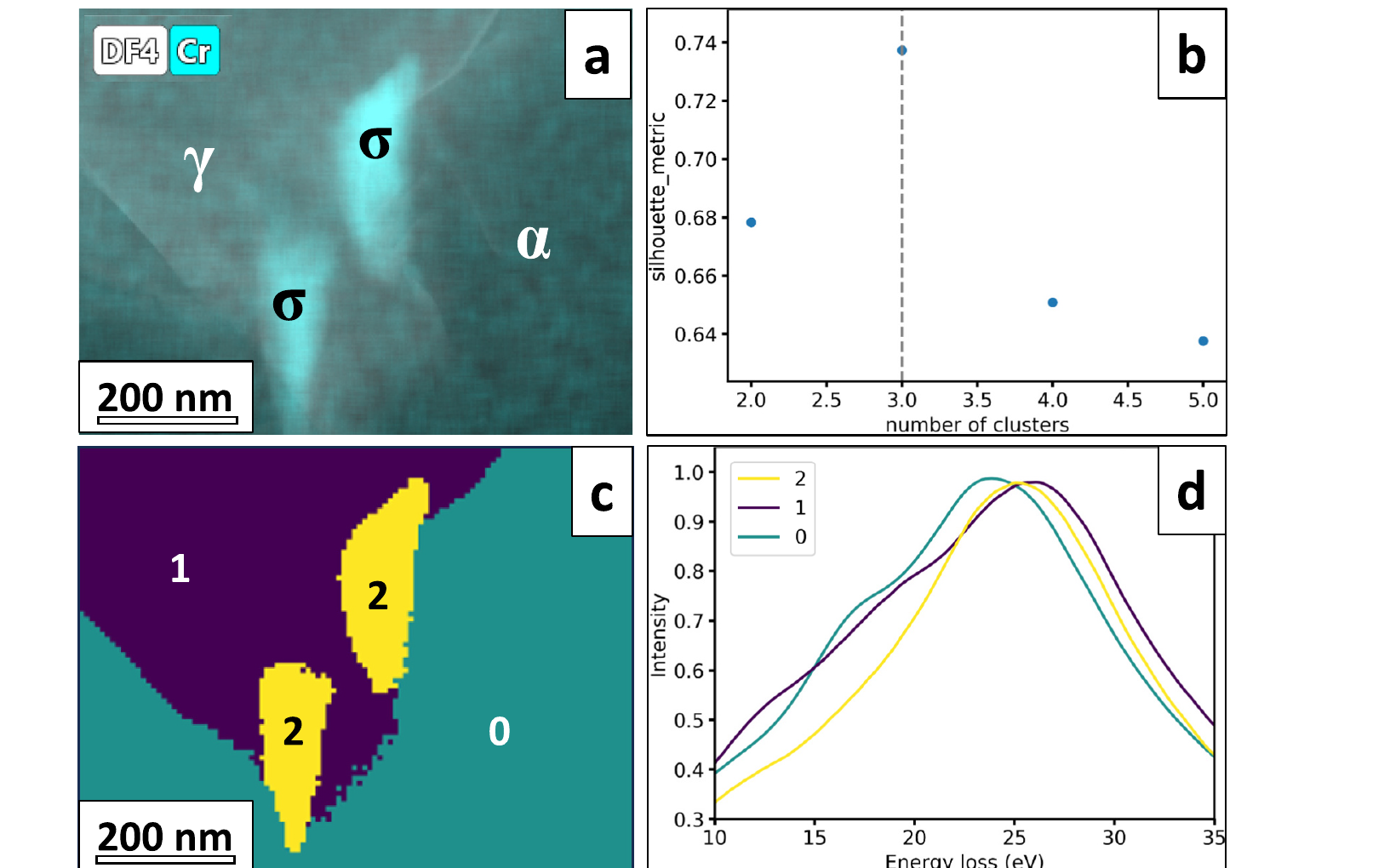
Outcome. Recovered phases: ferrite (α), austenite (γ), and σ-phase precipitates. Phase map agrees with co-acquired EDS, HAADF, and electron diffraction. Runtime: K-means ≈ 30 s vs ≈ 10 min for the same dataset using pixel-by-pixel Drude-model plasmon fitting — same answer, \(\sim 20\times\) faster, no per-fit hand-tuning.
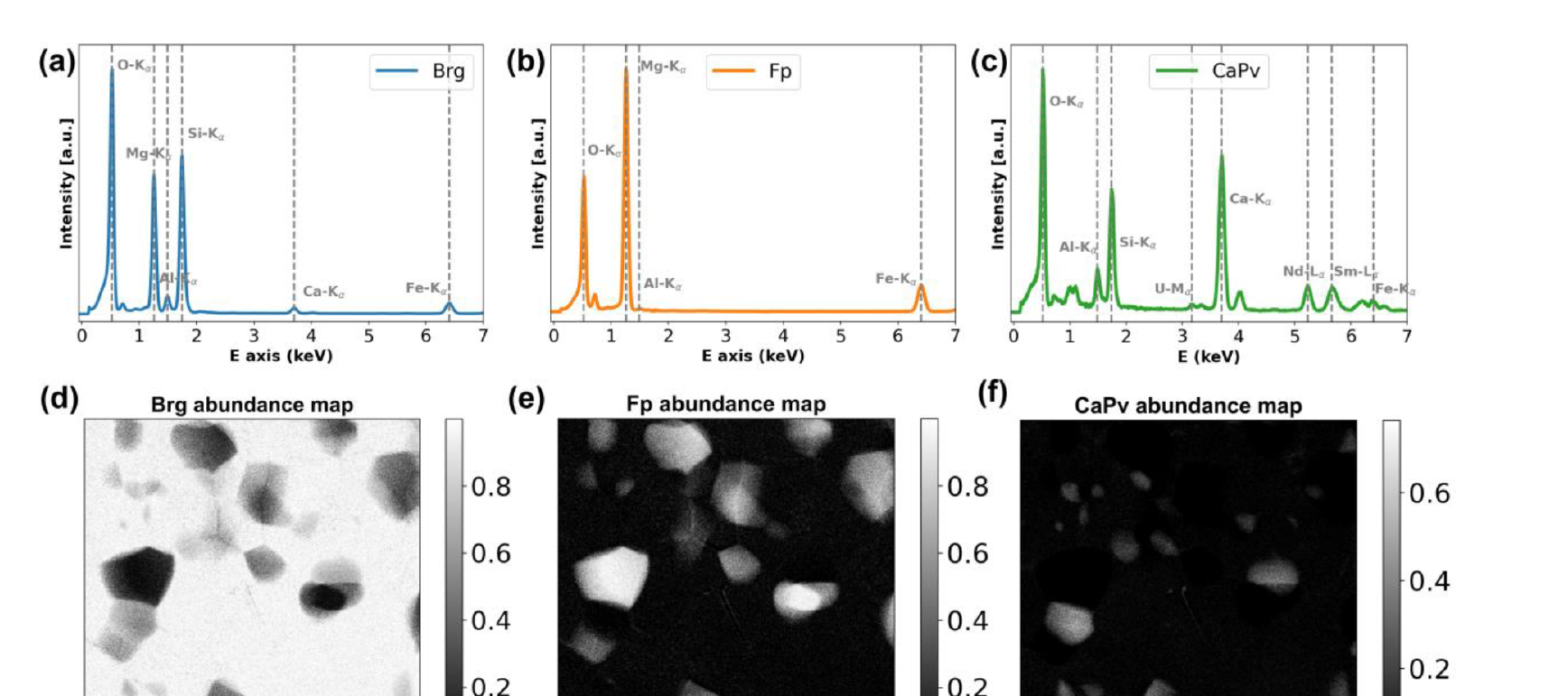
29. Worked Example: Deep-Mantle Assemblage
Setup and Challenge (Chen et al. 2024)
- Sample: diamond-anvil-cell synthesis of lower-mantle phases.
- Phases: bridgmanite (Brg), ferropericlase (Fp), Ca-perovskite (CaPv).
- Doped with trace Nd, Sm, U (\(\sim 500\) ppm).
- Problem: Phases overlap spectrally (shared lines) and spatially (sub-pixel). STEM-EDXS is too noisy per pixel for trace detection.
- Solution: NMF (HyperSpy) → 3 components → FCLS-LSMA refinement.
- Headline result: Trace Sm in Fp detected down to \(\sim 65\) ppm.
37. VAE-Regression Architecture — Frieden Templeton 2024
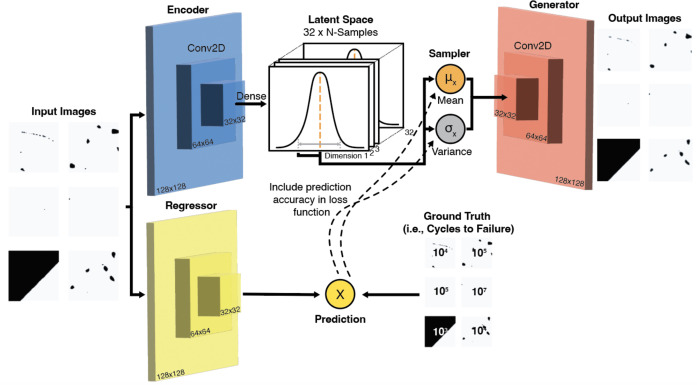
What’s new vs vanilla AE
- Encoder is variational (\(\mu_z\), \(\sigma_z\)) — smooth, regularised latent.
- A small regression head branches off the encoder and predicts cycles-to-failure.
- Loss = ELBO + prediction loss → latent is jointly shaped by reconstruction and property.
- Binarised pore masks (\(128\times 128\)) are the inputs — the AE compresses porosity geometry.
38. Latent Edits Recover Physical Porosity Descriptors
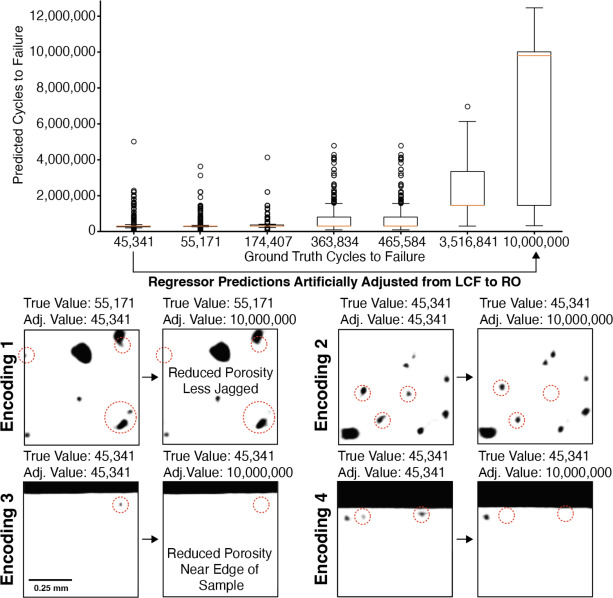
Two results in one figure
- Accuracy: the regressor separates LCF (\(\sim 10^4\) cycles) from run-out (\(10^7\)) cleanly.
- Interpretability: decoding edited latents reveals what the network thinks “long life” looks like.
What pops out is exactly what materials science predicts:
- fewer pores
- less jagged pore boundaries
- pores not near the sample edge
39. Spatial Fatigue-Life Prediction Across the Cross-Section
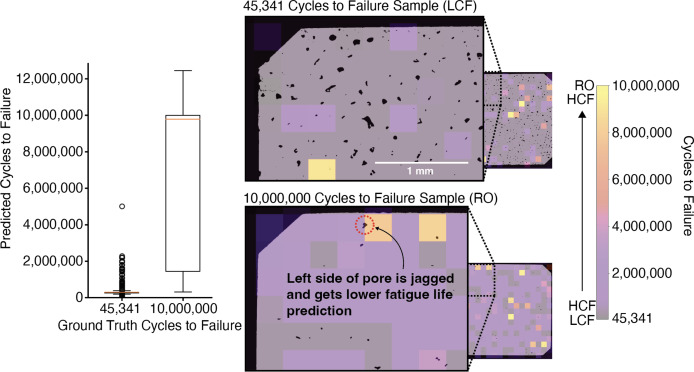
Why this is the deployment slide
- Train on patches → apply per-patch to a full cross-section → get a spatial fatigue-life map for free.
- The map highlights the worst local region — that’s the fatigue-driver.
- Same recipe as AE-based anomaly localisation we’ll meet in §E.
Operational use: a non-destructive proxy for go/no-go decisions on AM parts from a single polished cross-section.
43. Case Study — Melt-Pool Monitoring (LPBF, 1/3)
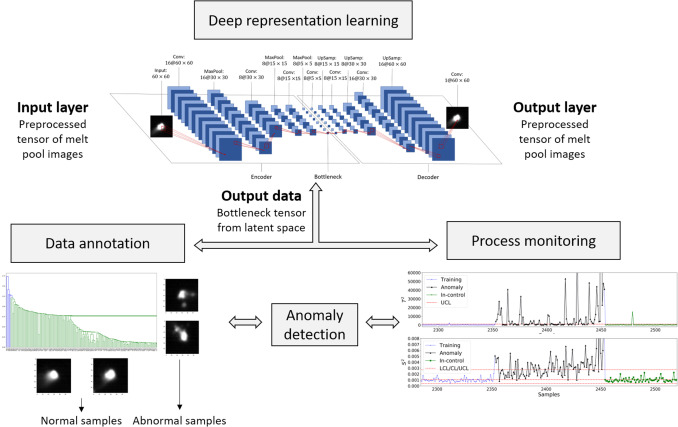
The problem
- Laser powder-bed fusion: laser fuses metal powder layer-by-layer; melt-pool dynamics drive porosity, surface quality, microstructure.
- Co-axial high-speed camera at the NIST AMMT testbed: \(\sim\) 3000 melt-pool images / layer / part, hundreds of layers per build.
- No per-frame labels — porosity ground truth comes from post-mortem CT, aggregated over volumes.
The recipe (one sentence)
Use an unsupervised AE to learn melt-pool features, then cluster the features to discover anomaly types, then chart the features to flag anomalies in real time.
44. Case Study — Melt-Pool Monitoring (LPBF, 2/3)
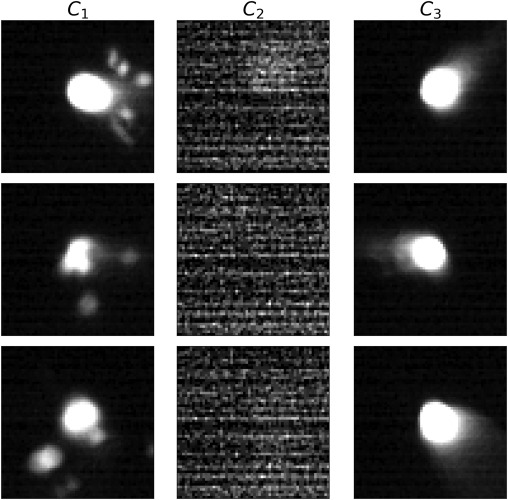
The interpretability headline
- The AE saw no labels.
- The dendrogram cut at cophenetic distance \(0.70\) separates 3 distinct populations.
- Sample images inside each cluster confirm the populations are physically meaningful:
| Cluster | What it is | Frames |
|---|---|---|
| \(C_1\) | splash / eccentric anomalies | 97 |
| \(C_2\) | sensor noise (camera glitch) | 530 |
| \(C_3\) | clean melt pool (normal) | 3138 |
Therefore: the latent has learned a taxonomy of process states without supervision.
46. Case Study — Melt-Pool Monitoring (LPBF, 3/3)
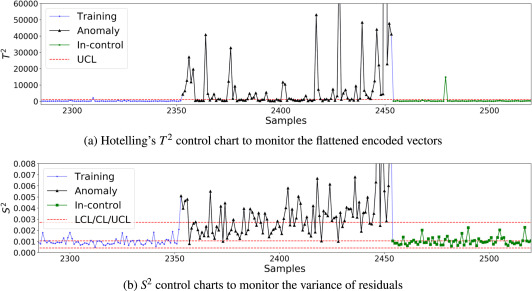
Two charts, two failure modes
- \(T^2\) on the bottleneck vector \(\to\) catches features the AE learned (shape, splash).
- \(S^2\) on the reconstruction residual \(\to\) catches images the AE can’t represent at all (sensor glitches, novel anomalies).
Bottom-line numbers
| Accuracy | Sensitivity | F\(_1\) | |
|---|---|---|---|
| Hand-crafted (NBEM) | 89.2% | 17.9% | 27.3% |
| CAE + \(T^2\)/\(S^2\) | 95.4% | 82.1% | 82.6% |
Deep features triple the F\(_1\) — and it is all because sensitivity went from 18% to 82%.